kontext pattern extractor









詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
Kontext: 2D Pattern/Graphic Extractor Lora
Overview & Purpose
This is a newly trained Kontext Lora for which the immediate applications are still being explored.
Its core function is the accurate extraction of surface patterns (liveries or decals) from objects. The primary plan is to curate these extracted planar graphic elements into a dedicated dataset for subsequent Qwen-Image model training.
Target Goal: Empowering the CMF Department
my immediate goal is to create a powerful resource for CMF (Color, Material, Finish) departments. This tool helps designers rapidly:
Collect and Extract: Efficiently pull interesting decals and liveries from various online sources.
Asset Conversion: Quickly convert complex visual motifs into a standardized, flat design format.
Library Building: Accelerate the process of compiling comprehensive design asset libraries for subsequent product development and conceptual work.
Future Vision: A Comprehensive Design Workflow
This current LoRA is the foundational first step in a much larger vision. i acknowledge the current limitations (e.g., reliance on side shots) and are actively exploring advanced features:
Complex Extraction: The ability to accurately extract patterns from photos of objects in motion, at extreme angles, or under challenging lighting conditions.
Reverse Application: Developing the capability to reverse-apply the extracted 2D graphic pattern back onto a 3D object to generate new, high-fidelity renders.
Ultimately, i'm building an end-to-end, comprehensive design workflow specifically tailored to revolutionize the way exterior paint, decal, and livery design is handled within the industrial and transportation CMF sector.
Workflow & Performance
Workflow: The model utilizes the standard workflow augmented simply by including a
loraloaderonlynode.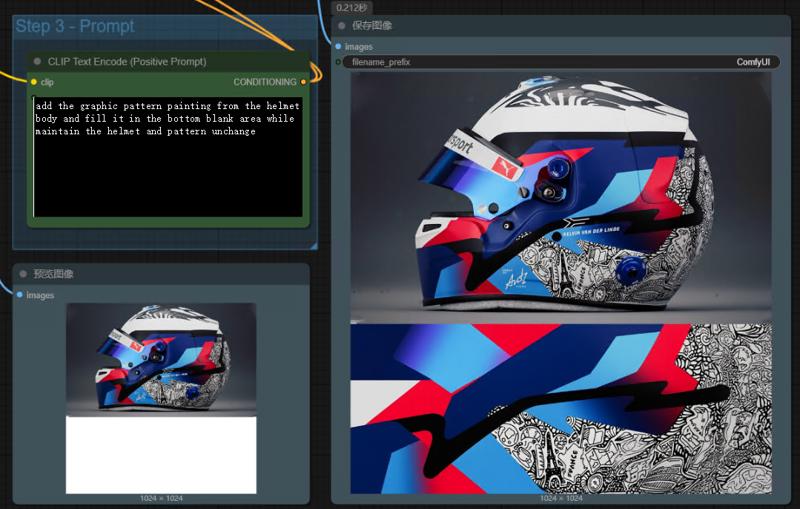
Input Requirement: Input images must be prepared in a specific format: the target object (e.g., car side profile) should be positioned in the upper area, with a blank canvas/space left below for the extracted pattern to be filled in (similar to Figure 1 format).

Best Suited For: Extracting decals and liveries from car side views.
The resulting pattern extraction is demonstrably superior to results achieved without using this Lora.
usable result is approximately one out of four attempts.
Complex motorcycle patterns are generally difficult to extract accurately.
Prompt Template
To use this Lora effectively, please follow this template:
add the graphic pattern from XXX body and fill it in the bottom blank area while maintain the XXX and pattern unchange
(Please replace XXX with the specific subject or object description.)
Civitai Tag
kontext pattern extract lora