WAN2.2 S2V QuantStack - GGUF 14B Sound-to-Video

详情
下载文件 (1)
模型描述
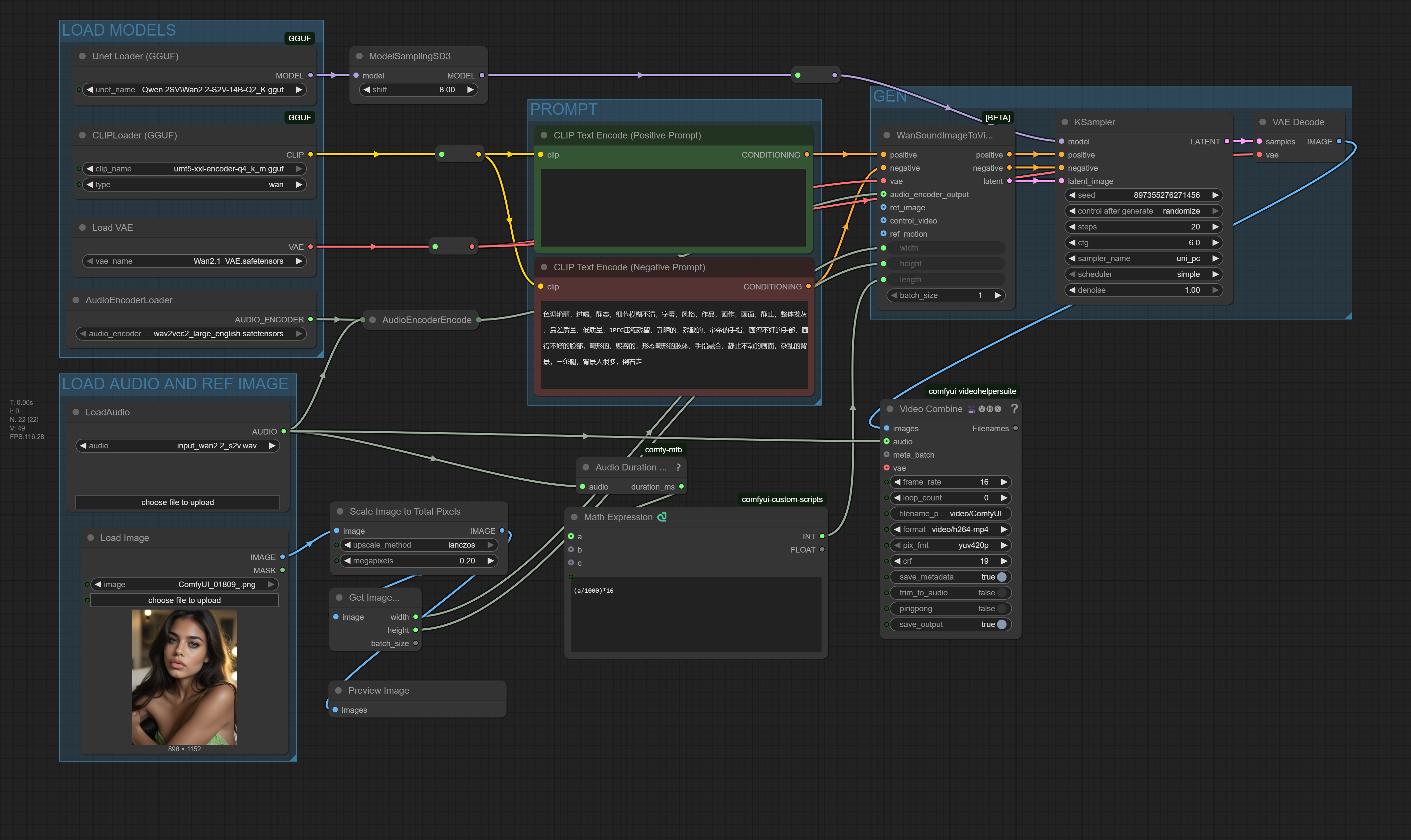
Breakthrough efficiency for Sound-to-Video. This revolutionary workflow runs the massive 14B parameter WAN2.2 S2V model on consumer hardware by leveraging fully quantized GGUF models for the UNET and CLIP. Experience true audio-driven animation with drastically reduced VRAM requirements, making high-end S2V generation accessible to everyone. CPU/GPU hybrid execution enabled.
Workflow Description
This workflow is a technical marvel, designed to democratize access to the powerful WAN2.2 Sound-to-Video 14B model. By utilizing the ComfyUI-GGUF plugin, it loads both the UNET and CLIP models in highly compressed, quantized GGUF formats. This translates to:
Massive VRAM Savings: The Q2_K quantized UNET allows the 14B model to run on GPUs with as little as 8-10GB of VRAM, or even on capable CPU systems.
Hybrid Execution: Seamlessly offloads layers between GPU and CPU to maximize performance on any hardware setup.
Full Fidelity Functionality: Despite the compression, you retain the complete S2V feature set: audio-driven motion, high-quality output, and professional video encoding.
This is the ultimate solution for users who thought the 14B S2V model was out of reach. Now you can run it.
Features & Technical Details
🧩 The Quantized Stack (The Magic Sauce):
UNET (GGUF):
Wan2.2-S2V-14B-Q2_K.gguf- The core video generation model, quantized to 2-bit for extreme efficiency.CLIP (GGUF):
umt5-xxl-encoder-q4_k_m.gguf- The text encoder, quantized to 4-bit for optimal performance.VAE:
Wan2.1_VAE.safetensors- Loaded normally for maximum visual fidelity.Audio Encoder:
wav2vec2_large_english.safetensors- Encodes the input audio for the model.
🎬 Core Functionality:
True Sound-to-Video: The generated animation is directly influenced by the characteristics of your input audio.
Auto-Duration: Automatically calculates the correct number of video frames (
length) based on your audio file's duration.Smart Image Preprocessing: Automatically scales your input image to an optimal size (0.2 megapixels) while preserving its original aspect ratio for animation.
Professional Output: Uses
VHS_VideoCombineto render a final MP4 video with perfect audio sync.
⚙️ Optimized Pipeline:
Clean, grouped node layout for easy understanding and operation.
Efficient routing with reroute nodes to keep the workflow organized.
How to Use / Steps to Run
Prerequisites (CRITICAL):
ComfyUI-GGUF Plugin: You MUST install the
ComfyUI-GGUFplugin from its GitHub repository. This is non-negotiable.GGUF Model Files: Download the required quantized models:
Wan2.2-S2V-14B-Q2_K.gguf(Place inQwen 2SV\folder)umt5-xxl-encoder-q4_k_m.gguf
Standard Models: Ensure you have
Wan2.1_VAE.safetensorsandwav2vec2_large_english.safetensors.
Instructions:
Load Your Image: In the
LoadImagenode, select your starting image.Load Your Audio: In the
LoadAudionode, select your.wavor.mp3file.Craft Your Prompt: Describe your scene in the Positive Prompt node. The negative prompt is pre-configured.
Queue Prompt. The workflow will encode your audio, process it through the quantized 14B model, and generate the video.
⏯️ Output: Your finished video will be saved in your ComfyUI output/video/ folder as an MP4 file.