ComfyUI beginner friendly Text-to-Image Flux GGUF Workflow (With LORAs) by SarcasticTOFU





詳細
ファイルをダウンロード
モデル説明
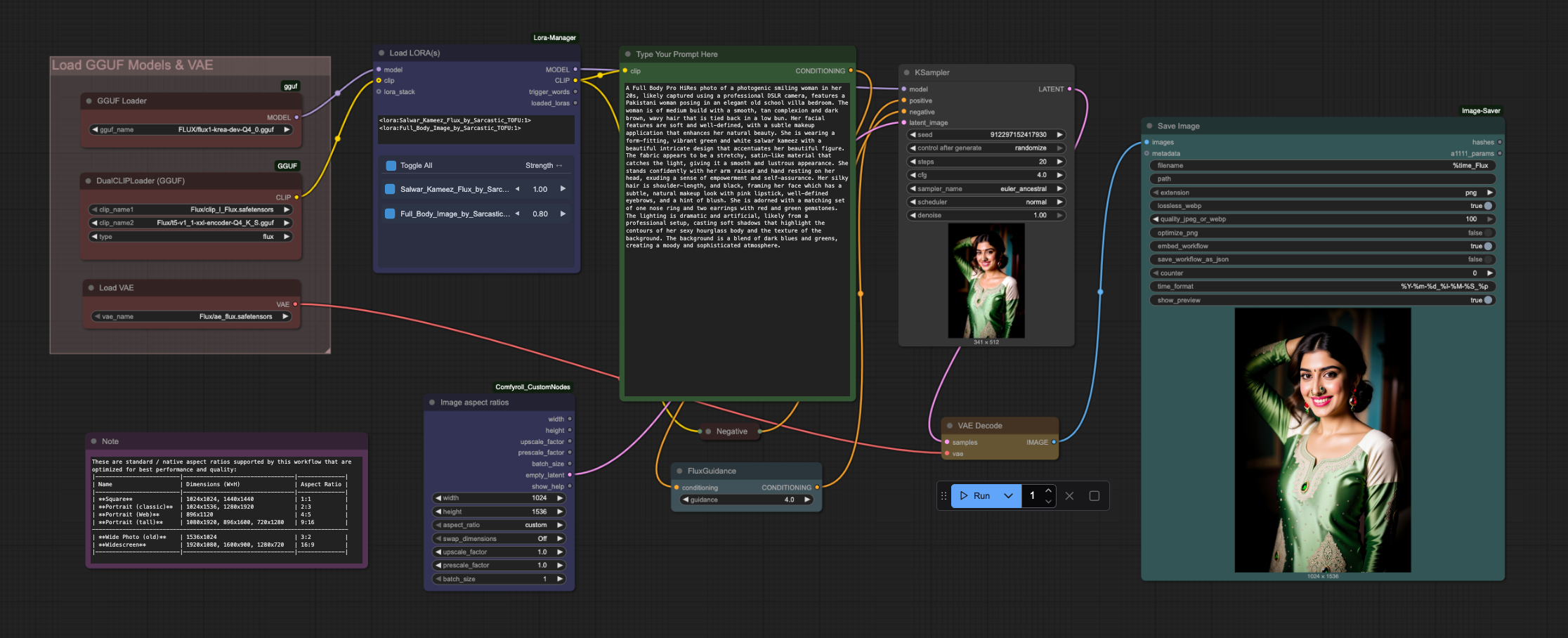
これは、単一のFlux GGUFモデルと複数のLoRAを用いた、ComfyUI初心者にも優しいシンプルなテキストから画像へのワークフローです(このワークフローは、ComfyUIのLoRA Managerプラグインが必要です)。ComfyUI ManagerとLoRA Managerプラグインの両方をインストールすることをお勧めします。これにより、チェックポイント、LoRA、その他のリソースのダウンロードと管理が容易になります。これらの2つはこのワークフローだけでなく、他のあらゆるケースでも大いに役立ちます。また、このワークフローには、必要なすべてのモデルをダウンロードするスクリプト(Windows用とLinux/Mac用)を同梱しました。これらのスクリプトによって、SD 1.5、SDXL 1.0、Flux GGUF、HiDream GGUFの主要ファイルが自動的にダウンロードされるため、すぐにAIアートの作成を始められます。ComfyUI Managerを使用してComfyUIにGGUFアドオンをインストールし、正しいファイルを正しい場所に配置してください。また、SD 1.5 + SDXL 1.0とHiDream用のその他のワークフローもご確認ください。
使用方法:
#1. まず希望のFlux GGUFモデルを選択して読み込みます。
#2. LoRA Managerから1つまたは複数の対応するLoRAを読み込みます。
#3. プロンプトを入力します(FluxのGGUFモデルはネガティブプロンプトを受け付けないため、このフィールドは空のままにしてください)。
#4. 生成する画像の枚数を選択します(「Run」ボタン横の数値を変更してください)。
#5. イメージサンプリング方法、CFG、ステップなどの設定を選択します。
#6. 最後に「Run」ボタンを押して生成します。これで完了です。
*** LoRAノードを適切に無効化してスキップできる方法を知っている場合、このワークフローはそれでも動作します。
お楽しみください!
(更新 - V2.0では、出力画像にタイムスタンプが自動付与され、追跡が非常に簡単になり、より良い出力が得られます。また、このバージョンはFlux Krea GGUFとも確認済みです。従来のダウンロードスクリプトに加えて、新しいワークフローアーカイブには、WAN 2.2、Flux Krea、HiDream Eなど、私が使用しているが、従来のスクリプトには含まれていなかった、またはHuggingFaceへのログインと利用規約の承認が必要なモデル(例:SD 3.5やその他の一部モデル)のダウンロードリンクを記載したテキストファイルも同梱しました。そちらもぜひご確認ください。)