Wan2.2 16GB Training

详情
下载文件 (1)
关于此版本
模型描述
★Training Wan2.2 Lora with 16GB of VRAM
!!! No download required! This is a technical showcase! !!!
→→→Original / Training dataset containing configurations provider→→→ https://civitai.com/models/1944129?modelVersionId=2200388
●Differences from the original:
4070 Ti Super 16GB / Mem 64GB
This is my first training (Really the first run)
(Replace musubi_tuner_gui.py)(I forgot to do this so i2v didn't work)
t2v (Unchecked I2V Training)
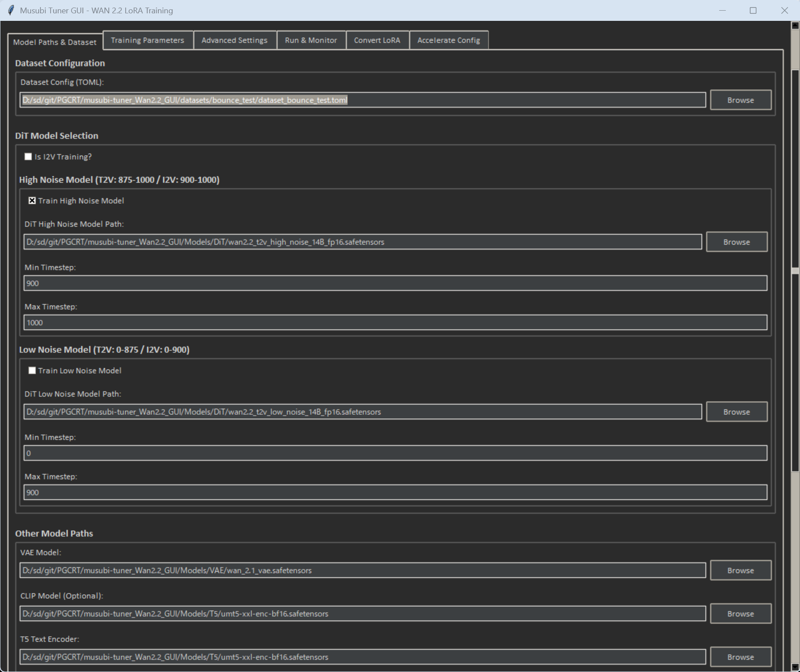
The model was also changed from i2v to t2v
Changed the path of other models to my environment
video_directory and cache_directory in dataset_bounce_test.toml
Install Triton and Sageattention2 (SDPA / I'm not sure about the effect, but I think Xformers would be good too.)
pip install -U "triton-windows<3.3"
python -s -m pip install .\triton-3.2.0-cp312-cp312-win_amd64.whl
→→→Guide is here→→→https://civitai.com/articles/12848
Blocks to Swap (As far as I know, this model has 40 blocks)
35 (original is 10)
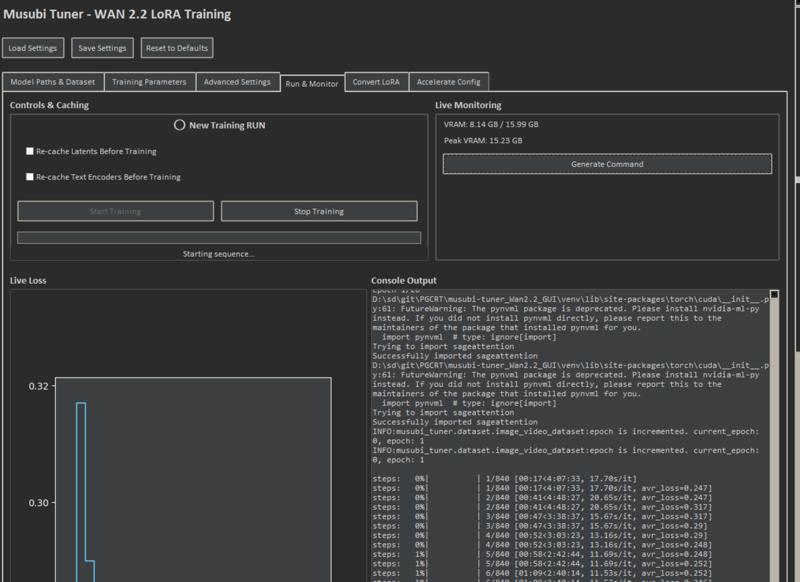
●VRAM required for training
30 percent of the time, I was using 15GB, and the rest of the time it was around 10GB.

