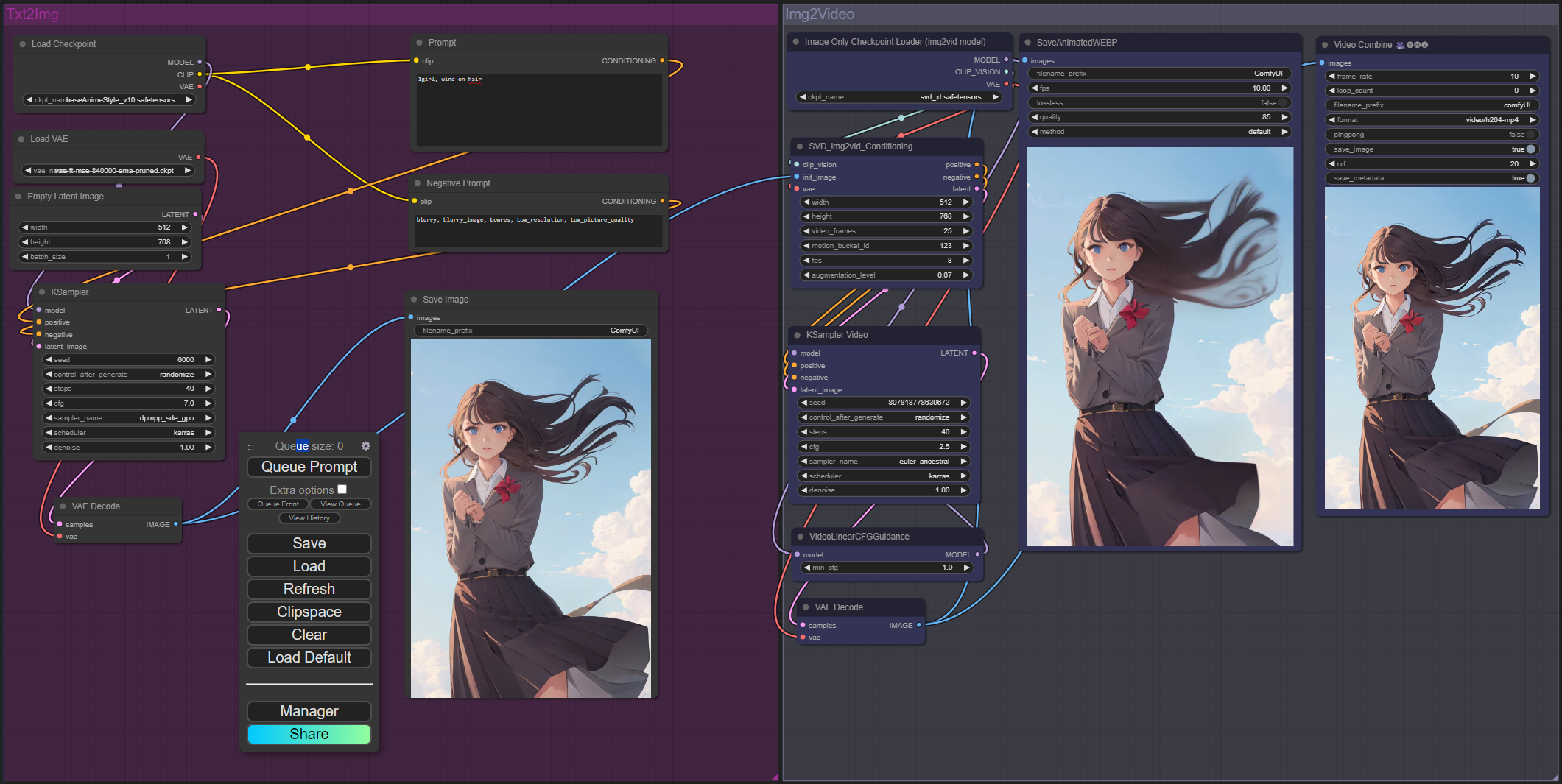
ComfyUI Txt2Video with SVD

详情
下载文件 (1)
关于此版本
模型描述
UPDATE: You can download SVD ver 1.1 here: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main
"This model was trained to generate 25 frames at resolution 1024x576 given a context frame of the same size, finetuned from SVD Image-to-Video [25 frames]."
From Stable Video Diffusion's Img2Video, with this ComfyUI workflow you can create an image with the desired prompt, negative prompt and checkpoint(and vae) and then a video will automatically be created with that image.
v1.3_sd3: txt2video with Stable Diffusion 3 and SVD XT 1.1
For information where download the Stable Diffusion 3 models and where put the .safetensors: https://civitai.com/models/497255/stable-diffusion-3-sd3
v1.3_cascade: txt2video with Stable Cascade and SVD XT 1.1
For information where download the Stable Cascade models and where put the .safetensors: https://gist.github.com/comfyanonymous/0f09119a342d0dd825bb2d99d19b781c
v1.3: svd default is now: svd_xt_1_1.safetensors
.gif creation instead .webp(.mp4 is still present)
v1.2: changed the default value of fps svd img2vid_conditioning from 8 to 10, previously it was erroneously different from the save value and save webp value of 10
v1.1: more clear interface
v1: first version
Required:
1- on Windows: 8+ GB VRAM NVIDIA gpu only
on Linux: 8+ GB VRAM NVIDIA gpu and AMD gpu
2- ComfyUI: https://github.com/comfyanonymous/ComfyUI
3- this worfklow
4- in ComfyUI\models\checkpoints:
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/blob/main/svd.safetensors <-- for 14 fps video
or
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/svd_xt.safetensors <-- for 25 fps video
5- a checkpoint in ComfyUI\models\checkpoints
6- a vae in ComfyUI\models\vae (optional)
7- ComfyUI Manager for the Missing Nodes: https://github.com/ltdrdata/ComfyUI-Manager
P.S.: The recommended resolution for SVD is 576x1024, but in the workflow I set a default value of 512x768 (with 40 steps, 20 steps is good enough). It's up to you to choose the resolution and steps that you want... but 512x768 with 40 steps is a good starting point for your attempts.
If you want to support me, check out my Patreon: https://www.patreon.com/Shiroppo
Follow me on civitai(!!!): https://civitai.com/user/shiroppo
Follow Me on Twitter/X: https://x.com/ShiroppoTwit
Pixiv: https://www.pixiv.net/users/96490888
---