Anime Denser ✨ Wan2.1-T2V-14B

详情
下载文件 (2)
模型描述
ℹ️ Note: the videos in the showcase post don't fully represent what this LoRA does, please pay attention to the grids in gallery instead.
Description
This is an enhancement (slider) LoRA aimed at controlling the compositional density of the environment. Detailers and tweakers have been some of my favorite types of LoRAs since the SD1.5 days, so I wanted to create something similar for a video model.
It is the first (but not the last) of the enhancement LoRAs I planned to train. It's based on a training concept I call differential LoRA, which is mostly grounded in the methodology described by ComfyTinker for this LoRA. I became interested by this approach and decided to reproduce it (though for, ehm, well, a different domain). I relied on these two notes: one, two.
The concept itself is based on a simple yet powerful idea: by training a pair of LoRAs that differ in only one specific feature, and then merging them by subtracting one LoRA from the other, it becomes possible to "distill" a distinct concept into a separate LoRA. This derived LoRA can then be used to control the presence and intensity of that feature during inference, simply by adjusting its strength. By effectively isolating a single concept, it's possible (in theory) to prevent bleeding of side-noise features, which is inevitable if you just train a generic concept LoRA on a non-isolated dataset. However, the datasets used for the two anchor LoRAs must be very similar in every way except for the target feature being trained. Otherwise, feature bleeding can also take place even after careful extraction of target concept LoRA.
It's worth noting that the method itself is apparently not brand new - it shares a lot with earlier ideas like LECO, slider LoRAs (popularized by Ostris and AI Toolkit), "Concept sliders" project, one can remember FlexWaifu, sd-webui-traintrain extension for SD web UI and some techniques from NLP (like vector arithmetic for embeddings). Not to mention the famous svd_merge_lora.py script by kohya-ss. But this is the first time I've seen it applied to training video model LoRAs (although attention mechanisms in DiTs are perhaps not so different from "classical" transformers).
(And surely this concept is not unique to ML, it mirrors numerous techniques from classical signal processing, such as phase-cancellation for audio noise reduction.)
Usage
Please bear in mind that this LoRA does not enforce an anime style on its own. However, since my interest in realistic videos lies somewhere below zero, I designed it specifically for use with 2D animation LoRAs and tested it exclusively in that context, so I named it Anime Denser accordingly. I haven’t tested it on anything else (and I don't plan to).
(That said, even though this LoRA was trained and tested only for 2D animation, it should - if I got it done right - probably work with realistic videos as well. The idea of concept isolation is meant to bypass styling differences. However, this is just an assumption on my side.)
All the clips I've published were generated using this LoRA in combination with the "vanilla" (base) Wan2.1-T2V-14B model and the Studio Ghibli LoRA. (Maybe not the best choice, since Ghibli LoRA is so strong it could function as an enhancer on its own and sometimes neglect amplifying effect of this LoRA.) And I also applied self-forcing lightx2v LoRA, otherwise, creating demonstration videos for this LoRA would've taken way more than just two days.
Workflow I use for this LoRA utilizes WanVideoWrapper, but any native workflow with LoRA loader should work too. Sample workflow can be obtained by dragging any of the videos from showcase post into ComfyUI or downloaded from here: JSON.
(Be aware that vertical grid videos do not have embedded workflow. )
The safe strength range for this LoRA is from -3 (enforces lower environmental density) to +3 (enforces higher density, more complex compositional "clutter"). For long and elaborate prompts, it's also possible to push it to +4 or -4 to compensate for text encoder influence, but going beyond that will most likely result in noisy outputs.
(After extensive testing, I noticed that at high strength, the LoRA sometimes - not always - may slightly amplify green hues, mostly in indoor environments. The reason is unclear; perhaps some feature maps were subtracted disproportionately during the subtraction process, or maybe it tries to somehow "densify" lighting.)
