Neta Lumina



















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
- より多くのアップデートをフォローするには http://discord.com/invite/TTTGccjbEa
- モデルを試す:Huggingface Playground
- より多くのトレーニングバージョンにアクセス
- 中文モデル説明
- QQグループ:1039442542
紹介
Neta Luminaは、Neta.art ラボが開発した高品質なアニメスタイルの画像生成モデルです。
上海AI研究所のAlpha-VLLMチームが公開したオープンソースのLumina-Image-2.0を基盤として、大量の高品質アニメ画像と多言語タグデータでファインチューニングを行いました。結果として得られたこのモデルは、強力な理解・解釈能力(Gemmaテキストエンコーダーによる)を備えており、イラスト、ポスター、ストーリーボード、キャラクターデザインなどに最適です。
主な特徴
Furry、国風(伝統的中国美学)、ペットなど、多様な創作シーンに最適化されています。
人気からマニアックなテーマまで幅広いキャラクターやスタイルに対応(danbooruタグも引き続きサポート!)
自然言語理解が正確で、複雑なプロンプトにも厳密に従います。
ネイティブな多言語対応。中国語、英語、日本語を推奨します。
モデルバージョン
アルファテスト版のモデルをご希望の場合は、https://huggingface.co/neta-art/NetaLumina_Alpha からアクセスリクエストをお送りください。
Neta-lumina-v1.0
ご希望の場合は、https://huggingface.co/neta-art/Neta-Lumina からアクセスリクエストをお送りください。
- 公式リリース:全体的なパフォーマンス最適化版
Neta-lumina-beta-0624
主な目標:汎用知識とアニメスタイルの最適化
データセット:1300万枚以上のアニメスタイル画像
>46,000 A100時間
使用方法
Neta Luminaは、Lumina2 Diffusion Transformer(DiT)フレームワークに基づいて構築されています。以下の手順を厳密に従ってください。
ComfyUI
環境要件
現在、Neta LuminaはComfyUIでのみ動作します:
- 最新版のComfyUIインストール済み
- VRAM 8GB以上
ダウンロードとインストール
Civitaiで提供されているモデルは、テキストエンコーダー(te)、UNET(dit)、VAEを一つにまとめたパッケージ版であり、ComfyUIの基本ワークフローで実行可能で、テキストエンコーダーとVAEを別途ダウンロードする必要はありません。
オリジナル(コンポーネント)リリース
Neta Lumina-V1.0
Hugging Face: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Unet/neta-lumina-v1.0.safetensors
保存先:
ComfyUI/models/unet/
テキストエンコーダー(Gemma-2B)
ダウンロードリンク:https://huggingface.co/neta-art/Neta-Lumina/blob/main/Text%20Encoder/gemma_2_2b_fp16.safetensors
保存先:
ComfyUI/models/text_encoders/
VAEモデル(16チャンネルFLUX VAE)
ダウンロードリンク:https://huggingface.co/neta-art/Neta-Lumina/blob/main/VAE/ae.safetensors
保存先:
ComfyUI/models/vae/
 ワークフロー:ComfyUIでlumina_workflow.jsonを読み込んでください。
ワークフロー:ComfyUIでlumina_workflow.jsonを読み込んでください。
- UNETLoader – .pthファイルを読み込み
- VAELoader – ae.safetensorsを読み込み
- CLIPLoader – gemma_2_2b_fp16.safetensorsを読み込み
- テキストエンコーダー – ポジティブ/ネガティブプロンプトをサンプラーに接続
シンプル統合版
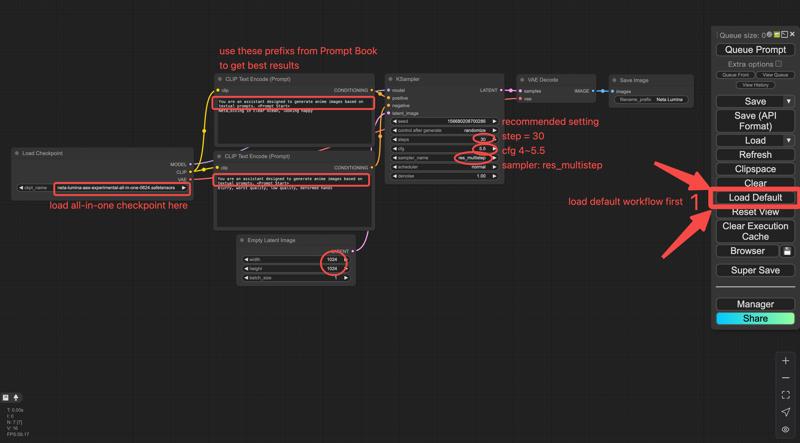
neta-lumina-v1.0-all-in-one.safetensorsをダウンロードしてください。
md5sum = dca54fef3c64e942c1a62a741c4f9d8a
ComfyUIのシンプルなチェックポイントローダーやワークフローを使用できます。
推奨設定
- サンプラー:res_multistep
- スケジューラ:linear_quadratic
- ステップ数:30
- CFG(ガイドアンス):4 – 5.5
- EmptySD3LatentImageの解像度:1024×1024、768×1532、968×1322、または1024以上
プロンプトブック
詳細なプロンプトガイド:https://civitai.com/articles/16274/neta-lumina-drawing-model-prompt-guide
コミュニティ
Discord:https://discord.com/invite/TTTGccjbEa
QQグループ:1039442542
ロードマップ
モデル
- 推論能力を向上させるための継続的なベースモデルのトレーニング
- 解剖学的正確性、背景の豊かさ、全体的な魅力性を向上させるための美的データセットの改善
- 創作のハードルを下げる、よりスマートで多機能なタグ付けツールの開発
エコシステム
LoRAトレーニングチュートリアルとコンポーネント
- 高度なコントロール/スタイル一貫性機能の開発(例:Omini Control)。協力のお願い!
ライセンスおよび免責事項
- Neta LuminaはApache License 2.0のもとでリリースされています
参加者・貢献者
Alpha-VLLMチームに、Lumina-Image-2.0のオープンソース化に対して特別な謝意を表します
パートナー
- nebulae:Civitai ・ Hugging Face
narugo1992 & deepghs:オープンデータセット、処理ツール、モデル
コミュニティ貢献者
その他の貢献者:沉迷摸鱼, poi, AshenWitch, 十分无奈, GHOSTLX, wenaka, iiiiii, 年糕特工队, 恩匹希, 奶冻, mumu, yizyin, smile, Yang, 古神, 灵之药, LyloGummy, 雪時
付録・リソース
TeaCache:https://github.com/spawner1145/CUI-Lumina2-TeaCache
高度なサンプラーおよびTeaCacheガイド(spawner作):https://docs.qq.com/doc/DZEFKb1ZrZVZiUmxw?nlc=1
Neta Lumina ComfyUIマニュアル(中国語):https://docs.qq.com/doc/DZEVQZFdtaERPdXVh
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/