WAN 2.2 IMAGE to VIDEO with Caption and Postprocessing

Details
Download Files (1)
About this version
Model description
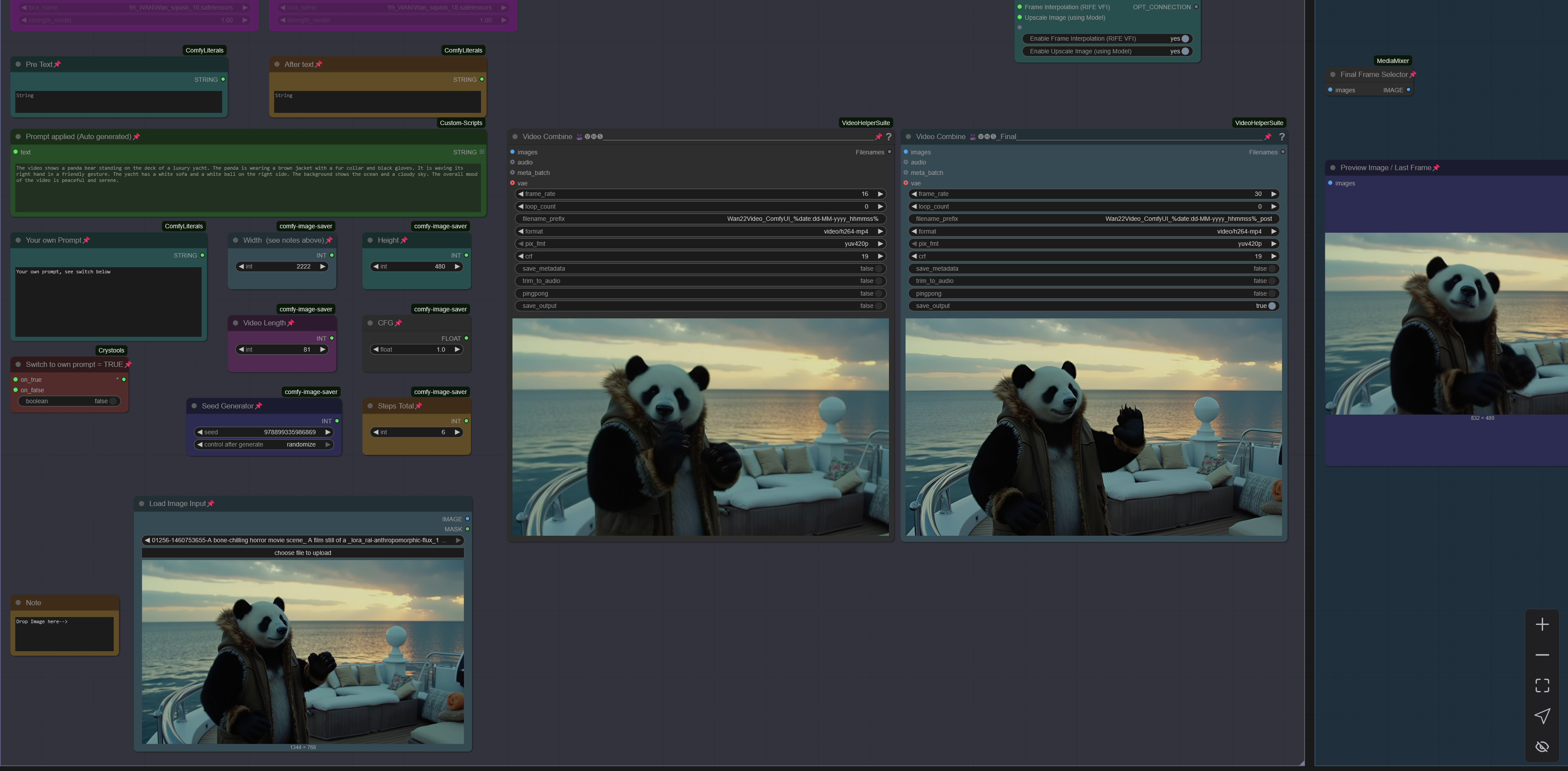
Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with 480p - 720p resolution.