Dataset
For differential LoRAs, the dataset plays a crucial role. For the concept I chose (compositional density), I needed two datasets: one with highly detailed ("dense") scenes, and another with low-density ("sparse") scenes. The more these scenes have in common, the more effective the noise cancellation will be during subtraction. Ideally, I should have collected views of the same scene but with different levels of detail. At first, I planned to do this by gathering some well-detailed scenes from anime movies and running them through VACE or a simple V2V pipeline with low denoise settings.
💡 But then two things happened:
1) I realized that to train a concept like compositional density, I could just use images, and perhaps that's even better, since it also avoids possible source of temporal noise entirely! This substantially lowered the requirements for training a LoRA, giving me way more room to experiment with different settings. (I have trained at least 20 LoRAs before settling on this one...)
2) FLUX.1 Kontext [dev] came out, and this gave me a very convenient and comfy way to create the ideal dataset for my task.
So I took 100+ frames from a dataset consisting of scenes from Makoto Shinkai's films (since he's famous for creating insanely "dense" and detailed environments). Then I fed them through the Flux Kontext-powered batch workflow with the following prompt:
Reduce detalization of this scene by removing all small objects and clutter, such as food, kitchenware, books, posters, and decorations. Also simplify clothing elements and character accessories by removing intricate patterns, small items, or excessive detailing. Keep the characters and overall art style the same, but make the entire scene look very simple, less detailed, and minimalistic.This worked flawlessly. As a result, I ended up with 126 pairs of images (they are included into the training data), that shaped my dataset for both components of differential LoRA (dense "LoRA" and "sparse" LoRA). Here is example of dataset image pair:
1️⃣ Detailed, "dense" version (original frame)

2️⃣ Simplified, "sparse" version (generated by Kontext)

As for captioning, I tried a lot of different approaches:
- Short captions, different for each dataset
- Short captions, same for both datasets
- Detailed captions, different for each dataset
- Same captions, but with "detailed" added to the dense dataset's captions
- Captioning the dense dataset with "detailed image" and the sparse dataset with just "image"
- Assigning a unique ID to each pair - e.g., the sparse image would be captioned "anime_image_165656", and its dense counterpart "anime_image_165656, detailed" (the idea here was to encapsulate the scene content in a text label to facilitate subtraction of "detailness" concept, but it did not work)
- Using empty captions 🥳
And (obviously) empty captions turned out to be the most effective.
Well, it makes some sense. If you take a look at the following image, specifically its right part, in Wan transformer, unlike MMDiT, self and cross attention parts are not interleaved.
(this image was once posted by Kijai on Banodoco, here is source)
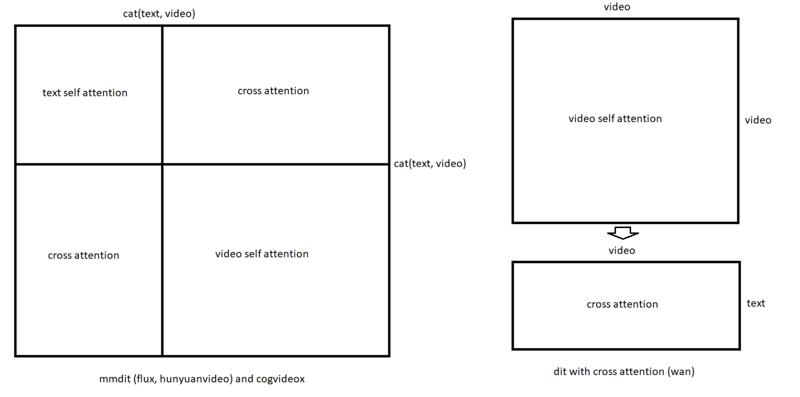
Since text captions might introduce cross-attention noise to LoRA weights from text encoder alignment mechanism, completely ignoring it via empty captions may be the way to unconditionally introduce minimal level of noise. And since in Wan cross-attention is separate from the "core" self-attention, using empty captions effectively "turns off" the text conditioning without disrupting other blocks.
