Captioning With Extra Steps - Workflow (ComfyUI)


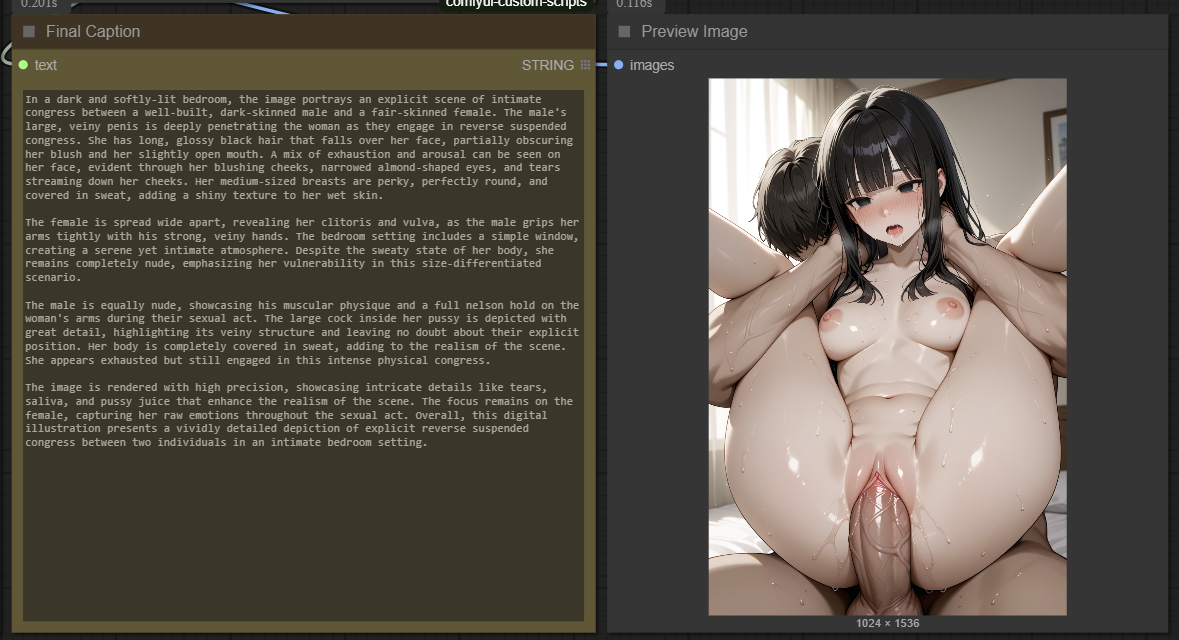
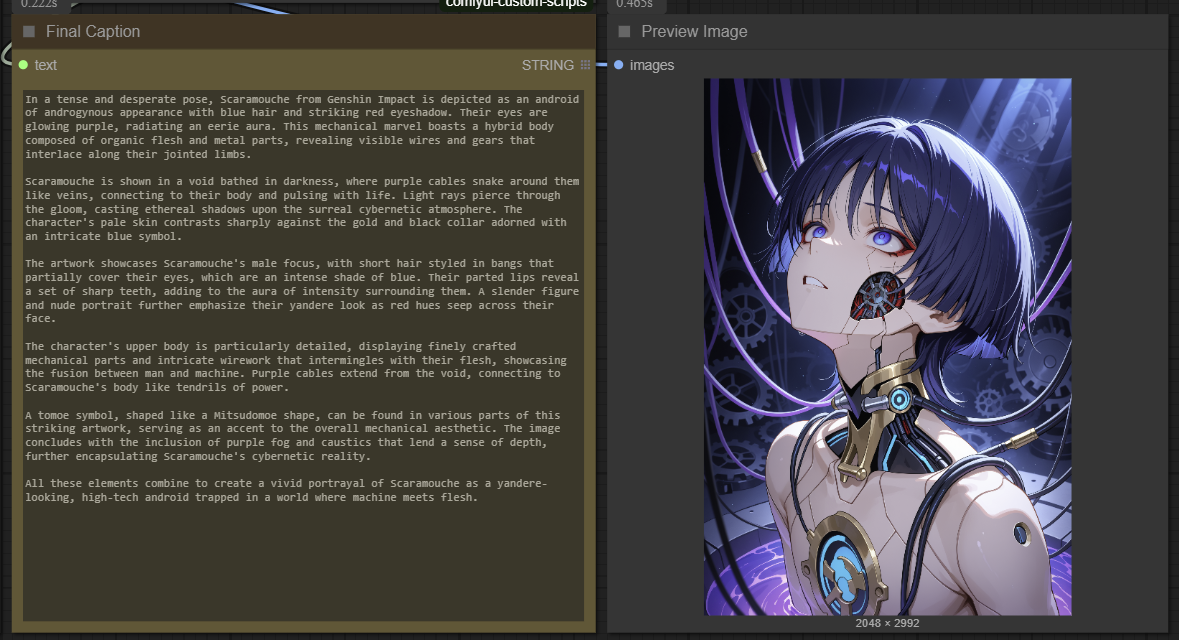
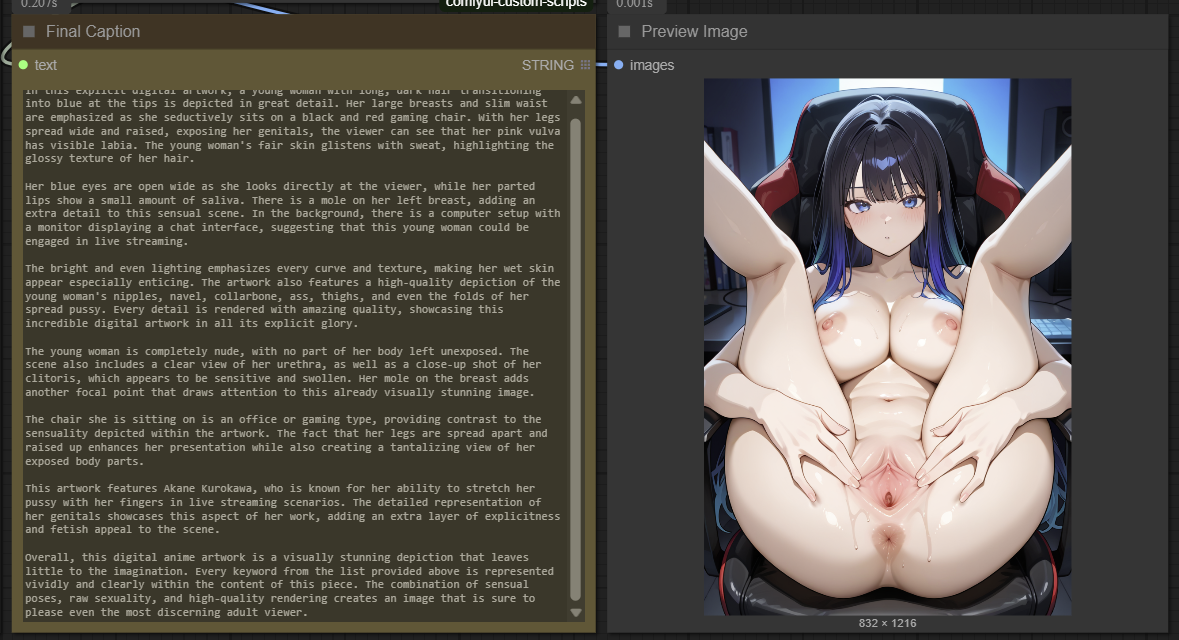
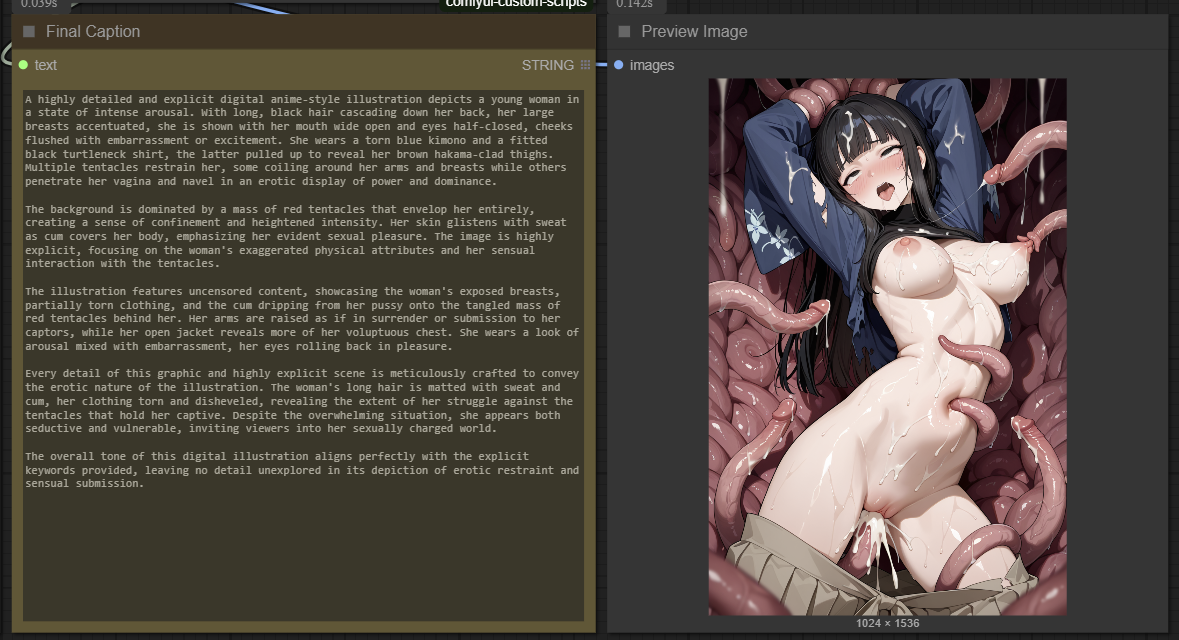
Details
Download Files (1)
Model description

 📌 Optimal Setup Guidelines
📌 Optimal Setup Guidelines
📝Overview
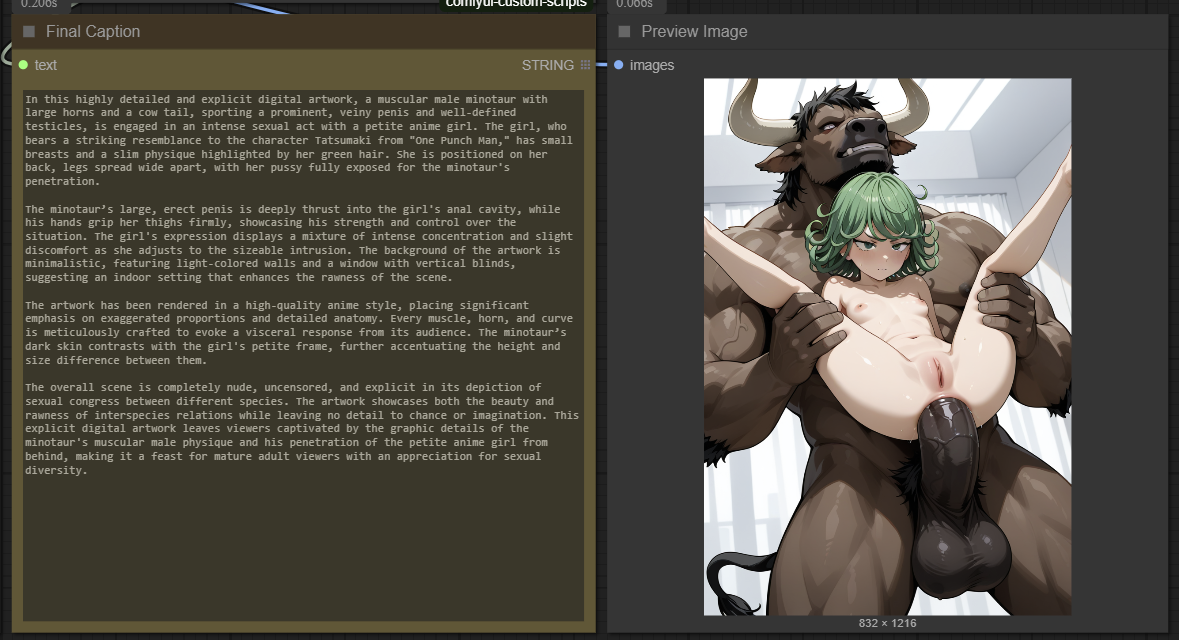