As I write this, I set it to 40 to see if I could train with 12GB, but I got an error.
"AssertionError: Cannot swap more than 39 blocks. Requested 40 blocks to swap."
●Memory required for training
Approximately 29GB of system memory was used.
So I think 32GB should be just enough.
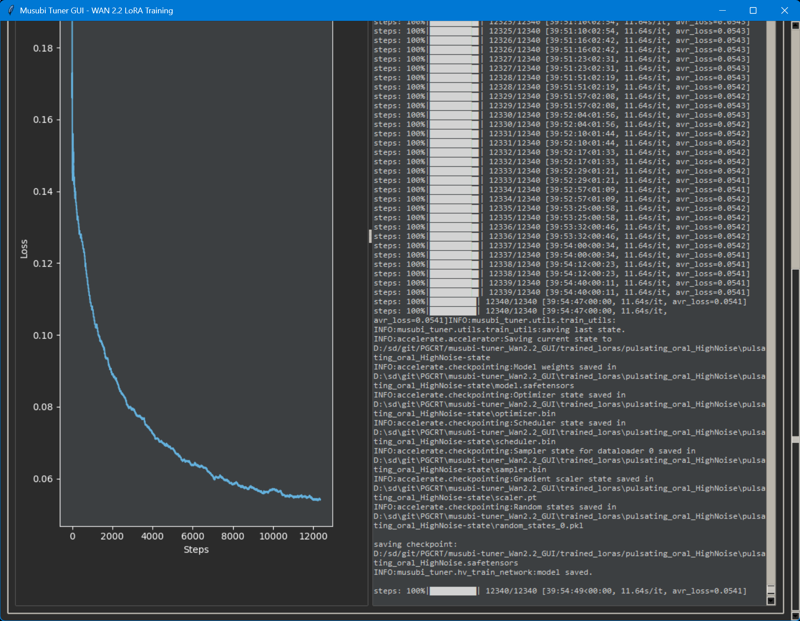
●Time required for training
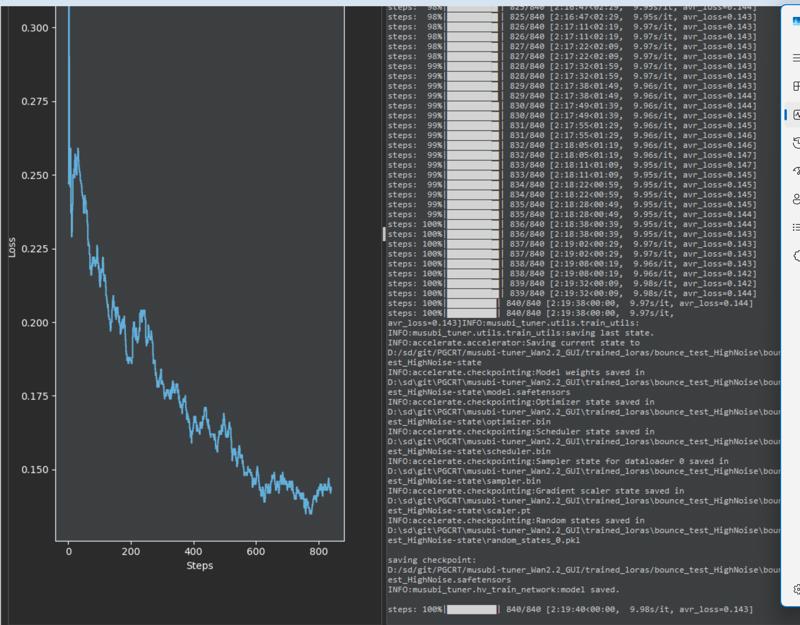
The high was 2 hours and 19 minutes, and Low was 2 hours and 17 minutes.
I trained for 20 epochs, but it took 5 epochs to see results.
So if I do it right, I can train in just over an hour. (Wow, I can't believe that!)