Wan2.2 14B Image to Video MultiClip Version re-work with LongLook
create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
using LongLook nodes for improved processing: https://github.com/shootthesound/comfyUI-LongLook
Increase overall quality for fast pace or complex motion clips
Uses chunk of last frames for better continuity when extending
Can pack more motion within a clip with 1 parameter, reduce slomo
process with improved Wan 2.2 models, Smoothmix with baked in LightX and other (including NSFW) Loras: https://huggingface.co/Bedovyy/smoothMixWan22-I2V-GGUF/tree/main
removed some custom nodes and replaced them with comfy core nodes where possible
Normal Version with own prompts, ideal to use for NSFW or specific clips with Loras.
Ollama Version, using an uncensored Qwen LLM to autocreate prompts for each clip sequence.
Ollama model (reads prompt only, fast): https://ollama.com/goonsai/josiefied-qwen2.5-7b-abliterated-v2
alternative model with Vision (reads input image+prompt, slower, it can do reasoning by enabling "think" in Ollama generate node): https://ollama.com/huihui_ai/qwen3-vl-abliterated
About below Versions: There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM.
Version use cases:
Create longer NSFW or specific clips with Loras and own prompts => MultiClip (14B) Normal
Create longer clips with autoprompts => MultiClip (14B) LTXPE or MultiClip_LTXPE+*
Generate short 5sec clips with own prompts or autoprompts => V1.0 (14B model) Florence or LTXPE*
*LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
https://civitai.com/models/1823416?commentId=1017869&dialog=commentThread
MultiClip LTXPE PLUS: Wan 2.2. 14B I2V Version based on below MultiClip workflow with improved LTX Prompt Enhancer (LTXPE) features (see notes in workflow). You may want to try below MultiClip workflow first.
Workflow enhances the LTXPE features to give more control over the prompt generation, it uses an uncensored language model, the video generation part is identical to below version. More Info: https://civitai.com/models/1823416?modelVersionId=2303138&dialog=commentThread&commentId=972440
MultiClip: Wan 2.2. 14B I2V Version supporting LightX2V Wan 2.2. Loras to create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
supporting new Wan 2.2. LightX2v Loras for low steps
Single Clip Versions included, which correspond to below V1.0 Workflow with additional Lora loader for "old" Wan 2.1. LightX2v Lora.
Since Wan 2.2 uses 2 models, the workflow gets complex. Still recommend to check the Wan 2.1 MultiClip Version, which is much leaner and has a rich selection of Loras. It can be found here: https://civitai.com/models/1309065?modelVersionId=1998473
V1.0 WAN 2.2. 14B Image to Video workflow with LightX2v I2V Wan 2.2 Lora support for low steps (4-8 steps)
Wan 2.2. uses 2 models to process a clip. A High Noise and a Low Noise model, processed in sequence.
compatible with LightX2v Loras to process clips fast with low steps.
Models can be donwloaded here:
Vanilla Wan2.2 Models (Low & High Noise required, pick the ones matching your Vram): https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
orig. LightX2v Loras for Wan 2.2. (I2v, Hi and Lo): https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22-Lightning/old
Oct.14th 25: 2 New LightX Highnoise Loras (MoE and 1030) are out , try with strength > 1.5, 7 steps, SD3 shift =5.0. replace High Noise Lora:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
Oct. 22nd 25: another LightX Lora has just been released (named 1022), recommended:
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
Vae (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
Alternative / newer Wan 2.2. 14B model merges:
WAN 2.2. I2V 5B Model (GGUF) workflow with Florence or LTXPE auto caption
lower quality than 14B model
720p @ 24 frames
with FastWan Lora use CFG of 1 and 4-5 Steps, place a LoraLoader node after Unet Loader to inject Lora
FastWan Lora: https://huggingface.co/Kijai/WanVideo_comfy/tree/main/FastWan
Model (GGUF, pick model matching your Vram): https://huggingface.co/QuantStack/Wan2.2-TI2V-5B-GGUF/tree/main
VAE : https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1) :https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Vae -> models/vae
Tips (for 14b Model):
Wan 2.2. I2V Prompting Tips: https://civitai.com/models/1823416?modelVersionId=2063446&dialog=commentThread&commentId=890880
What GGUF Model to download? I usually go for a model with around 10gb of size with my 16gb Vram/64gb Ram. (i.e. "...Q4_K_M.gguf" model)
Play with LightX Lora strength (ca.1.5) to increase motion/reduce slomo
If you face issues with LTXPE see this thread: https://civitai.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer