Yellow Pearl AND Blue Pearl (Steven Universe)





















詳細
ファイルをダウンロード
モデル説明
これは、主にトレーニングがどのように機能するかを分析するために設計された実験的なモデルです。
目的: 言葉を使ったトレーニングがどのように機能するかを理解すること。なぜこれが重要なのか?私は常にトリガー単語のみでトレーニングしています。
あなたが本当に知っておくべきこと:
このモデルは「ブルーパール」と「イエローパール」の2つのキャラクターを認識しています。私はこのモデルをこれらの2つの単語のみでトレーニングしました。
データセットには、それぞれ単独で、そして一緒に描かれた画像が含まれていました。何らかの理由で、モデルは時々ランダムに、両方のキャラクターの要素を1つの画像に混ぜてしまいます。たとえば、ブルーパールを表示したいのに、彼女がイエローパールの衣装を着てしまったり、イエローパールが背景に現れたりすることがあります。また、「2girls」というタグを使ったタスクでも、なぜかイエローパールが背景に出現することがありました。これは言葉で修正できるでしょうか?おそらく可能です。しかし、ネガティブプロンプトを使ったテストはあまり行っていません。
自分で分析できるように、データセットをダウンロード可能にしておきます。
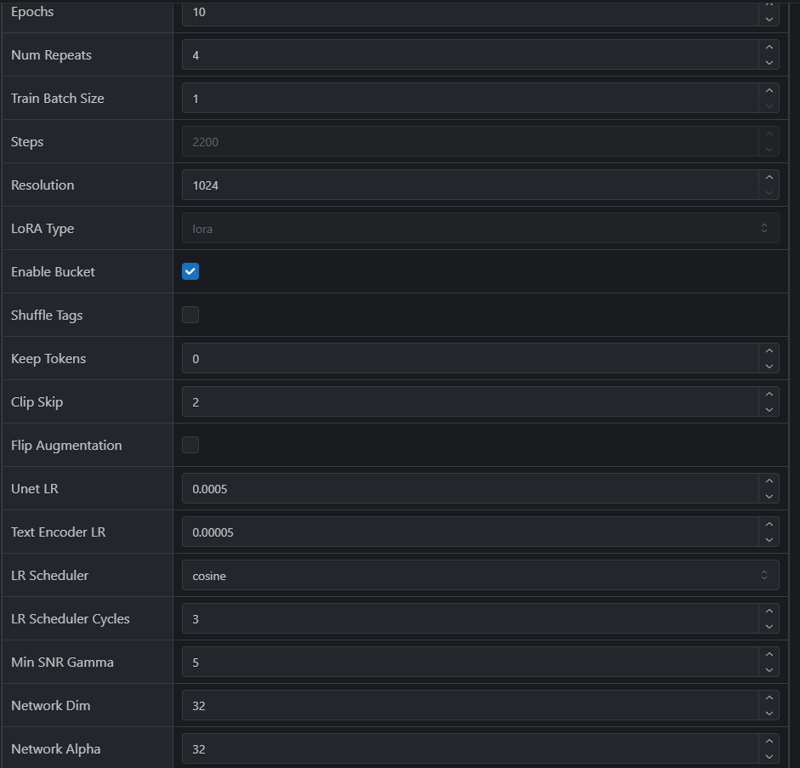
このモデルがCivitAIでどのようにトレーニングされたかのスクリーンショットを残しておきます。もし1人または複数のキャラクターでモデルをトレーニングしたい場合、非常に役立つでしょう。
次に、トレーニングの経緯と、私が何をすべきだったかについて語ります。この自己分析は、あなたがモデルをトレーニングしたい場合にも役立つかもしれません。
私はモデルにキャラクターの名前だけを指定し、独自の衣装については何も示していません。したがって、衣装を指定しなければ、衣装はランダムに選ばれると考えてください。技術的には、トレーニングセットに学校の制服が含まれていたため、制服が出現する可能性もありますが、ほとんどの場合、アニメの伝統的な衣装が表示されます。もし伝統的な衣装について少なくとも1〜2つのタグを追加していれば、トレーニングははるかに制御しやすかったでしょう。しかし、その場合、それらの単語を明示的に記述する必要があったでしょう。なぜなら、プロンプトにそれらが含まれていないことが、逆に不利に働く可能性があったからです。しかし、おそらく私たちはその答えを知ることはないでしょう。なぜなら、このバージョンで十分満足しているからです。もう500〜700のブズをトレーニングに費やす気はまったくありません。
正直、私はかなり多くのモデルをトレーニングしてきました。しかし、そのほとんどを公開していません。なぜなら、それらには大半の人が対処したくないような繊細なニュアンスが含まれているからです。