(Sorry if that makes no sense, I was trying to find an explanation and this is my best guess, although based only by empirical experience and help of Gemini Pro.)
Training
As usually, for training I used Musubi Tuner. (Windows 11, RTX 3090, 64 Gb RAM.)
Thanks to opportunity to train on images, training a single component of the differential LoRA was extremely fast. And I could also train at 192p, since I didn't need to teach the details themselves, just their presence to capture the difference between "dense" and "sparse". In fact, I actually wanted to avoid learning the concrete details, the goal was to isolate the abstract contrast, not the content difference itself.
As a result, I could usually a pair of composite LoRAs in just 2-3 hours, which gave me a lot of room to experiment with various settings. I tried several training configurations and ended up choosing the Lion optimizer with lr=2e-5, constant_with_warmup scheduler with 50 warmup_steps and LoRA rank 16 for 5000 steps, batch_size 1. (I included all config files into training data, so won't elaborate on this here).
Honestly, I don't think these settings mattered that much. I experimented with several optimizers, step counts, learning rates, scheduler parameters, and I couldn't really conclude any of this choice made a major difference. And, just to mention, before diving into training such an abstract concept as "clutterness", I practiced by creating a simple daytime LoRA: 20 images of noonday scenes and their nighttime counterparts, generated with Kontext. I trained it several times using various settings. With only 40 images in a shared dataset, it never took more than an hour. The settings I found most effective in this experiment are the ones I later used for training Anime Denser.
So, in my opinion, it's the "purity" of the dataset and the parameters passed to the differentiation script (more on that later 👇) that matter most.
The sample images I got during training for both component LoRAs looked pretty bad. And that was good, because that was exactly what I expected (imagine training on still images at 192x192 resolution and expecting clean results!) But the best part was that both sets of samples looked similarly bad, with a important difference: the dense LoRA had clearly memorized how to inject compositional clutter, while the sparse LoRA had learned to reproduce empty, sterile environments. So, I could reasonably expect that all those "context-aware" features would be effectively cancelled out during subtraction, leaving only the concept of environmental density and detailness reside in the final LoRA. At that point, I knew it was time to cook it 👨🍳.
Differential LoRA
After I got the two LoRAs, I had to subtract one LoRA from the other. Thankfully, ComfyTinker shared detailed instructions on how to do this (I linked them earlier), though not the actual code. But as a software developer with over 13 years of experience, I had no fear and knew what to do. I opened Cursor, pasted the instructions, and told it to generate a script based on them.
From there, I experimented with various enhancements of the initial script (I won't talk about them here, because its still WIP) - like targeting specific blocks by name patterns and/or numerical indices, auto-calculating alpha values based on target norms, filtering which layers participate in the merge (using magnitude thresholds), auto-threshold calculation using percentile-based filtering, finding the most distinct layers by calculating difference magnitudes, adding fast randomized SVD for rapid prototyping, adding block structure analysis for debugging, and options to either nullify or completely exclude non-targeted layers from the output. I'll probably keep modifying and enhancing this script for future differential LoRA projects, but even in its current form, it does the job. (And I've included script for generating differential LoRA into the archive with the training data as well.)
I won't blow up size of this text with detailed instructions on how to use it (unless asked in comments), but, essentially, it just creates a new LoRA by computing the difference between two input LoRAs. Here's the exact command I used to create the differential LoRA:
python differential_lora.py ^
--lora_a animedenser_pos_wan14b.safetensors ^
--lora_b animedenser_neg_wan14b.safetensors ^
--target_blocks attn ^
--output animedenser_v01rc.safetensors ^
--rank 4 ^
--dtype float32 ^
--alpha 1.0 ^
--device cuda ^
--analyze_blocks ^
--exclude_non_targeted(I should acknowledge that I tried a lot of parameters without clean understanding of how they influence the process, and there are probably more effective ways to create merged LoRA.)