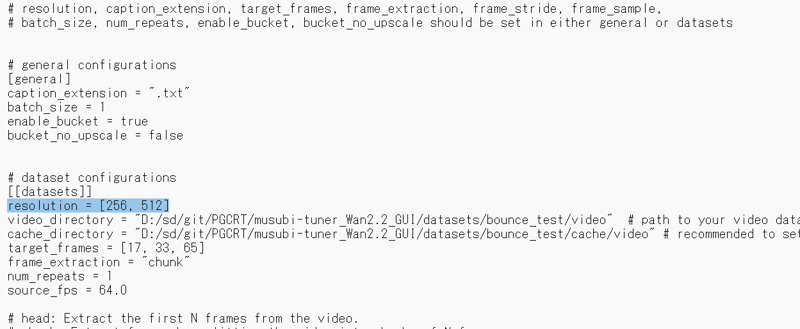
●Training Resolution (dataset_bounce_test.toml)
I think it will learn based on this specification rather than the resolution of the material.
resolution = [256, 512]
I just realized that I don't know what "source_fps = 64.0" means.
I see, the source video was really 64FPS.
●Training Screen
●Configuration
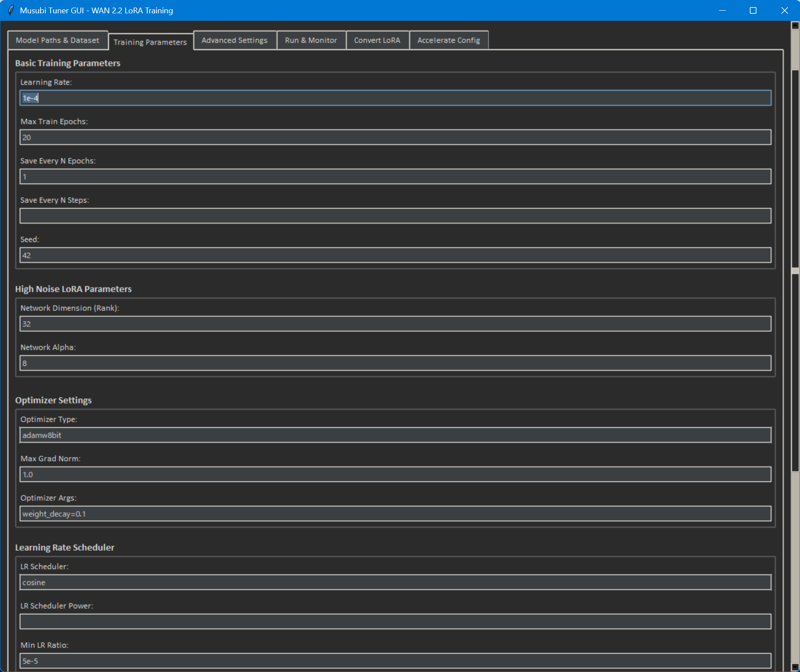
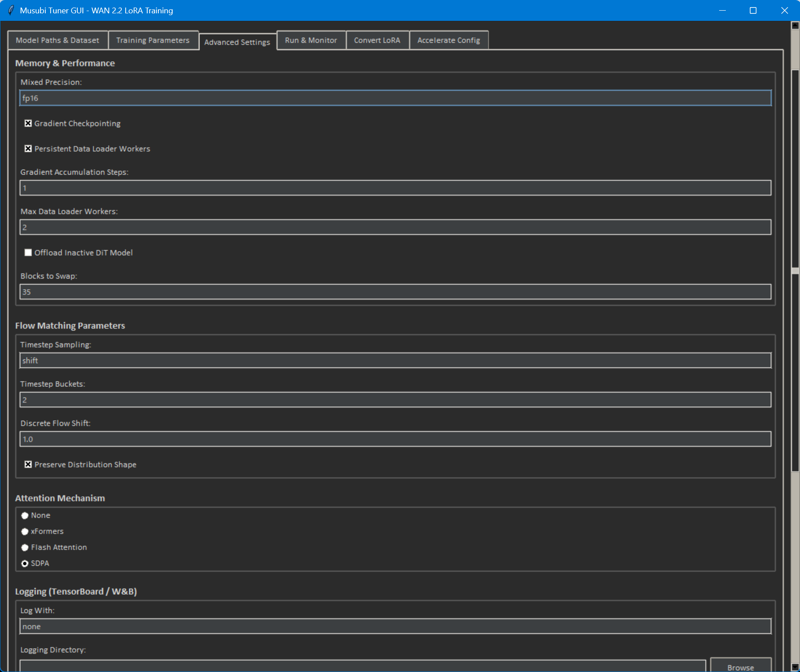
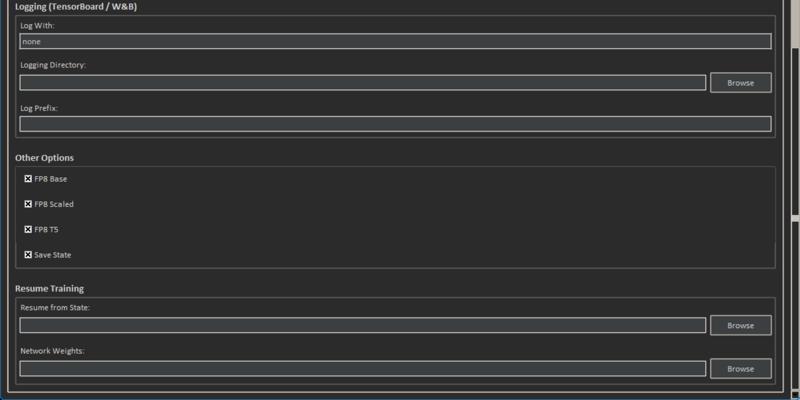
●Software and version
PS D:\sd\git\PGCRT\musubi-tuner_Wan2.2_GUI\venv\Scripts> .\activate
(venv) PS D:\sd\git\PGCRT\musubi-tuner_Wan2.2_GUI\venv\Scripts> pip list
Package Version Editable project location
----------------------- ------------ ---------------------------------------
absl-py 2.3.1
accelerate 1.6.0
av 14.0.1
bitsandbytes 0.45.4
certifi 2025.8.3
charset-normalizer 3.4.3
colorama 0.4.6
contourpy 1.3.2
cycler 0.12.1
diffusers 0.32.1
easydict 1.13
einops 0.7.0
filelock 3.13.1
fonttools 4.60.0
fsspec 2024.6.1
ftfy 6.3.1
grpcio 1.75.0
huggingface-hub 0.34.3
idna 3.10
importlib_metadata 8.7.0
Jinja2 3.1.4
kiwisolver 1.4.9
Markdown 3.9
MarkupSafe 2.1.5
matplotlib 3.10.6
mpmath 1.3.0
musubi-tuner 0.1.0 D:\sd\git\PGCRT\musubi-tuner_Wan2.2_GUI
networkx 3.3
numpy 2.1.2
nvidia-ml-py 13.580.82
opencv-python 4.10.0.84
packaging 25.0
pillow 11.0.0
pip 22.2.1
protobuf 6.32.1
psutil 7.0.0
pynvml 13.0.1
pyparsing 3.2.4
python-dateutil 2.9.0.post0
PyYAML 6.0.2
regex 2025.9.1
requests 2.32.5
