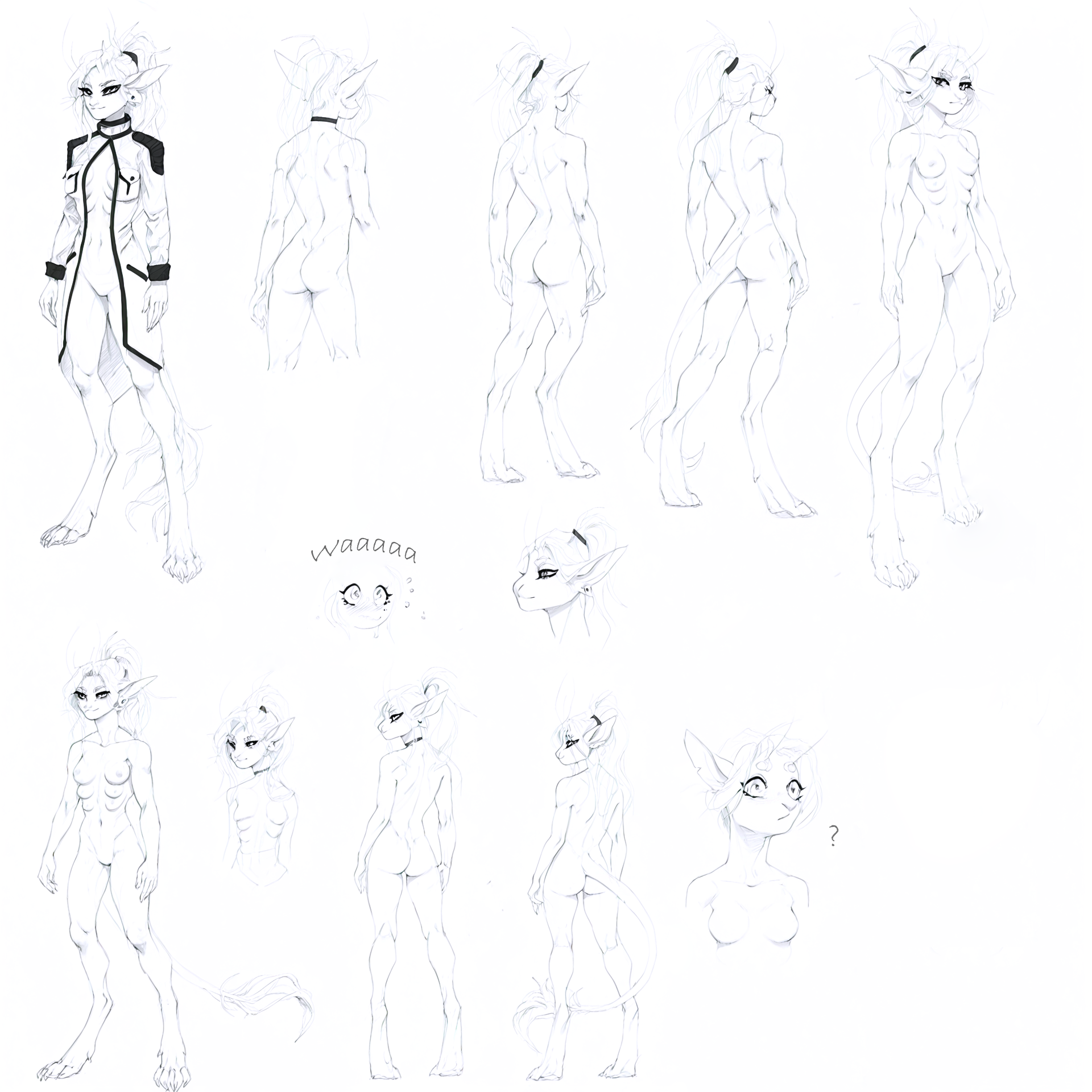
Ariral concept [High VotV lore accuracy]









詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
Concept ariral trained on 300 images
The images posted on the preview were tested on completely different checkpoints with a complex workflow (first 5) and simple (last 4, u can download and use this workflow from this last pics for comfy). There was no editing in gens, so this lora is great for high-end gens in many styles.
Use node in comfy "Lora info" if u want check fully lora tags and etc. ( https://github.com/jitcoder/lora-info ).
Note: this lora was trained on the concept, not on the style! Therefore, no style is assigned to it. You can choose it yourself depending on the model used (Note 2: each model is individual. Adjust the lora strength and its clip to achieve certain results. As a rule, 0.8 strength and clip are enough. Sometimes you can increase the clip to 1.5-1.8). This gives great flexibility for your creativity. Use tags wisely, many tests have shown the ability to work with a resolution of 1536x1536 with good quality and stably with 1024x1024.
Trigger word: Ariral.
Tags:
Furless, light skin - for more lore accuracy
Double ears - Ariral main concept
3D - 3D style of ariral
Sketch - just sketch
Meme - I think you know what it is
Observatory - Just Votv overland. Btw, not enough material for reproduce good quality.
Realistic - i use mine high quality material for that :)
Whiskers - do not forget about them!
Shrimp - oh, c'mon!
(And other: Six fingers, ponytail, meme, sticker, drawing, digital art, inflatable shrimp, 3d, yogurt and etc).
Do not forget use in negative: bad quality, inscription.
Made with love, for those who like to piss off Dr. Kel xD
In future updates I plan to combine many votv concepts in one. wip.