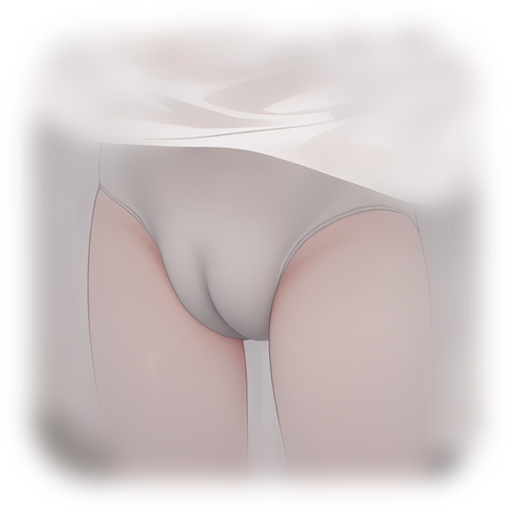
Cameltoe (for Anime)





Details
Download Files (1)
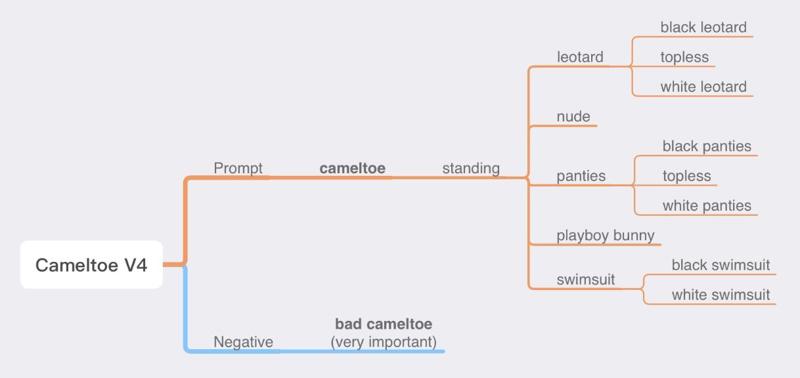
Model description
V4:
This is a model that focuses on anime-style, and it cannot function properly in realistic-style.
I recommend using the "JFCUColorBeta" main model.
LoRA weight: 0.4 ~ 0.8
Trigger word weight: 0.6 ~ 1.2
Manual:
This model can make the appearance of cameltoe plump and more beautiful.
V4 was trained using 198 high-res images with a resolution of 768*768. When using this model, please reset the "Height" value of the image to 768 pixels or more, or use the Hires.fix function.
I have replaced about 90% of the images in the V3 training set and trained V4 with these complete new images.
Compared to V3, V4 has better compatibility with anime-style models, and it can function properly in anime-style models with colorful, more brighter, and lower contrast.
Compared to V3, V4 has better compatibility with clothing, It can make the cameltoe plump without causing issues like nudity, clothing distortion, or incorrect colors.
V4 introduced 20 images for training the negative trigger word "bad cameltoe", after introducing the trigger word "bad cameltoe" to the Negative, V4 will have a higher lower limit compared to V3, and the output images will be more stable.
