Tutu's Eldreda Sunbringer (Zenless Zone Zero)/图图的艾尔妲·挽昼(绝区零)/Tutuのエルダ・サンブリンガー(ゼンレスゾーンゼロ)



















Details
Download Files (1)
Model description
无需配置,立刻在线使用本模型生图:
https://www.runninghub.cn/post/2070126352094810114/?inviteCode=rh-v0990
Oversea Workflow Online:
https://www.runninghub.ai/post/2070126352094810114/?inviteCode=rh-v0990
粉丝福利:点击右上角头像-邀请码-填入邀请码,领1000RH币,每天登录还有100币
邀请码:rh-v0990
国内站已经不支持本地解码,如需本地解码请去海外站:
注册链接:海外版RH(解码测试工作流,需开魔法):https://www.runninghub.ai/user-center/1936823199386537986/webapp?inviteCode=rh-v0990
粉丝福利,注册送1000点,每日登录100点,畅玩4090!体验48G的超能魅力!如果没有1000点,右上角绑定激活码,填写邀请码rh-v0990即可领取!
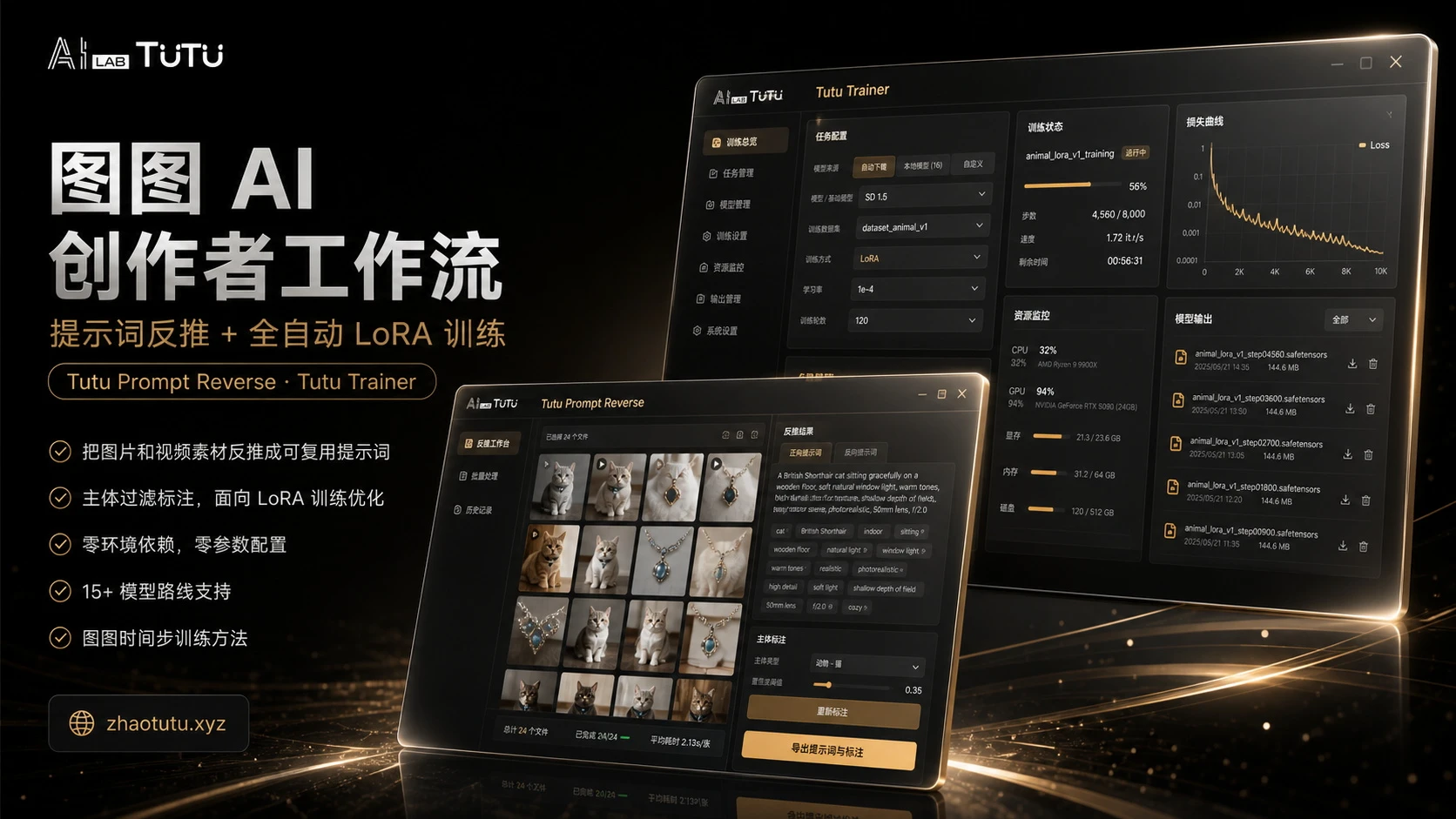
如果要做一个模型,但甚至连一张像样的素材图都没有,这个模型还能做吗?
