Qwen Image Layered I2L Workflow with lightning 4 or 8 steps + Sageattention + GGUF + MultiGPU



詳細
ファイルをダウンロード
このバージョンについて
モデル説明
私のTGチャンネル - https://t.me/StefanFalkokAI
私のTGチャット - https://t.me/+y4R5JybDZcFjMjFi
ワークフローのテストに協力してくれたSD_Prompt_by_Artさんに感謝します - https://t.me/prompt_by_art
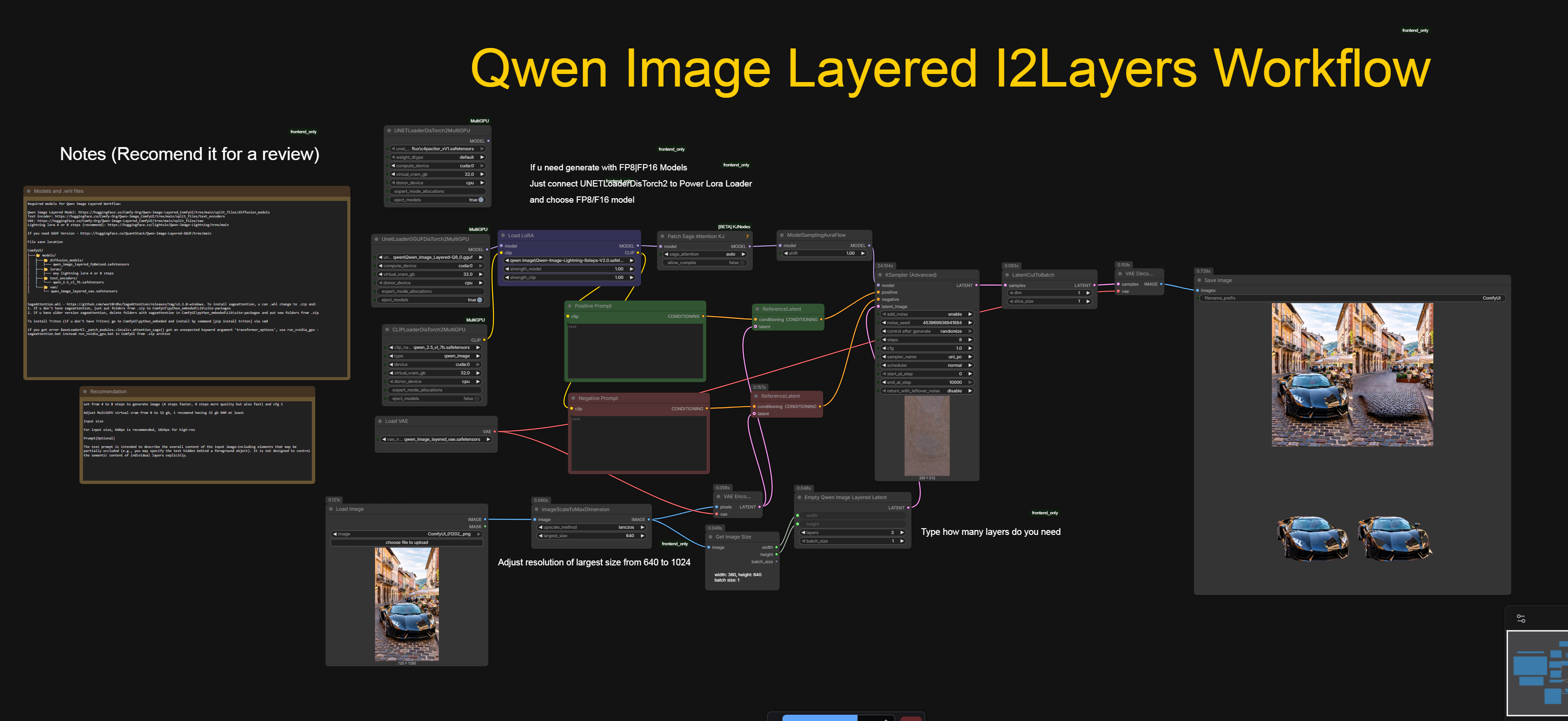
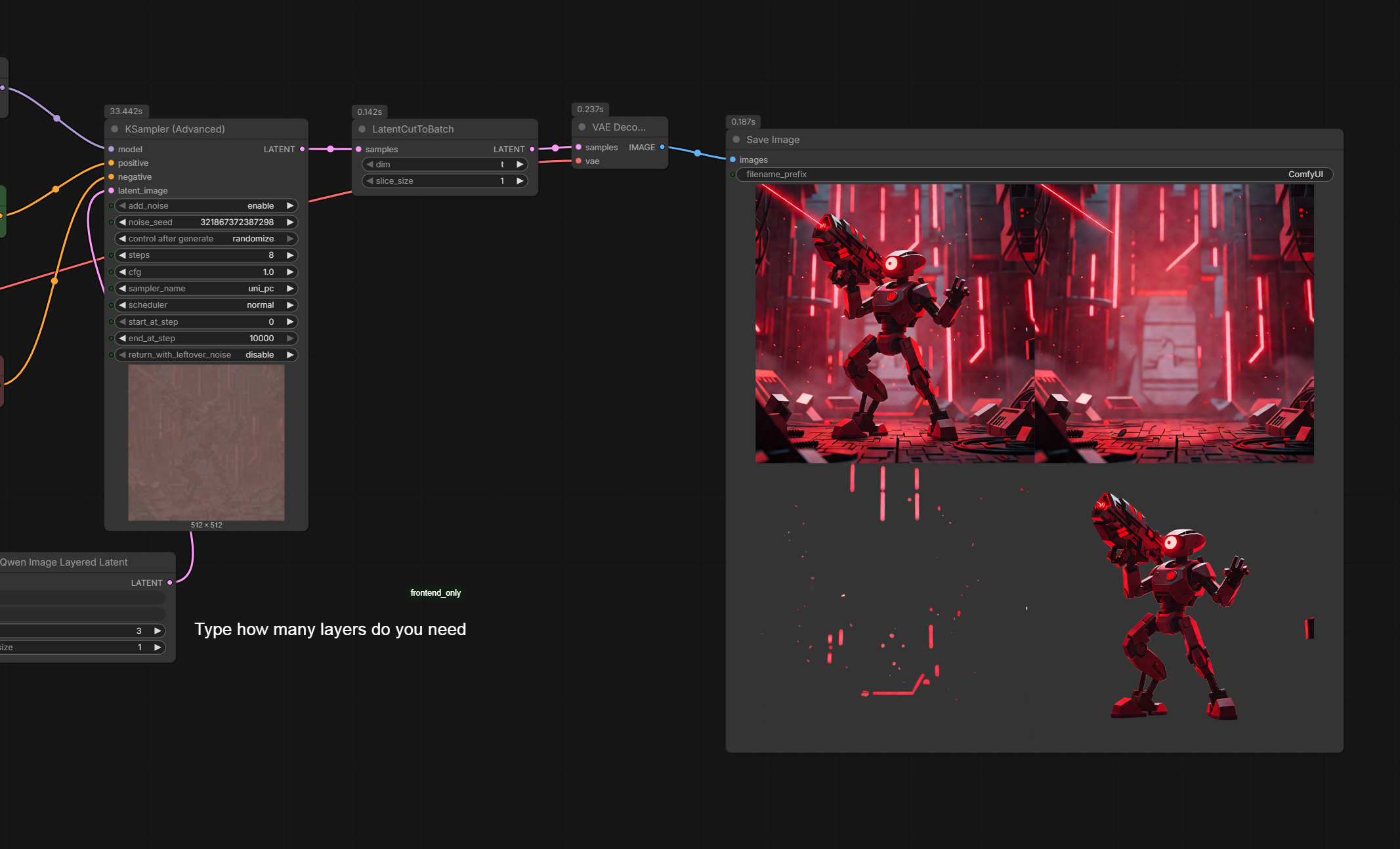
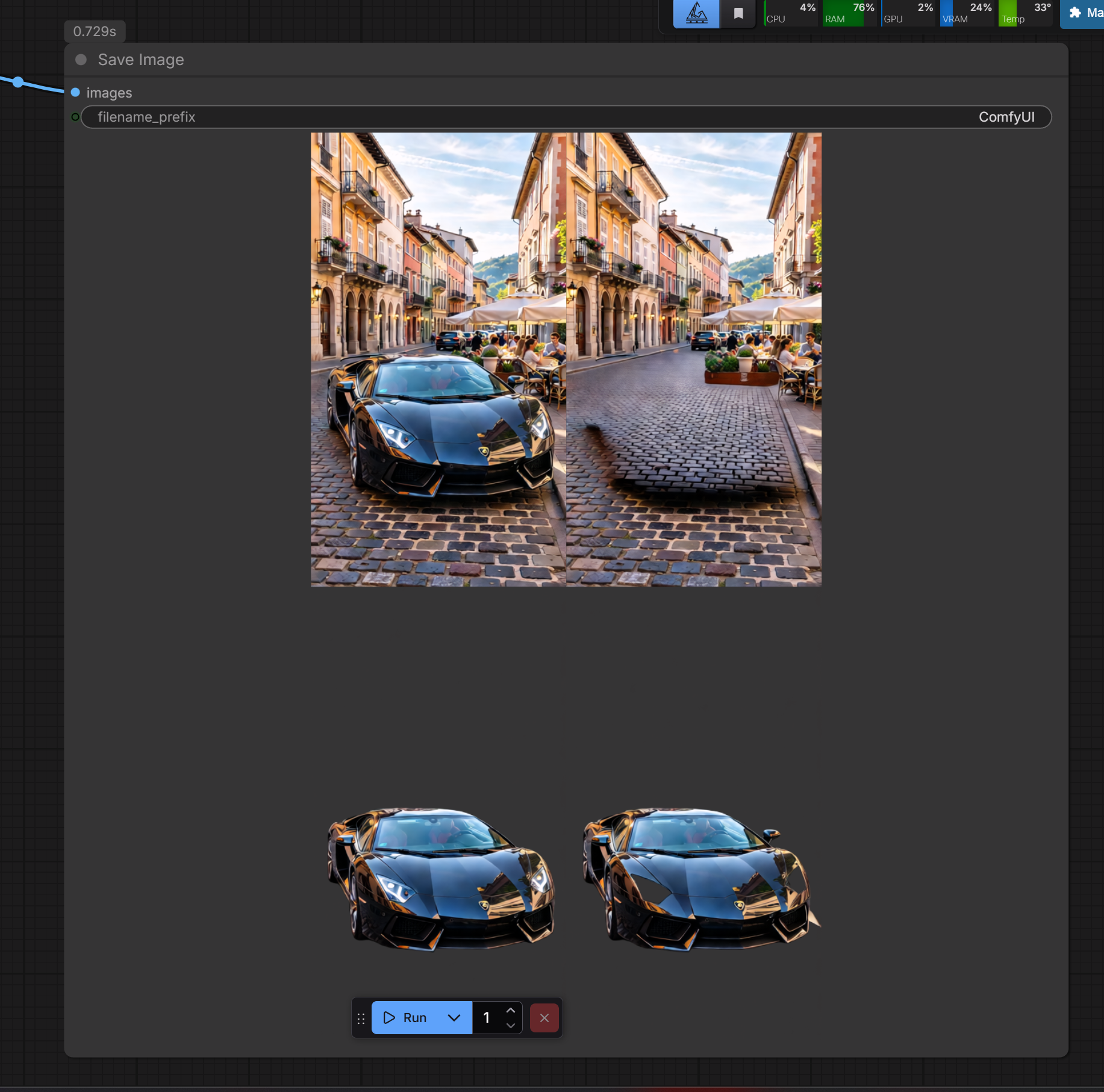
こんにちは!私はQwen Image Layered I2Lを使った作業ワークフローを紹介します。
Qwen Imageモデルを使用したワークフローを含めました。
Qwen Imageモデル(https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/tree/main/split_files/diffusion_models)、CLIP(https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/text_encoders)、VAE(https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/tree/main/split_files/vae)を準備する必要があります。
より高速な結果を得るために、Qwen ImageのLoRAを4ステップまたは8ステップで使用することをお勧めします。
GGUF Qwen Image Layered - https://huggingface.co/QuantStack/Qwen-Image-Layered-GGUF/tree/main
モデルが遅いことを警告します。5080では各イテレーションに10〜15秒かかります。これはVRAMやRAMの不足によるものではなく、ワークフローに軽量LoRAを含めました。
私のComfyUIビルドをダウンロードしてください:https://huggingface.co/datasets/StefanFalkok/ComfyUI_portable_torch_2.9.1_cu130_cp313_sageattention_triton。また、CUDA 13.0(https://developer.nvidia.com/cuda-13-0-0-download-archive)とVS Code(https://visualstudio.microsoft.com/downloads/)をダウンロードしてインストールする必要があります。
ワークフローで問題が発生した場合やトラブルがある場合は、コメントをお願いします。