Qwen-image nf4 workflow (4-8steps, 16GB VRAM compatible)

詳細
ファイルをダウンロード
モデル説明
このワークフローは、最新の bnb 4-bit モデル読み込みプラグインを使用して、bnb NF4 形式で量子化された Qwen-Image モデルを読み込みます。
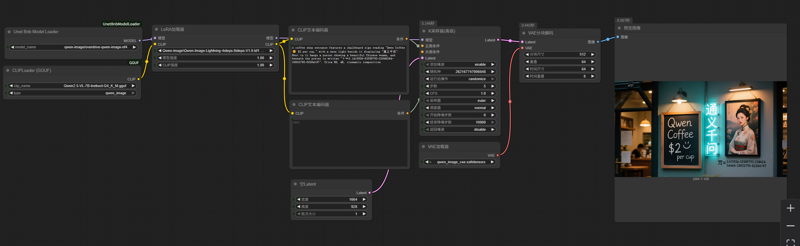
不足しているプラグインは、ComfyUI Manager のプラグイン管理システムから直接インストールするか、「Unet Bnb Model Loader」と検索してインストールできます。もちろん、手動でインストールすることも可能です。
使用するモデル: ovedrive/qwen-image-4bit · Hugging Face
このモデルはシャーディングされているため、シャードを手動で統合する必要はありません。単に、qwen-image-4bit などのディレクトリにシャードを配置し、そのディレクトリを UNet ディレクトリに置くだけで済みます。プラグインがシャーディングされたモデルを認識して読み込みます。ドロップダウンメニューでは、モデルは配置されているディレクトリ名に従って表示されます。
以下の LoRA 加速生成を使用してください: PJMixers-Images/lightx2v_Qwen-Image-Lightning-4step-8step-Merge · Hugging Face
以下の text_encoder を使用してください(GGUF プラグインが必要です): https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-GGUF/resolve/main/Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf?download=true
このワークフローによる画像生成全体の処理速度は、GGUF モデルを使用する場合の約2倍であり、結果は GGUF Q4 とほぼ同等です。メモリ使用量のピークは約15GBですが、画像を繰り返し生成する場合は約14GBに抑えられます。
画像生成速度は約1 it/s で、推奨ステップ数は5~6です。このワークフローは BitsAndBytes ライブラリに依存しているため、NVIDIA グラフィックスカード以外はサポートされていません。