答案是可以。
艾尔妲·挽昼女士全网几乎没有一张像样的图。这个模型是我通过官方 PV 里两秒钟的视频,反复研究细节后抠出来的。很久没有花两个小时做一个模型了,品质非常高。
本模型使用图图的图片视频提示词反推器制作素材,并对素材进行精细编辑处理,最终使用图图训练器训练完成。
图图的图片视频提示词反推器是一款 AI 驱动的图像与视频标注工具,专为模型训练标注优化,可一键批量生成高质量训练数据集,并快速反推图片与视频的提示词。
图图训练器是免费的 LoRA 训练工具,支持模型训练、数据集管理、模型资源管理、参数预设、训练检查和发布前整理。它的目标是让创作者不需要反复折腾环境和参数,也能更快、更稳定地训练出高质量 LoRA。
图图训练器:https://zhaotutu.xyz/downloads/tututrainer/
图图打标器:https://zhaotutu.xyz/downloads/tutuannotator/
Bilibili:https://space.bilibili.com/431046154
YouTube:https://www.youtube.com/@zhaotutu/videos
Telegram:https://t.me/zhaotutu
TikTok:https://www.tiktok.com/@zhaotututu
GitHub:https://github.com/zhaotututu
QQ:331506796
模型介绍
这是一个用于 Anima 的艾尔妲·挽昼角色 LoRA。艾尔妲·挽昼来自《绝区零》。
模型主要用于稳定艾尔妲·挽昼的角色外观与服装方向。
测试中,0.75 左右的权重比较稳定。
触发词:tutuwanzhou
推荐权重:0.5 - 1.0
建议起始权重:0.75
如果想要更稳定地复现角色和服装,建议把触发词放在提示词开头,并加入主要服装元素。
推荐提示词
tutuwanzhou, best quality, score_7, score_9, sensitive, very aesthetic, ultra detailed,
cleavage, blue_eyes, cape, white_hair, heterochromia, black_gloves, yellow_eyes, fingerless_gloves, hair_ornament, large_breasts, very_long_hair, thigh_strap, asymmetrical_clothes, bodysuit, strapless,
high_heels, asymmetrical_footwear, mole_on_thigh, boots, black_footwear,
负面提示词:
worst quality, low quality, score_1, score_2, score_3, blurry, jpeg artifacts,
