WAN 2.2 S2V Lipsync Workflow with SageAttention + BlockSwap + GGUF (include Upscale and Interpolation)

詳細
ファイルをダウンロード (1)
モデル説明
My TG Channel - https://t.me/StefanFalkokAI
My TG Chat - https://t.me/+y4R5JybDZcFjMjFi
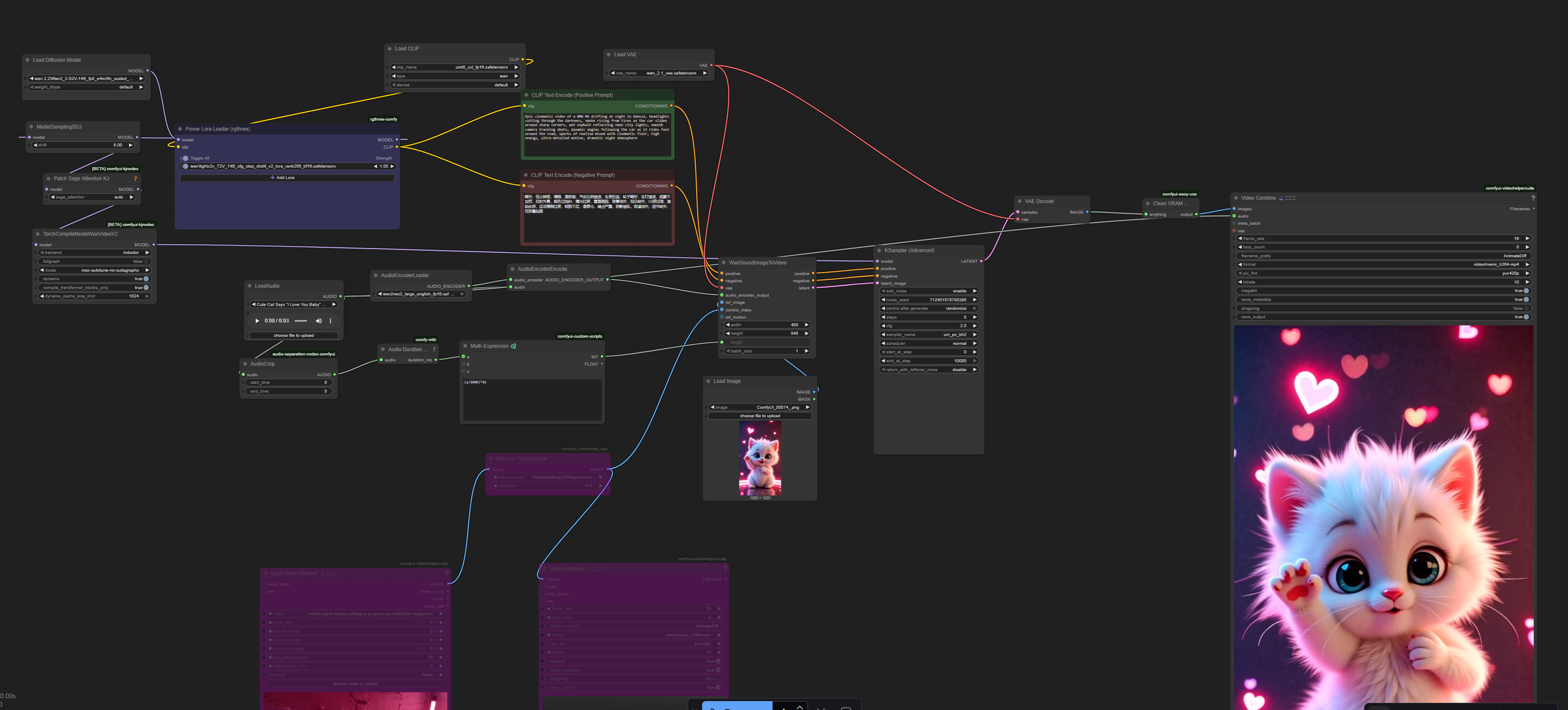
Hi! I introduce my working workflow with Wan 2.2 S2V generation video for ComfyUI.
You need to have Wan 2.2 S2V model
You need to have Wan 2.2 models (https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled/tree/main/S2V), clip (https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/blob/main/split_files/text_encoders/umt5_xxl_fp16.safetensors), audio_encoder (https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/audio_encoders) and vae (wan 2.1 vae)
GGUF - https://huggingface.co/QuantStack/Wan2.2-S2V-14B-GGUF/tree/main
Also I have included Lora https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v for better and fast generation
I recomend set strength 1.5 for loras to get best results
download my ComfyUI Build https://huggingface.co/datasets/StefanFalkok/ComfyUI_portable_torch_2.9.1_cu130_cp313_sageattention_triton, also u need download and install CUDA 13.0 (https://developer.nvidia.com/cuda-13-0-0-download-archive) and VS Code (https://visualstudio.microsoft.com/downloads/)
just use audio, image, write prompt and enjoy!
Leave comments if you have trouble or you found the problem with workflow