Pusa



세부 정보
파일 다운로드 (1)
모델 설명
Pusa is a finetune for Wan 2.2 in LoRA format. It improves video quality.
Requirements: Kijai WanWrapper node https://github.com/kijai/ComfyUI-WanVideoWrapper
Note: As of 9/3/2025, ComfyUI just updated Pusa nodes yesterday. Should be a little bit easier to use now.
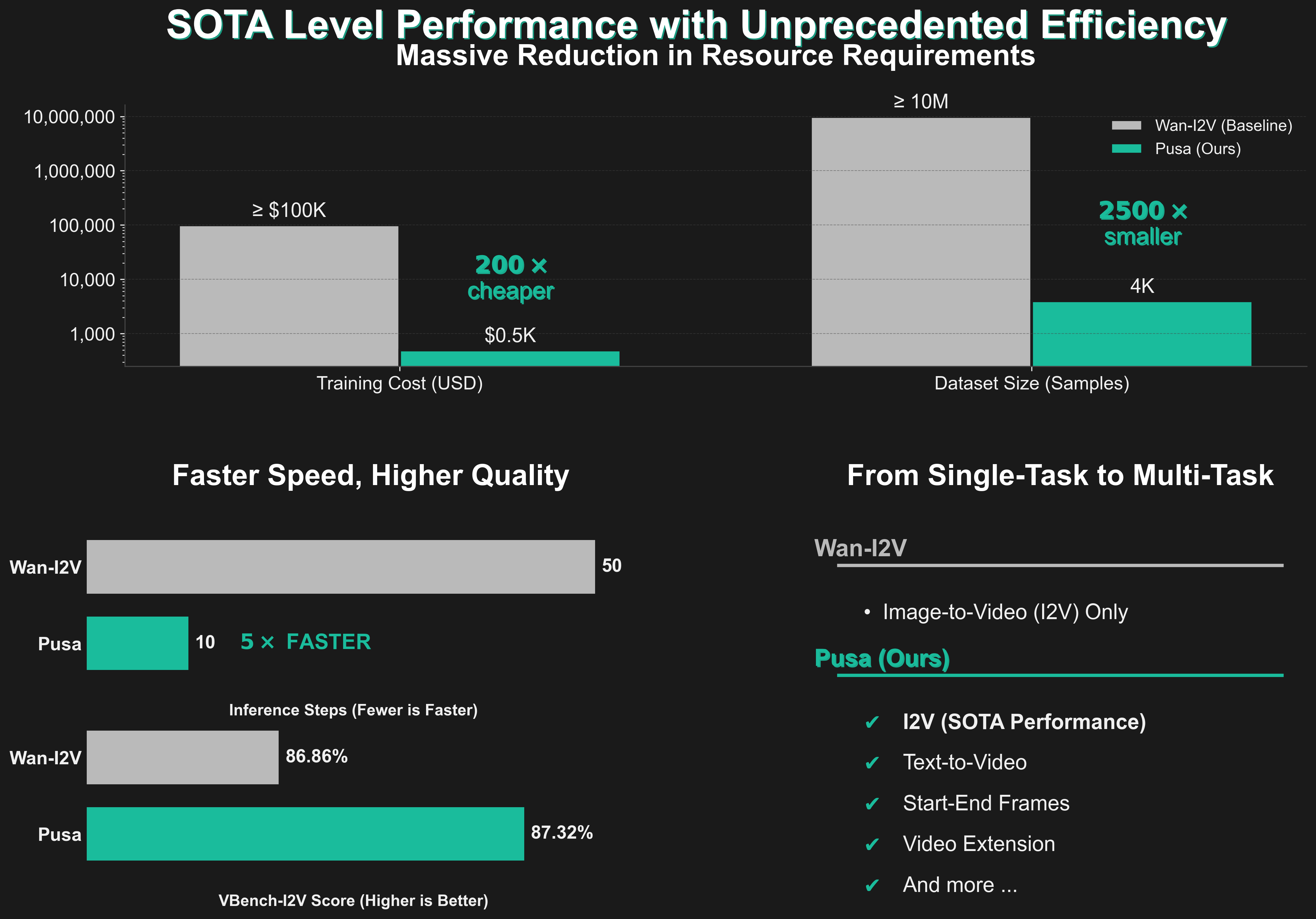
Various tasks in one model, all support 4-step inference with LightX2V: Image-to-Video, Start-End Frames, Video Completion, Video Extension, Text-to-Video, Video Transition, and more..
What Wan 2.2 Pusa Does
Video Generation Tasks: It can perform text-to-video, image-to-video (turning an image into a moving scene), video extension, transitions, and even more complex tasks like mapping both a starting and ending frame to a video seamlessly.
Multi-Input, Multi-Task: Unlike older models that needed a separate model or training for each task, Wan 2.2 Pusa’s unique design (the “Pusa paradigm”) allows it to generalize to different video tasks with one unified system and minimal additional training.
Fast and Efficient: Thanks to its “LightX2V” acceleration and “vectorized timestep adaptation” (VTA), it achieves high-quality results in very few inference steps, drastically reducing the computing power and time needed for video generation.
How Does It Work?
Vectorized Timestep Adaptation (VTA): The core innovation is its use of many “timesteps” for each video frame, letting the model adapt motion and transitions independently across the video. This means each part of a video can evolve with customized motion, leading to better temporal smoothness and creative control without disturbing the original strengths of the base video model.
Mixture of Experts (MoE): Wan 2.2 uses two specialized sub-models: one for “high noise” (complex motion) and one for “low noise” (preserving static details), blending their strengths for better video quality.
LoRA Fine-Tuning: The Pusa model uses a lightweight, “surgical” adaptation technique (LoRA) to inject new capabilities (like image-to-video) without overwriting what the base model already does well, preserving text-to-video powers while adding new features efficiently.
Wan 2.2 Pusa
https://github.com/Yaofang-Liu/Pusa-VidGen
https://huggingface.co/RaphaelLiu/Pusa-Wan2.2-V1
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Pusa
These are rank 256 LoRAs - that is why the file size is so large. These Loras are supposed to enhance the video/image quality of Wan 2.2. In my own personal use, I frequently find the effect subtle, but always improves the video. I don't know if it was trained on NSFW, but it works fine with it.
According to the author's page, they are supposed to be used around 1.4-1.5 weight. You can use it with lightx2v for 4-8 steps, or normally with normal steps.
Workflow Example: https://civitai.com/models/1923086?modelVersionId=2176586