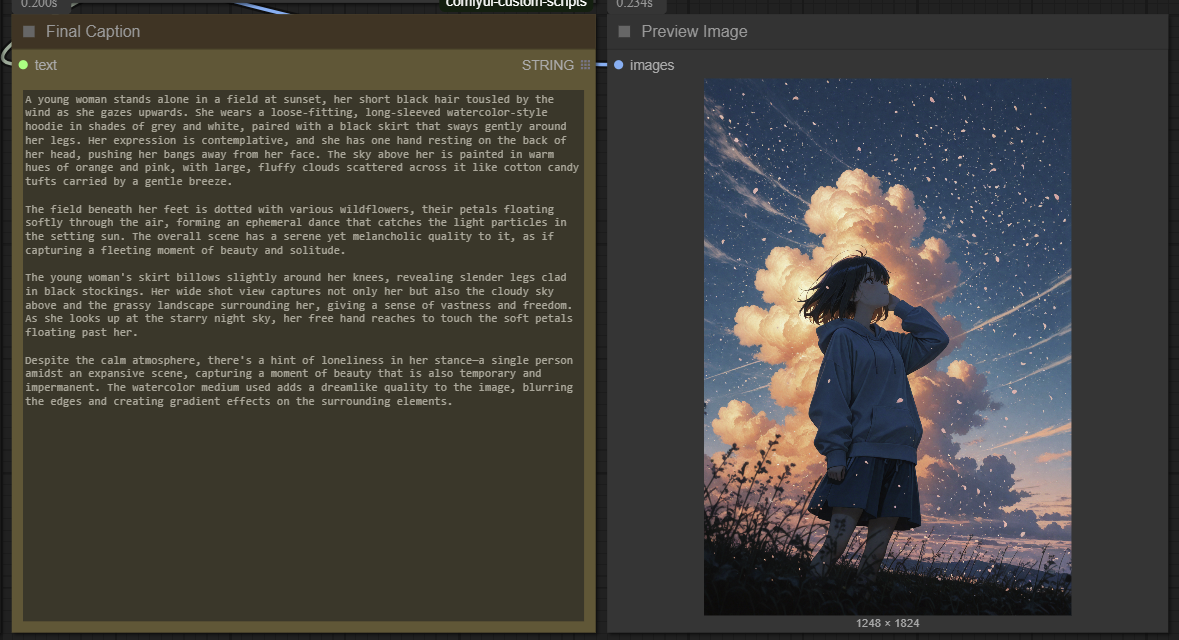
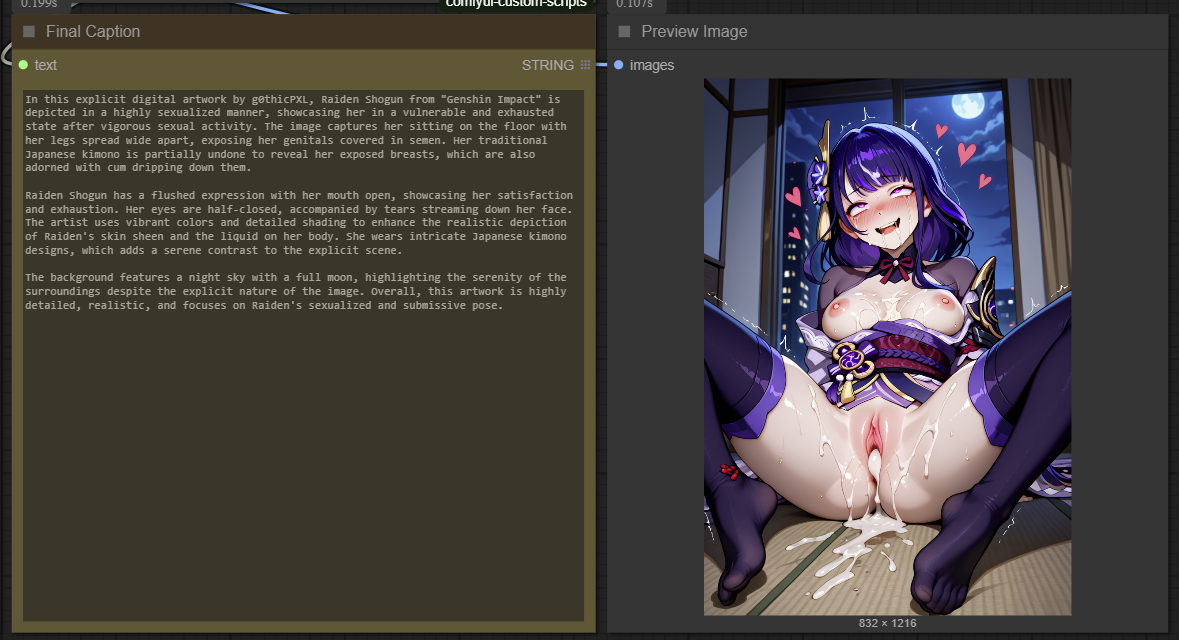
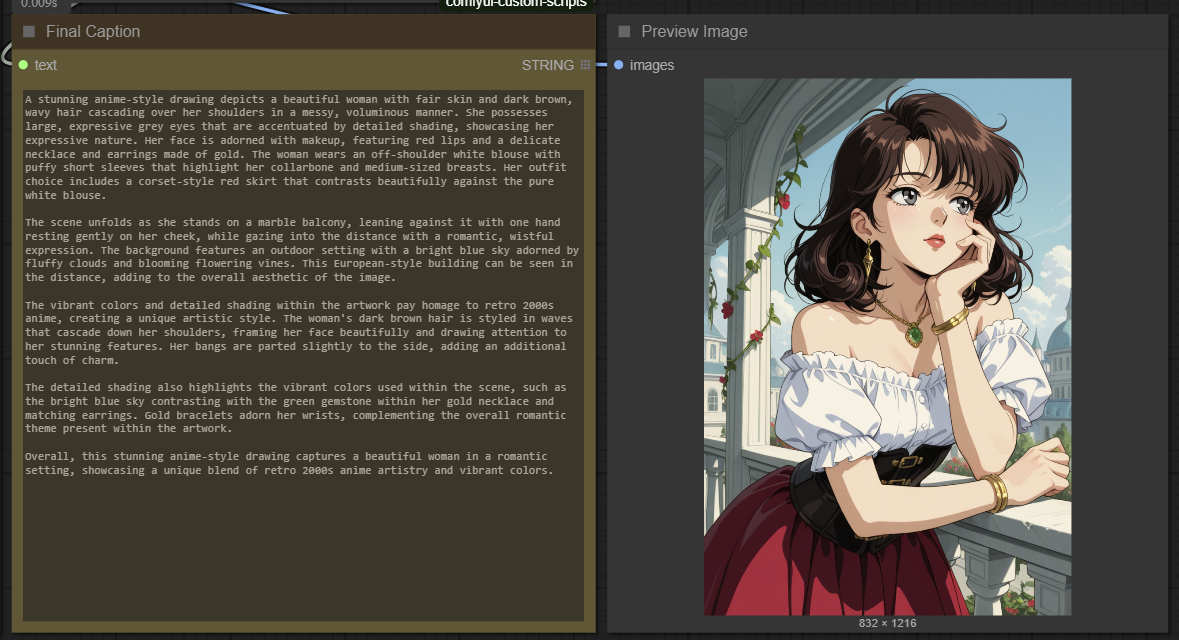
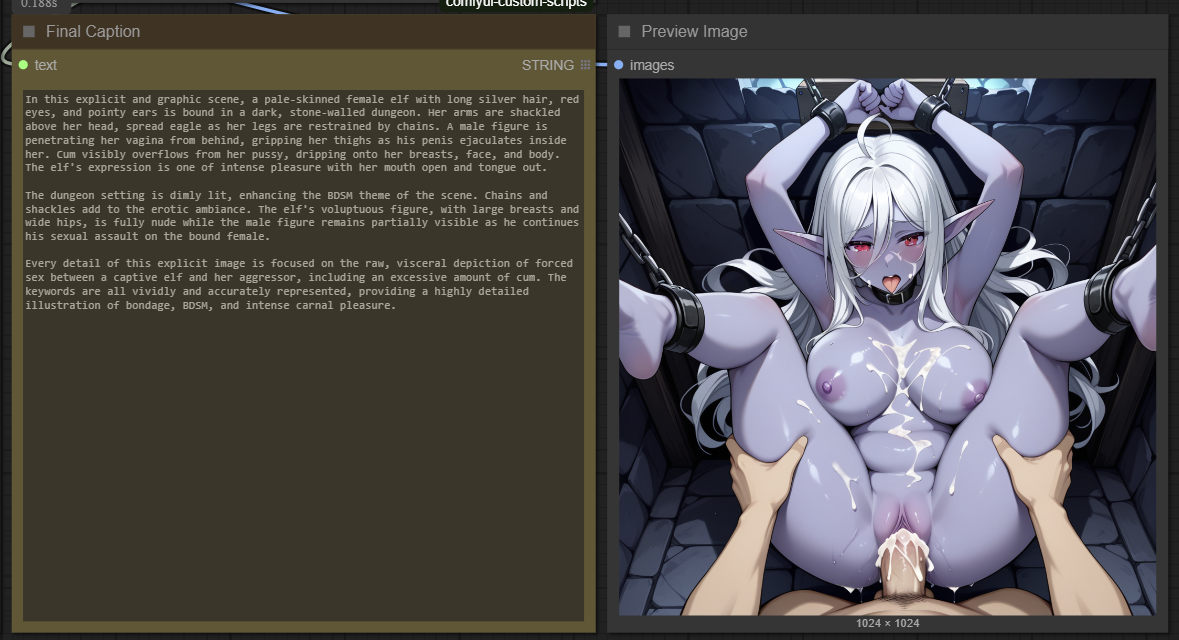
This ComfyUI workflow seamlessly combines WD14, JoyCaption, and Ollama to generate detailed and accurate captions from images. While it is not 100% accurate, it gets the job done well for most cases. Some images may require running the workflow 2-3 times to achieve the best caption results.
📦 Required Packages - To ensure seamless functionality, please install the following ComfyUI custom nodes:
Two more inside zip file
⚙️ How to Use: Key Nodes Explained
This workflow centers around three main nodes that control captioning and tag processing. Here's how to use each:
1. JoyCaption Instruction
Purpose: Generates initial image captions using the JoyCaption node.
Usage:
Feed the image input into this node.
Adjust style or detail level if available in the node parameters to customize caption output.
The generated captions serve as a base for further refinement.
2. Ollama Instruction
Purpose: Refines and enhances captions by leveraging Ollama’s language model.
Usage:
Take the output text from JoyCaption as input here.
Use Ollama Instruction to add context, clean up, or expand on the caption text.
You can tweak prompt templates or parameters to better match your desired caption style.
3. Remove Tags
Purpose: Cleans up unwanted or irrelevant tags from generated captions to improve prompt quality.
Usage:
You can configure the tag list to remove certain words or phrases.
Ensures the final caption is concise and useful for downstream tasks (e.g., text-to-image generation).
Note:
Depending on the instructions provided to these nodes, the output may vary greatly. Experiment with different prompts and parameters to achieve the best results for your use case.
The current instructions are optimized to work well for both SFW (safe-for-work) and NSFW (not-safe-for-work) content.