更多出图案例,请参考例图。
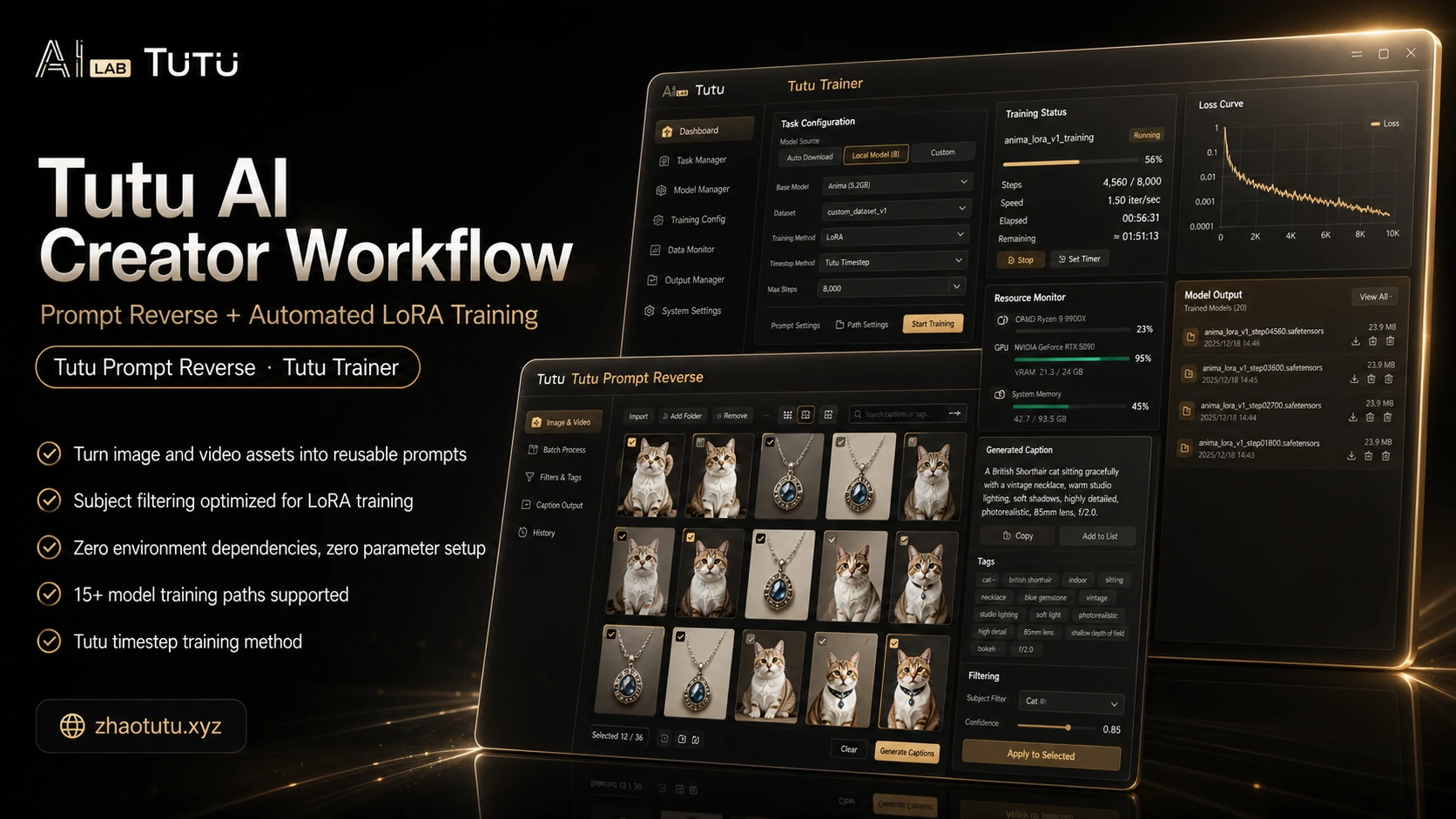
If you want to make a model, but you do not even have a single usable reference image, can the model still be made?
The answer is yes.
There is barely one decent image of Lady Eldreda Sunbringer anywhere online. This model was extracted from only two seconds of footage in the official PV, after repeatedly studying the details frame by frame. It has been a long time since I spent two hours on a single model. The quality is extremely high.
This model uses Tutu's Image/Video Prompt Reverser to create the source materials, then the materials are carefully edited and refined. The final model is trained with TutuTrainer.
Tutu's Image/Video Prompt Reverser is an AI-powered image and video annotation tool optimized for model training captions. It can batch-generate high-quality training datasets with one click and quickly reverse prompts from images and videos.
TutuTrainer is a free LoRA training tool that supports model training, dataset management, model resource management, parameter presets, training checks, and pre-release organization. Its goal is to help creators train high-quality LoRAs faster and more reliably, without repeatedly struggling with environments and parameters.