このモデルには欠点がありますが、最も興味深い部分——スタイルの多様性——はよく処理しています。比較的大きなデータセットでトレーニングしたため、ほとんどすべての画像が異なるスタイルを持っていたという幸運に恵まれ、モデルが1つのスタイルに固定されるのを防ぐことができました。モデルは類似性を記憶します。もし10回中5回同じスタイルが出現すれば、美しいLoRAを簡単に組み込むのは難しくなるかもしれません。
最後に、思いつくままにいくつかのヒントを紹介します:
モデルに、すでに知っていること以外を教えることです。モデルはすでに「マント」が何であるか、風に揺れる様子も知っていますが、たとえば、あなたのキャラクターの角は非常に独特かもしれません。その場合は明示的に指定すべきです。モデルは見つけたすべてのものを記憶します。私の親愛なるAlmazが残してくれた例がとても気に入りました。その男性の名前は文字通り「Almaz」です。これは強力です。しかし、とにかく。もし1,000枚のマッチ箱の画像をトレーニングして、その中ですべてのマッチが多色だったとしても、ただ1枚の画像に1本だけ黒いマッチが含まれていれば、モデルはその黒いマッチを記憶します。もしあなたが色をラベル付けしなければ、モデルは黒いマッチをずっと生成し続けます。なぜなら、モデルはすべてを記憶するからです。特にキャラクターを生成する場合、アーチファクトを含めてトレーニングするのは神を恐れなければならないほど危険です。モデルはそのアーチファクトを常に記憶し、描き続けます。時には、データセットを見直すことが必要です。あるときは、品質が低かったために、私はアイデア自体を断念したこともあります。ちなみに、品質は時に重要です。場合によっては、画像をアップスケールすることも意味があります。しかし、多くの要因を考慮すべきです。たとえば、画像の解像度について、トレーニング時に指定された解像度が何を意味するか考えたことはありますか?事実:指定サイズを超える画像は圧縮されます。トレーニング中に画像を圧縮する方法をご存知ですか?私にはまったく想像がつきません。したがって、心配な場合は、すべてを事前に自分で圧縮するのがよいでしょう。しかし、何もわからない場合は、そのまま放置しても問題ありません。トレーニングがより大きく、自分にとって本当に重要なものになったとき、あなたは自分の過ちを分析し始めるでしょう。
トレーニングにおいて理解すべき多くのパラメータについて語ることはできますが、おそらくそれについては別のセクションを設けるべきでしょう。
あ、まったく忘れていました——キャラクターの特徴の1つは、胸につけられた宝石です。これをトレーニングに含めていれば、より制御しやすくなり、さらに効果的だったかもしれません。しかし、私は面倒くさがりました。:y
言うまでもなく、ニューラルネットワークは、あなたが何もしなくてもキャラクターを脱衣させる方法をすでに知っています。あなたの画像に胎児のあざのような独特な要素がなければ、裸の胸を描く方法を教える必要はありません。同じ結果を得るには、同じプロンプトを使用する必要があります——つまり、すべての独自の特徴が生成時のトークンに含まれているということです。そしてトークンは通常無限ではありません。あるいは、100〜200語で生成しても問題ないのかもしれませんが、私は何かを見落としているかもしれません。