safetensors 0.4.5
sageattention 2.2.0
sentencepiece 0.2.0
setuptools 63.2.0
six 1.17.0
sympy 1.13.1
tensorboard 2.20.0
tensorboard-data-server 0.7.2
tokenizers 0.21.4
toml 0.10.2
torch 2.6.0+cu124
torchvision 0.21.0+cu124
tqdm 4.67.1
transformers 4.54.1
triton-windows 3.2.0.post19
typing_extensions 4.12.2
urllib3 2.5.0
voluptuous 0.15.2
wcwidth 0.2.13
Werkzeug 3.1.3
zipp 3.23.0
●How many clips and how long do I need?
https://civitai.com/models/1454728/blowjobs-man-in-frame
20 clips of 3 seconds, 16fps, 512px512px
https://civitai.com/models/1962482/wan22-t2v-14b-prone-bone-sex
12 clips, ranging from 3 seconds to 6 seconds RTX4080.
https://civitai.com/models/1954733/asshole-wan-22-t2vi2v-14b
259 * 512x512 videos of 3 seconds a single 5090
https://civitai.com/models/1953874/twerking
20 videos - 3 seconds.
https://civitai.com/models/1953467/licking-breasts
23 videos - 512*512 - 3 seconds.
https://civitai.com/models/1953632/reverseanalcowgirlwan22t2v14b
7 clip used of about 3-4 seconds each RTX 3090 and 32 GB ram
https://civitai.com/models/1343431/bouncing-boobs-wan-14b
7 videos with about 4 second 4090 it was done in about 35 min
https://civitai.com/models/1934246/standing-sex
19 clips of 5 seconds, 16fps.
https://civitai.com/models/1930903/blowbang
21 clips of 5 seconds, 16fps.
https://civitai.com/models/1930239/missionary-anal-trans
20 clips of 5 seconds, 16fps.
https://civitai.com/models/1929589/kissing-tongue-action
25 clips of 5 seconds, 16fps.
