WAN2.2 S2V Pro - AI Sound-to-Video Suite with Voice Cloning

详情
下载文件 (1)
模型描述
Go beyond text and images. This groundbreaking workflow uses sound as the driving force for AI animation. Generate stunning, audio-synchronized videos from a single image and any audio input. Features integrated voice cloning (TTS) to create narrated videos from scratch. Unleash the power of WAN2.2's 14B Sound-to-Video model for a truly multi-sensory AI experience.
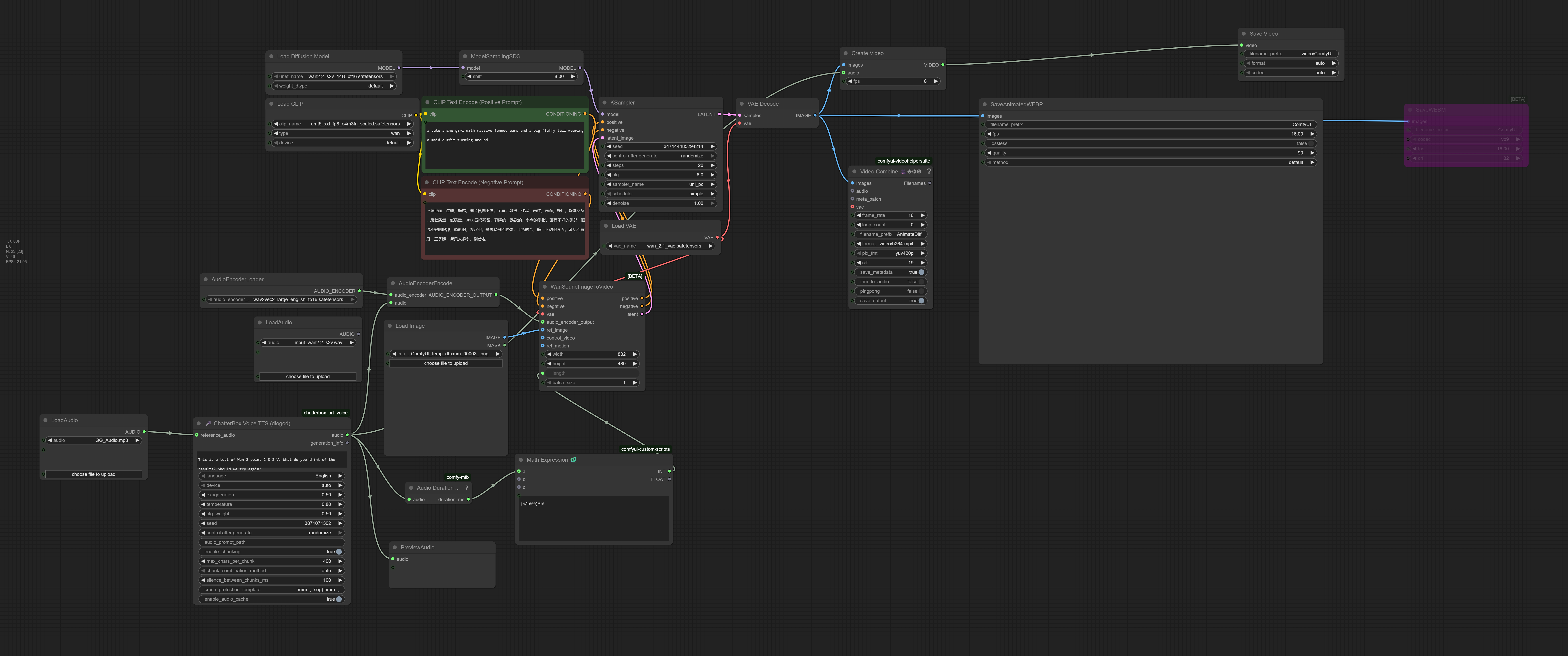
Workflow Description
Welcome to the next frontier of AI video generation. This workflow leverages the specialized WAN2.2 S2V (Sound-to-Video) 14B model to create animations that are intrinsically linked to an audio source. The model doesn't just overlay audio; it uses the audio's characteristics (speech, music, sound effects) to influence the motion and dynamics of the generated video.
