Tutu's high heels (ValXXXXno)/图图的高跟鞋(华XX奴)




















详情
下载文件 (1)
关于此版本
模型描述
Created with Tutu AI Workflow
Trained with Tutu Trainer. Tagged with Tutu Annotator.
This LoRA is part of my Tutu AI workflow. Tutu Trainer is used for LoRA training, model resource management, parameter presets, and training checks. Tutu Annotator is used for dataset annotation, prompt reverse engineering, English-friendly tags, and cleaner searchable captions.
For a footwear LoRA, the hard part is not only learning "high heels". The model also needs to separate the shoe silhouette, heel shape, foot position, body pose, clothing, floor, and camera distance. Clean training and clean tags help the LoRA focus on the shoes instead of polluting the whole image.

- Official website: https://zhaotutu.xyz/
- Tutu Trainer: https://zhaotutu.xyz/downloads/tututrainer/
- Tutu Annotator: https://zhaotutu.xyz/downloads/tutuannotator/
- Bilibili: https://space.bilibili.com/431046154
- YouTube: https://www.youtube.com/@zhaotutu/videos
- Telegram: https://t.me/zhaotutu
- TikTok: https://www.tiktok.com/@zhaotututu
- Reddit: https://www.reddit.com/user/zhaotututu/
- GitHub: https://github.com/zhaotututu
- Email: [email protected]
- QQ: 331506796
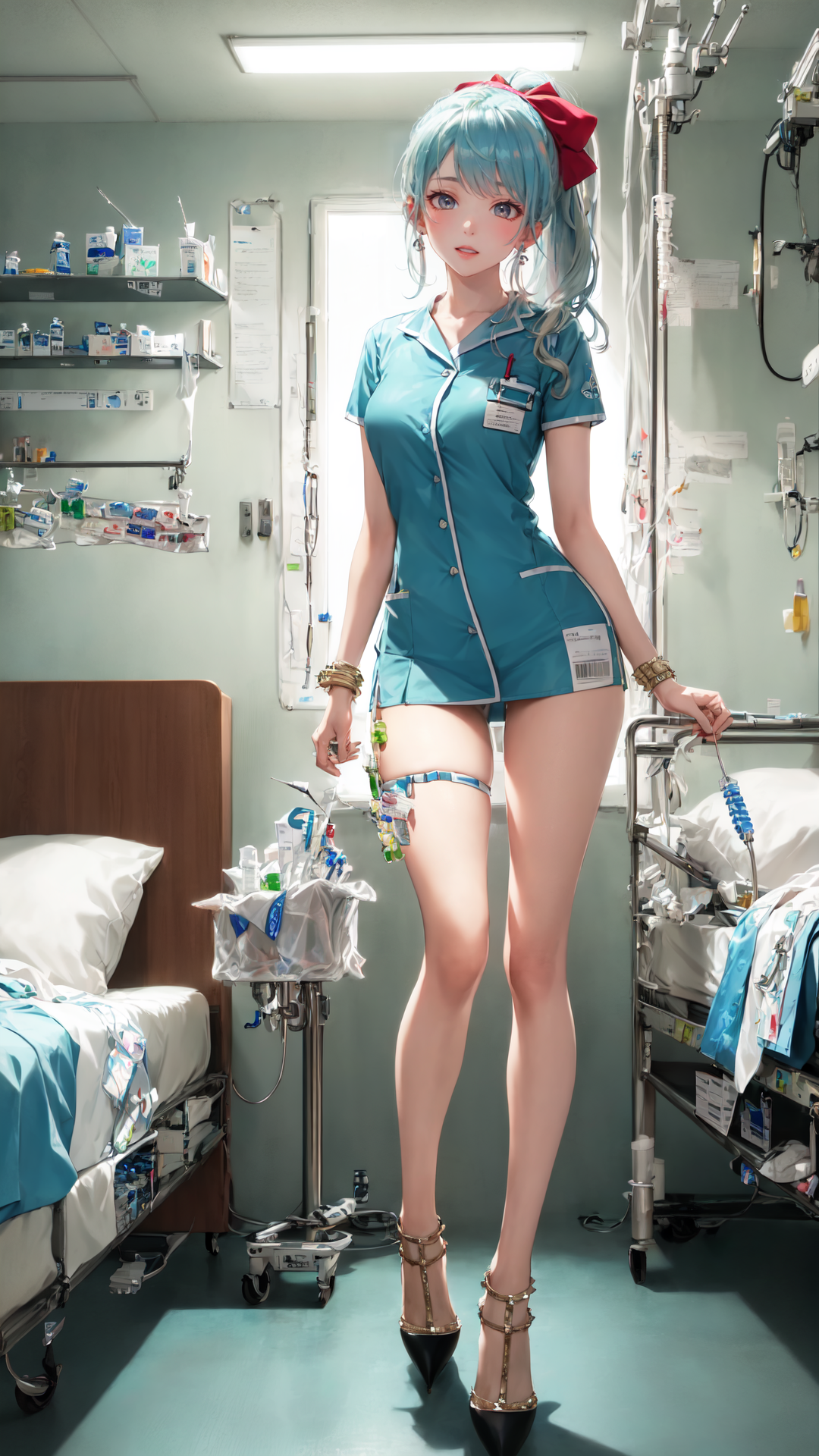
Tutu's High Heels LoRA (ValXXXXno Style)
This is a fashion-footwear LoRA for ValXXXXno-style high heels. It is designed to help full-body and fashion images restore a more recognizable high-heel shape while keeping the character, outfit, pose, and scene as flexible as possible.
