Lora Lab: Press Start, Auto Gen, Auto Label, Auto Compile



Details
Download Files (1)
About this version
Model description
Part 1 of my Lab series. Checkout my other workflows on my profile, they can all be used in conjunction!
3 Step Auto Lora
Set your batch number hit run and generate 100s of hi-res images with auto captions!
Automatically store them in a consolidated folder
Feed it to a Lora Trainer!
I recommend Auto MED. Fully automatic, no manual packaging, no real loss in accuracy
Semi-Auto HI allows for much more manual interaction for those willing to put in the work for a slight increase in caption quality
Auto LO is for those with a low VRAM GPU. It will require loading one ksampler model and one interpreter model (Florence-Basic or Large)
https://github.com/anyantudre/Florence-2-Vision-Language-Model
Running Versions
____________________VRAM ______ACCURACY_____ MANUAL WORK
Semi-Auto HI _________HI_____________HI______________ HI
Auto MED ____________HI- ___________HI- _____________LOW
Auto LO ____________MED __________MED _____________LOW
SemiAuto HI: Dual inference models gets higher accuracy in prompts, but requires manually consolidating your folder and choosing the best prompt for each image. Dual Face refiner and refiner base model with 4x upscale creates hi-realism and accuracy.
Auto MED: Single inference model allows for auto compilation and requires no manual package construction. However it will slightly reduce accuracy (not noticeably IMO) in auto prompts. Dual Face refiner and refiner base model with 4x upscale creates hi-realism and accuracy.
Auto LO: Single inference model allows for auto compilation and requires no manual package construction. However it will slightly reduce accuracy (not noticeably IMO) in auto prompts. No Face refiner and refiner base model with 2x upscale creates med-realism and accuracy.
