24s WAN-Video in 10 Minutes
详情
下载文件 (1)
关于此版本
模型描述
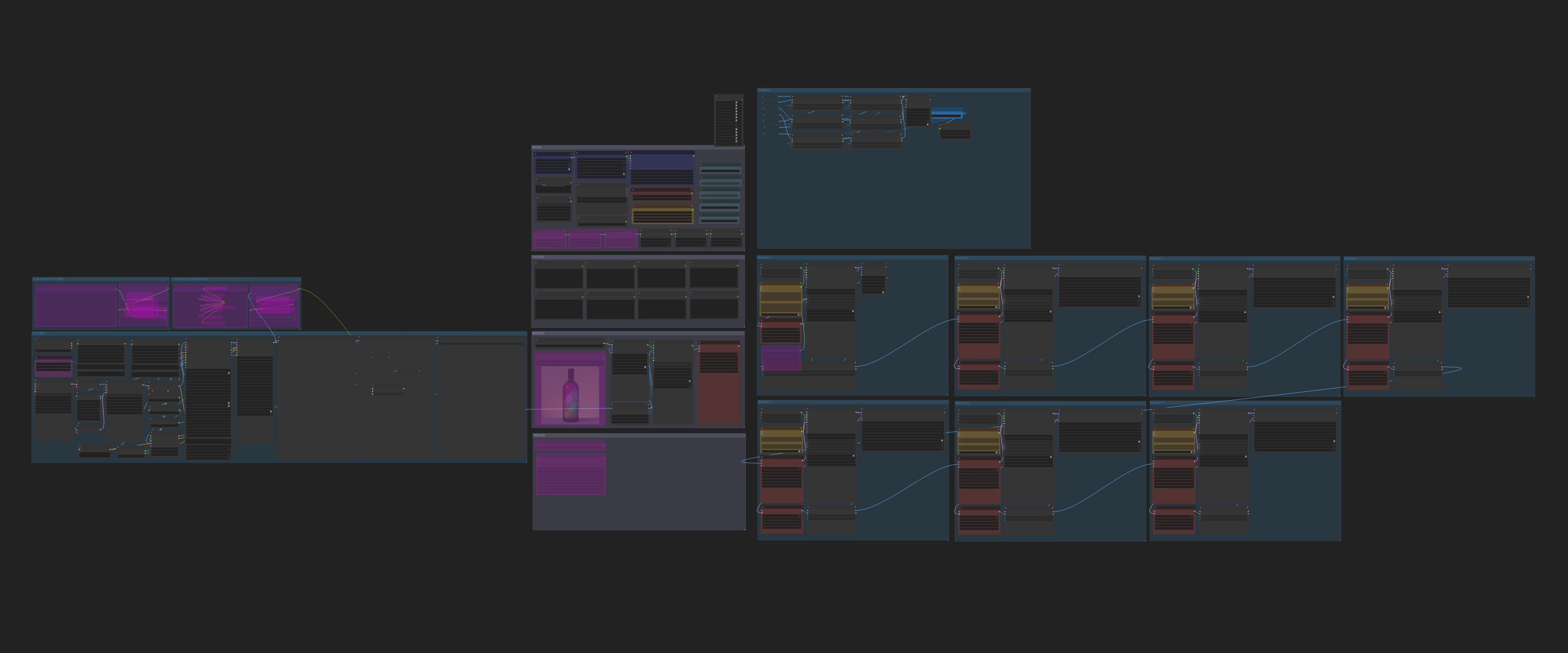
I’ve developed a workflow that allows the creation of 24-second videos in just ten minutes. The core principle is based on the Diffusion Force system using Kijai’s WanVideoWrapper nodes in combination with the Skyreel V2 DF model. The process starts with generating a high-quality image using Illustrious/SDXL (for better realism—it simply looks superior to Skyreel’s TXT2VID output). This image is then used as the initial frame fed into the generation pipeline.
A continuous scene of approximately 24 seconds is created using seven sub-prompts, each generating 97 frames. These sub-prompts can either be crafted manually or generated via an LLM. I’ve been using Ollama, but this part can easily be customized.
Acceleration is achieved through CausVid LoRA V2 with high strength, combined with a CFG step switcher: the first 3 steps run with CFG 4, followed by 7 steps at CFG 1. This keeps the rendering fast while maintaining fluid and natural movement. One caveat: the system doesn’t handle abrupt movement transitions well—something like a sprint followed by a sudden stop won’t work; the character will just keep running.
At the end, the seven segments are merged into a complete video, with overlapping frames removed to ensure continuity.
It’s a complex but reasonably tidy workflow, made manageable through the use of Anything Everywhere nodes and hidden connections. If you have any questions, feel free to ask.
One tip: LLMs aren’t perfect at prompt crafting. I’ve tested this extensively, and after several days of experimentation, I’ve gone back to writing them myself—the quality is simply better when I do it manually.