I have to admit that I seem to make things difficult for myself every once in a while. I knew high heels would be hard to train, and after doing it, yes, they were hard. In many images, shoes occupy a very small area, the target resolution is limited, and the details are easy to disappear. So this model is not magic. It is a practical high-heel enhancement LoRA with relatively high restoration and low pollution.
- Type: high heels / fashion footwear LoRA
- Base model: SD 1.5
- Current recommended version: v2.0
- Main trigger group:
tutututu,high heels - Recommended weight: 0.4 to 0.9, start around 0.65
- Recommended CLIP skip: 2
- CFG Scale: start around 7
What this model is good at
- Adding a more recognizable high-heel shape to fashion and full-body images.
- Improving shoe restoration without forcing a fixed character, outfit, or background.
- Reducing pollution compared with many clothing / accessory LoRAs.
- Working as part of a broader clothing LoRA workflow with the unified
tututututrigger style. - v2.0 improves detail compared with the earlier version, although the overall direction remains the same.
Important limitation
High heels are a small target in most character images. If the camera is far away, the feet are cropped, the skirt hides the shoes, or the image resolution is too low, the LoRA cannot create unlimited detail. The quality of this model is above average, and the restoration is good, but there may still be a little pollution around feet, legs, or nearby clothing at higher weights.
My goal here is practical usefulness: better high-heel presence, cleaner shoe shape, and lower interference. If you need a close-up commercial shoe render, use a closer camera, higher resolution, and clearer shoe prompts.
Why I made this LoRA
There are already many similar LoRAs, but many of them are not close enough to real fashion items. Some popular clothing and accessory directions are missing, and the quality is uneven. A lot of models affect the character and the whole image too much, which makes them inconvenient for daily creation.
So I started making a series of clothing and accessory LoRAs. The trigger word style is kept simple: tutututu plus the target object. For this one, the target is high heels. The difference extraction method cuts away most unrelated content, so the model focuses more on the shoe direction and less on the rest of the image.
Recommended settings
- Make sure the LoRA is loaded correctly.
- Recommended CLIP skip / CLIP stop layers: 2.
- Recommended weight: 0.4 to 0.9. Start around 0.65.
- Start CFG Scale around 7.
- Do not add too many negative prompts, or the LoRA effect may be weakened.
- I did not use LoRA Block Weight in the original examples, but you can try it if you need more local control.
- For full-body images, make sure the feet and shoes are actually visible.
Prompt keywords
Main trigger group:
tutututu, high heels
Useful prompt phrases:
high heelsstiletto heelspointed-toe heelsankle strap heelsfashion high heelsluxury style shoesfull bodyfeet visiblestanding posefashion portrait
If the shoes are missing, first make the camera and body framing clearer: full body, feet visible, standing pose, and high heels. If the shoe style becomes too strong or starts affecting legs and clothing, lower the LoRA weight before adding many negative prompts.
Version notes
v2.0 - current recommended version. I felt the earlier details still had room for improvement, so I rebuilt it with a new method. The improvement is real, but the overall change is not huge. The usage remains the same, and I still recommend upgrading to v2.0.
v1.0. The first public version. It already had relatively high restoration and low pollution, but the small-target detail still left room for improvement.
FAQ
Why are the shoes not obvious?
The target may be too small or hidden. Use full-body framing, make feet visible, and add clear shoe prompts.
Why do the feet or legs become strange at high weight?
Lower the LoRA weight first. High heels interact with feet, legs, floor contact, pose, and camera angle, so too much weight may affect nearby areas.
Why can I not get exactly the same image as the examples?
Different computers, base models, samplers, LoRAs, plugins, and settings will produce different results. Please use the examples as a direction and create your own best version.
Responsible use
- You are fully responsible for any creative work made with this model.
- Do not use this model to create or share illegal, harmful, malicious, defamatory, fraudulent, or political content.
- If you use this model commercially, please inform me. Thank you.
