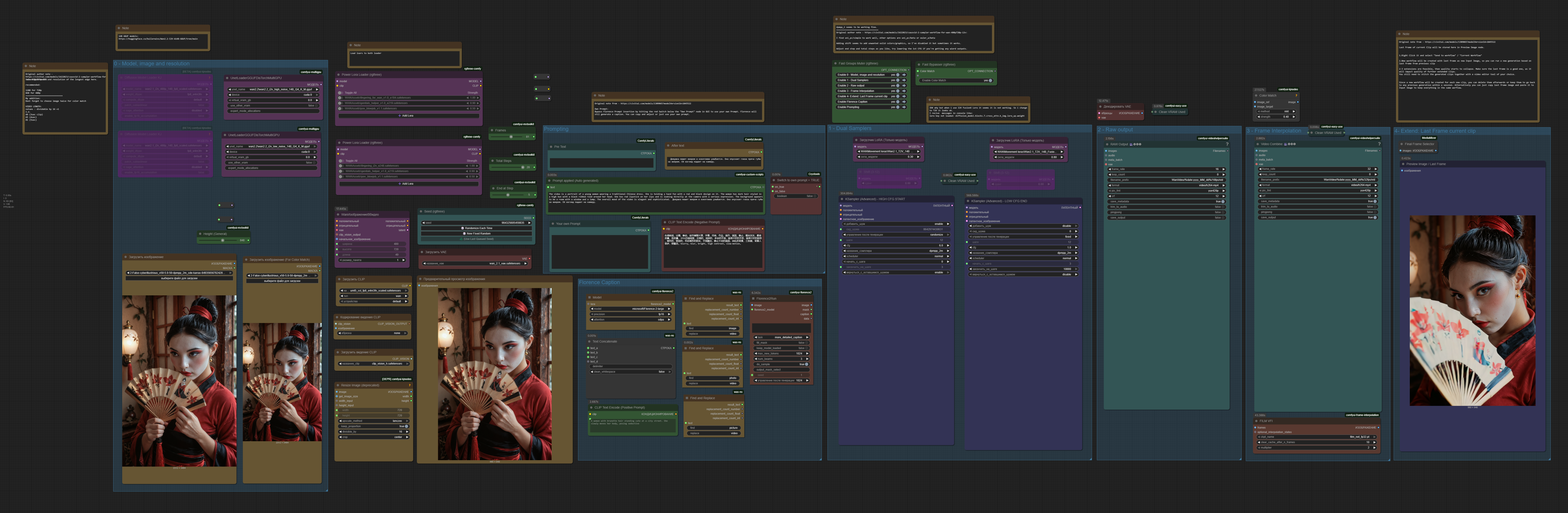
WAN 2.2/2.1 - I2V/FLF2V - 2 workflows merge, FusionX lora, 2 sampler + Florence Caption, last frame, Color match

詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
I found 2 WF that i liked and decide to put them together:
I dont know what settings is right to use (cfg/steps/ lora strength). But it seems to be working as it is for now.
I use Sage Attention - LINK
UPDATE COMFYUI BEFORE USE
==========
v.1.0 (WAN 2.2 FLF2V)
WAN 2.2 has FLF2V (First-Last Frame to Video) native capabilities. So i tried to adjust my workflow to make it work and seems it does. Hope you like it.
Enjoy.
==========
v.1.0 (WAN 2.2 I2V)
I just rearange nodes so it works with WAN 2.2 GGUF
https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
Notice that for 14B model you need both models - HIGH noise and LOW noise
==========
v.1.1 (WAN 2.1 I2V)
Instead using CausVid lora i used FusionX lora which is already have CausVid
I set lora streinght 0.4 in first Ksampler (HIGH CFG START) and 0.8 in second one (LOW CFG END)
In version 1.0 you can just change loras in Dual samplers group
==========
v.1.0 (WAN 2.1 I2V)
1 - CausVid 2 Sampler Workflow for Wan 480p/720p I2V (Main part)
I Used this lora: Wan21_CausVid_14B_T2V_lora_rank32.safetensors
2 - WAN 2.1 IMAGE to VIDEO with Caption and Postprocessing (Florence Caption, last frame, Color match)
==========
I saw suggestions that dpmpp_2m - normal works good.
There is dpmpp_2m - simple in this WF