The Magic of Sound-to-Video:
Narration-Driven Animation: Speak a sentence, and the character's movements will subtly sync with the speech patterns.
Music-Video Effects: Feed it a music track, and watch as the motion and flow of the animation respond to the rhythm and tempo.
Complete Storytelling: The integrated voice cloning allows you to create a full narrated story from a single character image and a script.
This isn't just an animation tool; it's a powerful pipeline for content creators, storytellers, and artists exploring the synergy between audio and visual AI.
Features & Technical Details
🧩 Core Components:
Model:
wan2.2_s2v_14B_bf16.safetensors(The specialized Sound-to-Video model)VAE:
wan_2.1_vae.safetensorsCLIP:
umt5_xxl_fp8_e4m3fn_scaled.safetensorsAudio Encoder:
wav2vec2_large_english_fp16.safetensors(Encodes audio for the model)
🎙️ Integrated Voice Cloning (TTS):
Node:
ChatterBoxVoiceTTSDiogodFunction: Generates realistic speech from text. It can clone a voice from a reference audio file (
GG_Audio.mp3).Use Case: Create your narration script in the node, and it will generate the audio that then drives the video animation.
🎬 Output & Encoding:
Flexible Outputs: The workflow saves multiple formats for maximum compatibility:
MP4 Video with Audio: Via
CreateVideo+SaveVideonodes.Animated WEBP: For high-quality, smaller file size loops.
WEBM: A modern video format.
VHS_VideoCombine: Provides additional encoding options.
Auto-Duration: The workflow automatically calculates the correct video length based on your audio file's duration.
How to Use / Steps to Run
Prerequisites:
The Specialized Model: You must have the
wan2.2_s2v_14B_bf16.safetensorsmodel. This is different from the standard T2V/I2V models.ComfyUI Manager: To install any missing custom nodes (especially
comfy-mtbfor the audio duration node).Audio File: Have an audio file ready (e.g.,
input_wan2.2_s2v.wav) or use the built-in TTS.
Method 1: Use Your Own Audio File
Load Your Image: In the
LoadImagenode, select your starting image (e.g., a character portrait).Load Your Audio: In the
LoadAudionode, select your.wavor.mp3file.Craft Your Prompts: Describe your character/scene in the Positive Prompt node. The negative prompt is already set.
Queue Prompt. The audio will be encoded and used to animate your image.
Method 2: Generate Audio with Voice Cloning (TTS)
Load Your Image: As above, select your starting image.
Provide a Voice Reference: In the
LoadAudionode at the bottom, provide a short audio sample of the voice you want to clone (GG_Audio.mp3).Write Your Script: In the
ChatterBoxVoiceTTSDiogodnode, change the text to whatever you want the voice to say. e.g.,"This is a test of Wan 2 point 2 S 2 V. What do you think of the results?"Queue Prompt. The workflow will:
Generate the audio from your text using the cloned voice.
Use that newly generated audio to drive the video animation.
Save the final video with the synchronized audio.
⏯️ Output: Your videos will be saved in your ComfyUI output/ folder in the various selected formats (MP4, WEBP, WEBM).
Tips & Tricks
Audio Quality: For best results, use clear audio files without background noise. The model encodes the audio, so quality matters.
Prompt is Still Key: While audio drives the motion, your text prompt still defines the character and style. A prompt like "a person smiling and talking" will work better with speech than a generic one.
Experiment with Audio: Try different types of audio! Music, sound effects, and speech will all produce uniquely different styles of motion.
Length Calculation: The
MathExpressionnode calculates video length:(audio_duration_in_ms/1000)*16_fps. You can adjust this formula if you want a longer or shorter video for the same audio clip (e.g.,(a/1000)*8for an 8fps slow-motion effect).Troubleshooting: If you get an error, the first thing to check is that you have the correct
wan2.2_s2v_14B_bf16.safetensorsmodel, not a standard Wan model.
This workflow demonstrates a fascinating and less-explored capability of AI video generation. It opens up incredible possibilities for automated content creation, dynamic music visuals, and personalized storytelling.
We can't wait to see what you create when sound takes the lead!