中文说明
这是图图服装 / 配饰系列里的 高跟鞋 LoRA(华XX奴风格)。它主要用于时装、全身人像、搭配类图片,让高跟鞋形态更明确,同时尽量减少对人物、衣服、姿势和背景的污染。
我感觉自己隔一段时间就要难为自己一下。明知道高跟鞋不好练,还是练了。练完以后发现,果然不好弄。原因很简单:高跟鞋在很多图里目标很小,分辨率不高的时候细节非常容易丢失,所以这个模型不是魔法,而是一个更实用的高跟鞋增强 LoRA。
- 类型:高跟鞋 / 时装鞋履 LoRA
- 基础模型:SD 1.5
- 当前推荐版本:v2.0
- 主触发词组:
tutututu,high heels - 推荐权重:0.4 到 0.9,建议从 0.65 开始
- CLIP 终止层:2
- CFG Scale:从 7 左右开始
这个模型适合什么
- 在时装图、全身图里加强高跟鞋形态。
- 让鞋子更接近真实高跟鞋,而不是只出现普通鞋或模糊脚部。
- 尽量不强制固定人物、衣服、背景和姿势。
- 相比很多服装 / 配饰 LoRA,污染更少。
- v2.0 细节比早期版本更好,但整体方向没有大改。
重要限制
高跟鞋在大多数人物图里都是小目标。如果镜头太远、脚被裁掉、裙摆遮住鞋子、或者图片分辨率不够,细节就会受限。这个模型质量属于中上,还原度比较高,污染也不多,但高权重下仍然可能对脚、腿部或附近衣服产生一点影响。
所以推荐把它当作一个实用型增强模型:让鞋子更明确、更像高跟鞋,同时尽量保持画面其他内容灵活。如果想做鞋子特写,请使用更近的镜头、更高分辨率和更明确的鞋子提示词。
为什么要做这个 LoRA
类似的 LoRA 虽然很多,但我发现很多并不贴近真实服装 / 配饰,很多当下流行的方向没有,质量也参差不齐。有些 LoRA 对人物和整张图影响很大,用起来不够方便。
所以我打算做一系列服装和配饰 LoRA。为了方便使用,我后续制作的 LoRA 会尽量统一触发词风格:tutututu 加目标对象。这个模型的目标就是高跟鞋。差异提取法尽量剪掉不相关内容,让模型更集中在鞋子方向上。
推荐参数
- 确保正确加载 LoRA。
- CLIP 终止层数建议设置为 2。
- 推荐权重:0.4 到 0.9,建议从 0.65 开始。
- CFG Scale 可以从 7 开始尝试。
- 负面提示词不要堆太多,否则会影响 LoRA 效果。
- 原始例图中我没有使用 LoRA Block Weight,但如果需要局部控制,可以尝试打开。
- 如果是全身图,请确保脚和鞋子真的在画面里。
出图关键词
主触发词组:
tutututu, high heels
high heelsstiletto heelspointed-toe heelsankle strap heelsfashion high heelsluxury style shoesfull bodyfeet visiblestanding posefashion portrait
如果鞋子不明显,请先把镜头和构图说清楚,比如 full body、feet visible、standing pose、high heels。如果鞋子效果过强,或者影响到腿和衣服,先降低 LoRA 权重,不要一开始就堆很多负面词。
版本说明
v2.0:当前推荐版本。 我总觉得之前那个细节还有提升空间,所以用新的方法又做了一遍。提升是有的,但总体变化不是特别巨大。使用方法不变,仍然建议升级到 v2.0。
v1.0:第一个公开版本,已经有相对不错的还原度和低污染,但小目标细节还有提升空间。
常见问题
为什么鞋子不明显?
可能目标太小、被裁掉、被衣服挡住,或者提示词没有明确写鞋子。请使用全身构图,让脚可见,并补充高跟鞋提示词。
权重高以后脚或腿变奇怪怎么办?
先降低本 LoRA 权重。高跟鞋会和脚、腿、地面接触、姿势、镜头角度互相影响,权重过高可能影响附近区域。
为什么我出不了和例图一样的图片?
每个人使用的底模、采样器、LoRA、插件、显卡环境和参数都不一样,请把例图当作方向,不要强求完全一致。
声明
- 你需要对使用本模型生成的任何作品承担全部责任。
- 不要使用本模型制作或传播非法、有害、恶意、诽谤、诈骗或政治用途内容。
- 如果将本模型用于商业用途或定制合作,请提前联系我,谢谢。
日本語説明
これは ValXXXXno-style high heels LoRA です。ファッション画像や全身ポートレートで、高ヒールの形を出しやすくするためのフットウェア LoRA です。
- Trigger:
tutututu,high heels - Weight: 0.4 to 0.9, start around 0.65
- CLIP skip: 2
- CFG Scale: start around 7
高ヒールは全身画像では小さな対象になりやすいため、足が見える構図、full body, feet visible, standing pose, high heels などを入れると効果が出やすくなります。v2.0 は新しい方法で作り直した推奨バージョンです。細部は改善されていますが、使い方は以前と同じです。