Official Website: https://zhaotutu.xyz/
TutuTrainer: https://zhaotutu.xyz/downloads/tututrainer/
Tutu Annotator: https://zhaotutu.xyz/downloads/tutuannotator/
Bilibili: https://space.bilibili.com/431046154
YouTube: https://www.youtube.com/@zhaotutu/videos
Telegram: https://t.me/zhaotutu
TikTok: https://www.tiktok.com/@zhaotututu
GitHub: https://github.com/zhaotututu
Email: [email protected]
QQ: 331506796
Model Introduction
This is an Eldreda Sunbringer character LoRA for Anima. Eldreda Sunbringer is from Zenless Zone Zero.
The model is mainly used to stabilize Eldreda Sunbringer's character appearance and outfit direction.
In testing, a weight around 0.75 is relatively stable.
Trigger word: tutuwanzhou
Recommended weight: 0.5 - 1.0
Suggested starting weight: 0.75
If you want to reproduce the character and outfit more consistently, it is recommended to place the trigger word at the beginning of the prompt and add the main outfit elements.
Recommended Prompt
tutuwanzhou, best quality, score_7, score_9, sensitive, very aesthetic, ultra detailed,
cleavage, blue_eyes, cape, white_hair, heterochromia, black_gloves, yellow_eyes, fingerless_gloves, hair_ornament, large_breasts, very_long_hair, thigh_strap, asymmetrical_clothes, bodysuit, strapless,
high_heels, asymmetrical_footwear, mole_on_thigh, boots, black_footwear,
Negative Prompt:
worst quality, low quality, score_1, score_2, score_3, blurry, jpeg artifacts,
For more sample images, please refer to the preview images.
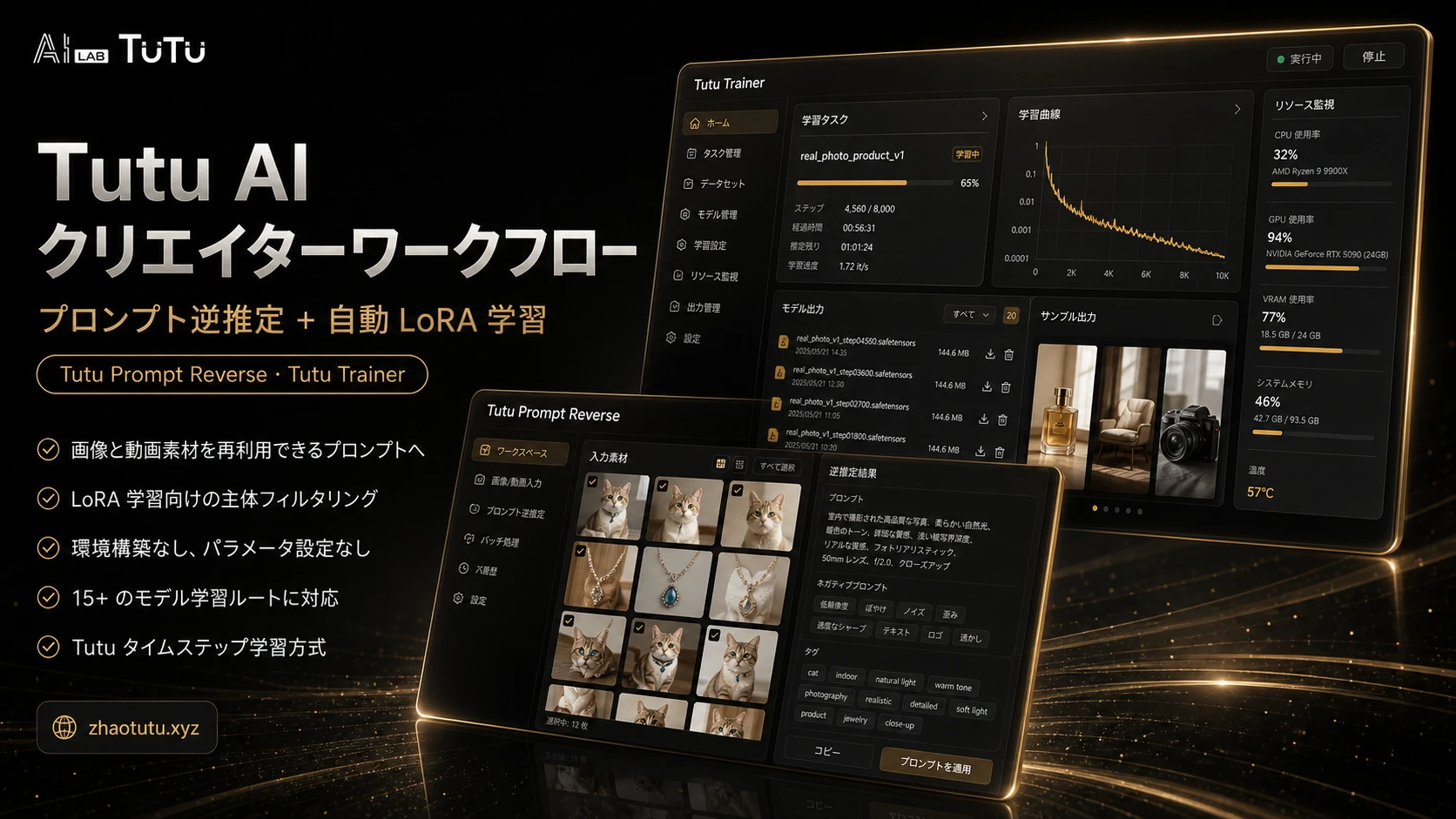
モデルを作りたいのに、まともな素材画像が1枚もない。そんな状態でもモデルは作れるのか?
答えは、できます。