For merge I targeted only attention layers (--target_blocks attn). So the resulting LoRA only affects attention mechanisms in the model, all other blocks are excluded from the target LoRA (not nullified, just excluded; if I omitted --exclude_non_targeted, then they would be nullified, which is worse in terms of interfering with base model's weights), and every other layer (feedforward, normalization, etc.) will use the base model's weights unchanged. I decided attention (specifically, cross-attention) blocks are the best place to put compositional density into. And seems like it worked🤷♂️
The alpha value I chose was empirical, it's not necessarily optimal. (I tried to implement automatic calculation for the "optimal" alpha, but it does not works as expected, instead decreasing output LoRA's effect.)
If you're desperate enough to use this script, be aware that SVD is a very expensive operation. Even on an RTX 3090, merging two rank 16 component LoRAs into rank 4 differential LoRA took me about one hour. For faster testing, you can use the script with the --fast_svd flag. This uses a lossy approximation of the singular value decomposition, allowing you to generate a merged LoRA in about 5-10 seconds to estimate its effectiveness. If the outcome looks promising, you can then run the full SVD decomposition to get optimal merge.
Conclusion
This LoRA might not be practical for every production use case (for such a powerful model as WanVideo is might be probably more effective simply to request "clutterness" or "emptiness" in a prompt), but I enjoyed the results I got, and while I wouldn't call this LoRA important because of its utility, it proves that the concept and method work, even for such a abstract and "distributed" notion as clutter.
I wanted to share the results in case someone finds them useful and wants to build on this method. I hope more people will embrace this methodology and evolve it further. It's a comparatively cheap and reliable way to build sliders for video models, and I believe it has a lot of potential. (Personally, I'm looking forward to training something like a motion enhancer, a deblurrer, an actual detailer and a few crazier ideas.)
💾 I'm including all the training materials (datasets, configs, scripts) needed to reproduce this LoRA. There's still a lot to explore in this area, and my scripts and methods are far from the perfection and precision that could be achieved. For example, it might be beneficial to train such LoRAs on specific blocks or to skip certain blocks during merging. I experimented with merging only the initial blocks (0–10), the middle blocks, or both, hoping to improve effectiveness, but I couldn't find a clear advantage. I even tried creating a simple node to switch Wan DiT blocks on or off because I wanted to understand which blocks are responsible for what. (In HV training, if I am not mistaken, it was common to skip double blocks when training LoRAs on images.) Unfortunately, this didn't help me identify the most effective strategy. As you can see from the command I used for merging, I focused only on attention blocks, assuming they're responsible for the unconditional (prompt-independent) "shaping” of the scene. This approach seemed to work better than merging across all blocks.
🤔 Also I think that training on still images, although proves its effectiveness (at least computationally), still may introduce implicit noise that can decrease motion capabilities of the model (I hope soon to figure this out because plan going to train next differential LoRAs on videos.)
🚀 Also worth mentioning is Flux Kontext, which turned out to be a lifesaver for me. As everyone already knows, it allows to build datasets in an "inverse" manner, by inputting a source image that Kontext has no idea how to generate, and transforming it into something it does understand - easily and effectively. I think it could find even more uses beyond just image training. Perhaps some new and innovative ways to harness its power are just around the corner.
Acknowledgements
🏆 As I mentioned at the beginning, this method was originally described by ComfyTinker, so I'm very grateful for him sharing it with the community. Without his notes, I probably wouldn't have been able to reproduce it, or at least it would have taken magnitudes more time.
🏆 Huge thanks also to the authors of self forcing training method, that made it possible to arise LightX2V project with their Wan distilled model, to blyss for extracting the Wan Accelerator LoRA from it, comfyanonymous for creating ComfyUI and last but not least, to Kijai for his amazing work on WanVideoWrapper.
🏆 Finally, cheers to all banodocians, who share valuable information daily in the Wan-related (and other) channels. Their insights and ideas were a big help and contributed greatly to creation of this LoRA.