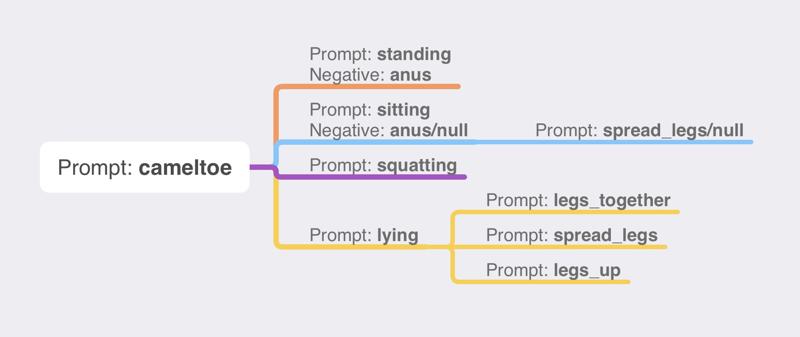
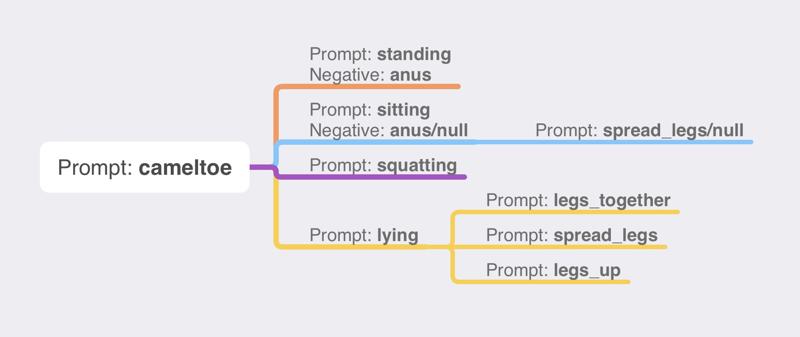
Compared to V3, V4 removed support for sitting, squatting, and lying postures, and only supports standing posture. I'm sorry that this is not a comprehensive upgrade, but I will reintroduce support for sitting, squatting, and lying postures in future updates, by then, they will have better compatibility with models, stable output images, and compatibility with clothing, just like the standing posture.
If you like this model, please give me a good review.
这是一个主攻动漫风格的模型,在写实风格下不能正常运行。
我推荐使用“JFCUColorBeta”主模型或“CuteYukiMix”主模型。
LoRA权重:0.4 ~ 0.8
触发词权重:0.6 ~ 1.2
使用手册:
我是一个专业的铜矿石炼制师,本模型就是为了炼制铜矿而生,铜和线就犹如鱼和水,没有肥美一线天的铜矿石根本就是瑕疵品!(尖叫),炼制的口诀我都藏在了展示图的负面提示词中,相信细心的炼制师们马上就能找到。另外在正面提示词中引入触发词“nice body”将会有更好的金属铜解剖学表现,在负面提示词中引入触发词“bad body”将会有效避免怪异的金属铜解剖学表现。
本模型可以令骆驼趾的外观更加饱满和美观。
V4使用了198张768*768分辨率的高清图片训练而成,在使用本模型时,请将图片的“高度(Height)”值调整为768像素或以上,或开启Hires. fix功能。
我替换了V3的训练集中约90%的图片,并用这些全新的图片训练出了V4。
V4相较于V3,有更好的对于动漫风格模型的兼容性,V4可以在色彩更加鲜艳、明亮、低对比度的动漫风格模型中正常运行。
V4相较于V3,有更好的服装兼容性,V4可以在凸显骆驼趾的同时不至于无法控制的出现裸体、崩坏的服装、错误的色彩等问题。
V4引入了20张图片用于训练负面触发词“bad cameltoe”,在负面提示词中引入触发词“bad cameltoe”之后, V4将会有相较于V3更高的下限,并且输出的图片更加稳定。
V4相较于V3,删除了对坐姿、蹲姿、躺姿的支持,V4仅保留了对站姿的支持,我很遗憾这并不是一次全方位的升级,但我会在后续的更新中重新加入对坐姿、蹲姿、躺姿的支持,届时它们将会同站姿一样,有更好的模型兼容性、出图稳定性、服装兼容性。
如果你喜欢本模型,请给我一个好评。
V3:
LoRA weight: 0.3 ~ 0.4
Trigger words weight: 0.6 ~ 1.2
Manual:
V3 is trained from 768*768 pixels pictures, when using this model, please reset the "Height" value of the picture to 768 pixels or more, or use the Hires. fix function.
LoRA权重:0.3 ~ 0.4
触发词权重:0.6 ~ 1.2
使用手册:
V3使用了768*768分辨率的高清图片训练而成,在使用本模型时,请将图片的“高度(Height)”值调整为768像素或以上,或开启Hires. fix功能。