エルダ・サンブリンガー様は、ネット上にまともな画像がほとんどありません。このモデルは、公式PVのわずか2秒ほどの映像をもとに、細部を何度も研究しながら切り出して制作したものです。1つのモデルに2時間かけたのは久しぶりです。品質は非常に高いです。
このモデルは、Tutuの画像・動画プロンプト逆推定ツールで素材を作成し、その素材を細かく編集・調整したうえで、最終的にTutuTrainerで学習して完成させました。
Tutuの画像・動画プロンプト逆推定ツールは、AIを活用した画像・動画アノテーションツールです。モデル学習用のキャプション作成に最適化されており、高品質な学習データセットを一括で生成でき、画像や動画からプロンプトを素早く逆推定できます。
TutuTrainerは無料のLoRA学習ツールです。モデル学習、データセット管理、モデルリソース管理、パラメータプリセット、学習チェック、公開前の整理に対応しています。クリエイターが環境やパラメータで何度も悩まず、より速く、より安定して高品質なLoRAを学習できるようにすることを目指しています。
公式サイト: https://zhaotutu.xyz/
TutuTrainer: https://zhaotutu.xyz/downloads/tututrainer/
Tutu Annotator: https://zhaotutu.xyz/downloads/tutuannotator/
Bilibili: https://space.bilibili.com/431046154
YouTube: https://www.youtube.com/@zhaotutu/videos
Telegram: https://t.me/zhaotutu
TikTok: https://www.tiktok.com/@zhaotututu
GitHub: https://github.com/zhaotututu
Email: [email protected]
QQ: 331506796
モデル紹介
これはAnima用のエルダ・サンブリンガーのキャラクターLoRAです。エルダ・サンブリンガーは『ゼンレスゾーンゼロ』のキャラクターです。
このモデルは主に、エルダ・サンブリンガーのキャラクター外見と衣装の方向性を安定させるために使用します。
テストでは、0.75前後のウェイトが比較的安定していました。
トリガーワード: tutuwanzhou
推奨ウェイト: 0.5 - 1.0
おすすめ開始ウェイト: 0.75
キャラクターと衣装をより安定して再現したい場合は、トリガーワードをプロンプトの先頭に置き、主要な衣装要素を追加することをおすすめします。
推奨プロンプト
tutuwanzhou, best quality, score_7, score_9, sensitive, very aesthetic, ultra detailed,
cleavage, blue_eyes, cape, white_hair, heterochromia, black_gloves, yellow_eyes, fingerless_gloves, hair_ornament, large_breasts, very_long_hair, thigh_strap, asymmetrical_clothes, bodysuit, strapless,
high_heels, asymmetrical_footwear, mole_on_thigh, boots, black_footwear,
ネガティブプロンプト:
worst quality, low quality, score_1, score_2, score_3, blurry, jpeg artifacts,
さらに多くの生成例は、プレビュー画像をご参照ください。