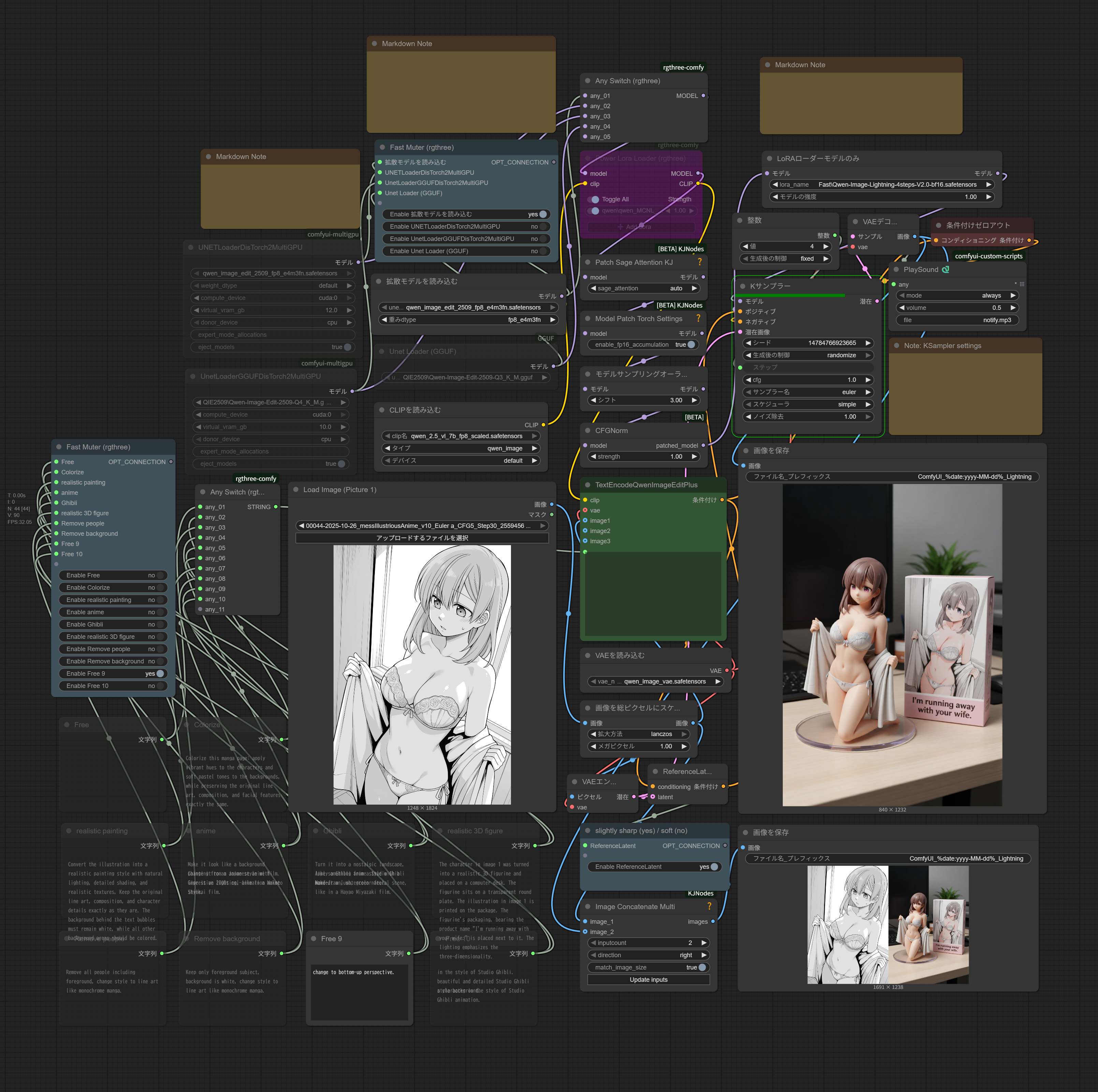
i2i 6GB 12GB 16GB bf16 fp8 gguf 4steps 20steps (Qwen2509 Workflow)










세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
fp8 and gguf workflow (single image)
Qwen2509_fp8_16GB_12GB_GGUF_6GB_4steps_v8 w/Lightning Lora
Qwen2509_fp8_16GB_12GB_GGUF_6GB_20steps_v8
VRAM usage (second pass)
16GB : bf16 (380 seconds on 4070tis @50steps 24GB MEM ,36GB MEM@VAE)
16GB : fp8 (25 seconds on 4070tis @4steps)
12GB : fp8 w/DisTorch2MultiGPU
6GB : Q4gguf w/DisTorch2MultiGPU
16GB : Q4gguf
16GB : fp8 meitu (160 seconds on 4070tis @20steps) (I felt the prompt response was 2509 >> Meitu)
I'm uploading this because it was hard to find a workflow that doesn't use Lightning Lora.
(But Lightning 4steps is very good.)