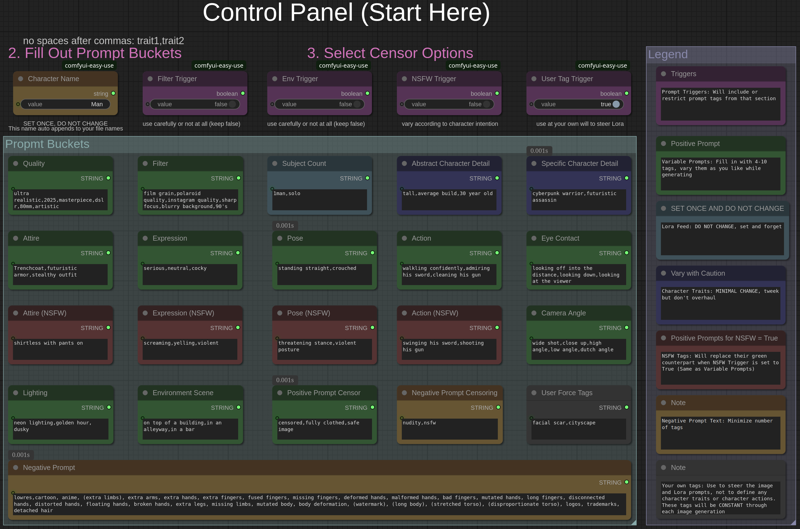
When filling in the prompt buckets DO NOT PUT A SPACE BETWEEN COMMAS.
(trait1,trait2,trait3)
How it works (Semi-Auto HI):
Workflow Logic
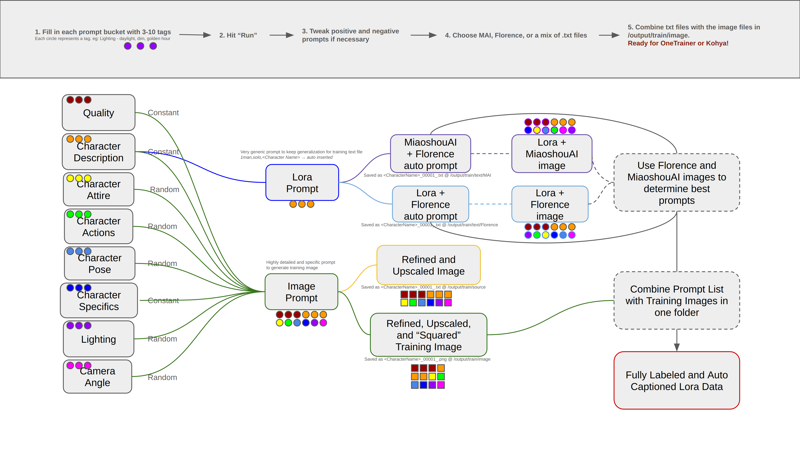
Real Image Example
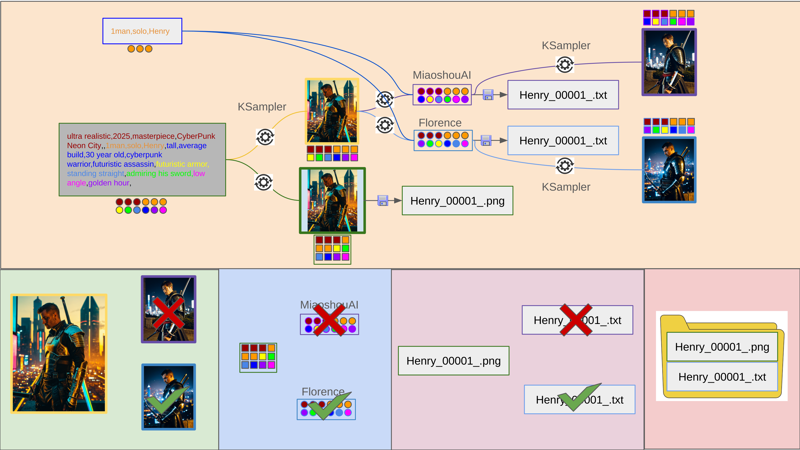
Workflow Prompt buckets
Workflow results 1 (Random Prompt, Random Orientation, Florence and MAI Results)
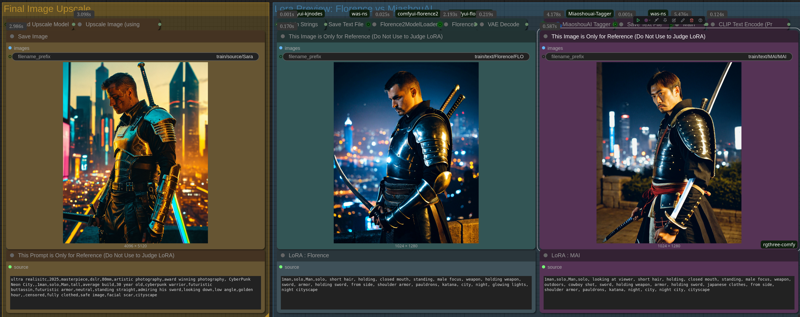
Workflow results 2 (Random Prompt, Random Orientation, Florence and MAI Results)
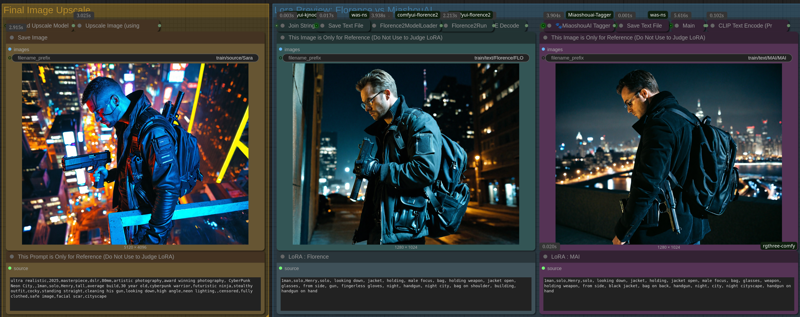
Henry Images + Best Prompts = Auto Lora Data

 Lora Training Images saved at: /output/train/image/
Lora Training Images saved at: /output/train/image/
Lora Text saved at: /output/text/Florence and /output/text/MAI
Up-scaled Images saved at: /output/train/source/
System Specs:
This workflow is High VRAM out of the box
If there is enough support/demand I will create Med VRAM and Low VRAM versions
High VRAM: Use the large model and fp16/sdpa where you can
Low VRAM: Use base models and fp8/flash attention where you can, skip the refiner, skip the upscale, and skip the detailers (might be tricky to re-wire)
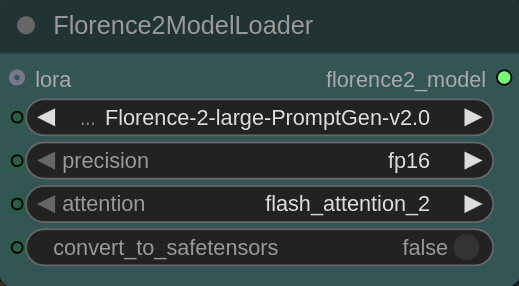
Prerequisites:
Necessary Custom Nodes: rgthree, easy-use, impact pack, impact subpack, florence 2, MiaoshouAI, basic math, was ns, Crystools, kj nodes, StringOps (Thank you devs!)
When you open the workflow ComfyUI-Manager should let you know you are missing nodes
Click install missing nodes, restart comfyui, and refresh browser
If there are still missing nodes search for them in the Custom Nodes menu in the Manager window
I also had to install flash attention
Easiest way is to look up your CUDA version (nvidia-smi in cmd) and download the prebuilt whl file here that matches those verions: https://github.com/mjun0812/flash-attention-prebuild-wheels?tab=readme-ov-file