https://civitai.com/models/1927742/side-sexspooning-trans
29 clips of 3 seconds, 16fps.
https://civitai.com/models/1916746/walking
10 secs ++
https://civitai.com/models/1927612/reverse-cowgirl-trans
41 clips of 3 seconds, 24fps (should've done a 16fps), maybe for next time.
https://civitai.com/models/1894970/wan-22-reverse-suspended-congress-i2vt2v
23 video clips of 3 seconds each, mainly 3D animation
https://civitai.com/models/1869475/wan-22-anime-cumshot-aesthetics-precision-load-i2v-beta-version
39 original animated clips Length: 3 seconds each FPS: 16 ↑Training Details↑
https://civitai.com/models/1944129/slop-bounce-wan-22-i2v
7 of my old AI generated videos on my 3090 ↑Training data includes↑
https://civitai.com/models/1941041/facefuck-t2v-wan22-video-lora
12 clips of 256 x 256 pixels, 3sec to 8sec
https://civitai.com/models/1874811/ultimate-deepthroat-i2v-wan22-video-lora-k3nk
593 clips with various resolution, 1sec to 3sec
https://civitai.com/models/1852647/m4crom4sti4-huge-natural-breasts-physics-wan22-video-lora-k3nk
211 res on a dataset of 889 clips 1sec to 3sec (several source videos at 16fps)
https://civitai.com/models/1858645/facial-cumshot-wan-22-video-lora
307 clips with 211 resolution, 1sec to 3sec
https://civitai.com/models/1845306/sideview-deepthroat-wan22-video-lora
700 clips with various resolution, 1sec to 3sec
https://civitai.com/models/1969272/4n4l-pl4y-i2v-anal-didlo-lora-wan22
98 clips with 256x256 resolution, 1sec to 3sec
https://civitai.com/models/1960102/self-nipple-sucking-lora-i2v-wan22-k3nk
319 clips of 5 different scenes with various resolutions, 1sec to 5sec 211 res
https://civitai.com/models/1954774/cunnilingus-pussy-licking-lora-i2v-wan22-k3nk
121 clips with various resolution, 1sec to 5sec 256 res
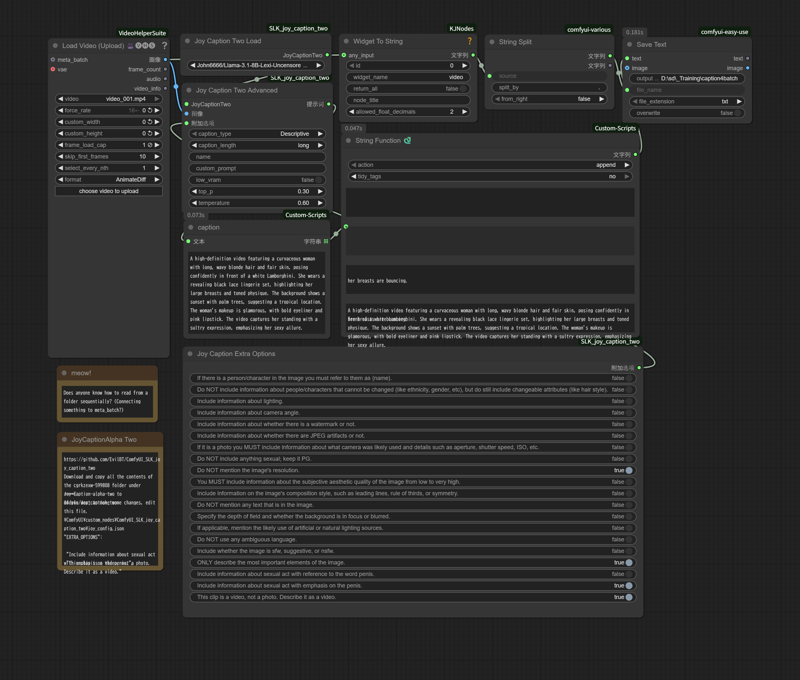
●Create captions (txt) from video file (Analyze one frame as an image)
I don't think this is the smartest way to do things, but I hope it helps someone.
You can load this image by downloading it and dropping it onto the Comfyui screen.
Oops, my workflow disappeared after uploading.
The caption text will be saved with the same filename as the video file.
●I tried the next Training
32 videos, 20epocs, resolution = [512, 288], blockswap=36
However, for some reason, 649 video caches were created, resulting in a final total of 12,340 steps... (39h54m / 1lora)