ComfyUI Workflow | AnimateDiff + IPAdapter

詳細
ファイルをダウンロード
モデル説明
ComfyUIワークフロー - AnimateDiff と IPAdapter
このComfyUI AnimateDiff と IPAdapter ワークフローは、ComfyUI専用のプラットフォームであるRunComfy, ComfyUI Cloudで簡単に実行できます。必須のノードとモデルはすべて事前に設定されており、すぐに使用可能です!
さらに、このComfyUI オンラインサービスでは、他にも多くの優れたワークフローをご利用いただけます。
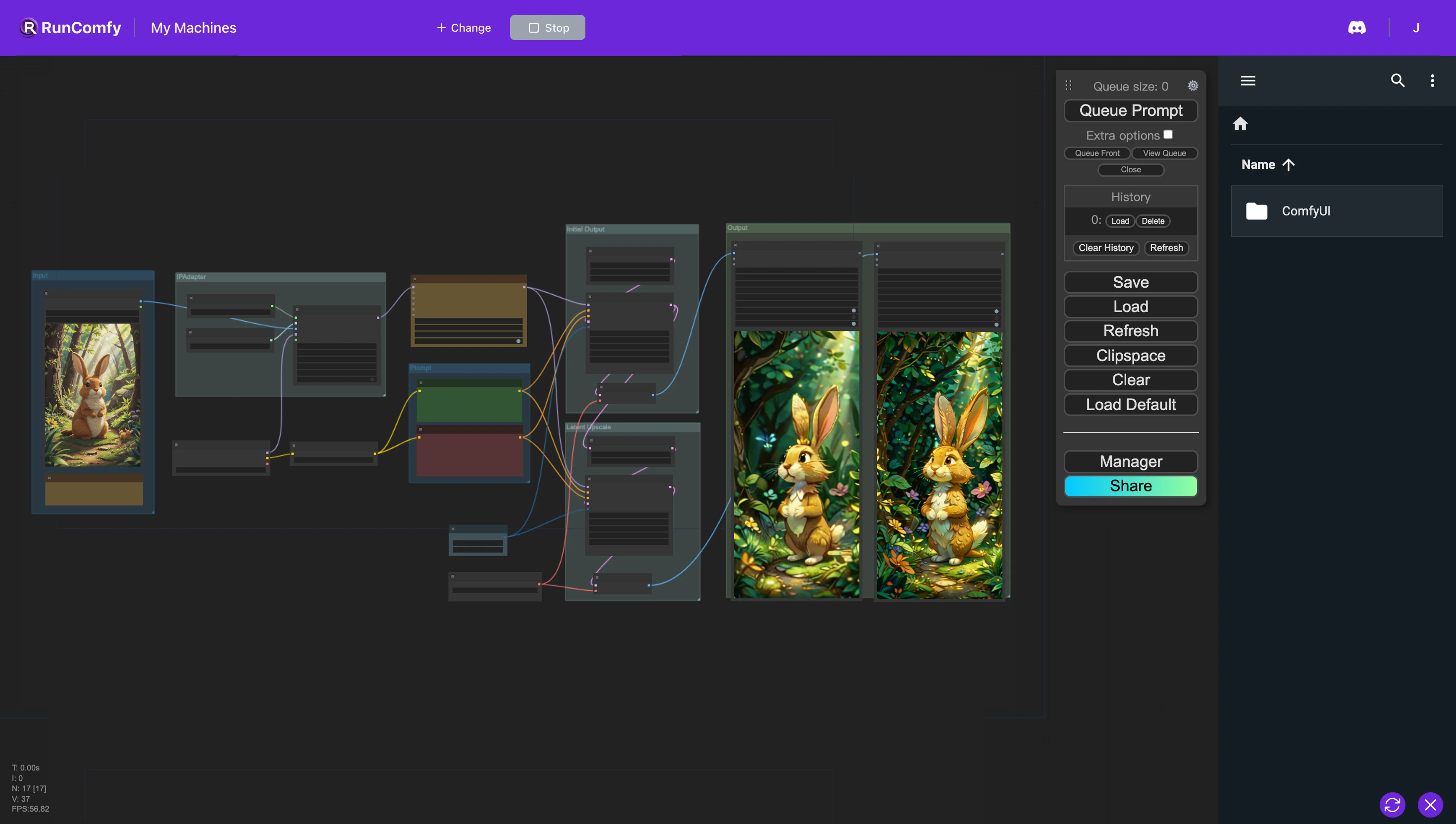
このComfyUIワークフローは、AnimateDiffを用いて動的な調整を行い、IP-Adapterで画像ベースのプロンプトを活用することで、アニメーションおよび画像のスタイル、構図、詳細品質を向上させ、アニメーション作成を効率化します。
AnimateDiffの概要
AnimateDiffは、Stable Diffusionモデルとモーション技術を用いて静止画像とテキストをアニメーション動画に変換するAIツールです。コーディングや特別なハードウェアなしでアニメーション作成を簡素化し、オンラインで無料で利用可能です。
モデルバージョン
AnimateDiffは、Stable Diffusion V1.5用のAnimateDiff v1、v2、v3、およびSDXL用のAnimateDiff sdxlをサポートしており、複雑なアニメーションに異なるモーションモデルを使用できます。
アニメーション長のカスタマイズ
コンテキストバッチサイズを調整することで、任意の長さのアニメーションを作成でき、アニメーションの長さや遷移に柔軟性をもたらします。
遷移の滑らかさ
Uniform Context Length機能は、アニメーションセグメント間の滑らかな遷移を保証し、シーンの流れをユーザーが制御できるようにします。
モーションダイナミクス
AnimateDiff v2は、映画的なカメラ効果用のモーションLoRAsを導入し、アニメーションに動的な視覚的層を追加します。
IP-Adapterの概要
IP-Adapterは、画像プロンプトをテキストから画像生成モデルに統合し、テキスト入力のみの制限を超えて、テキストとビジュアルの両方の入力を組み合わせて画像生成を簡素化します。
v1.5モデル
ip-adapter_sd15: 画像とテキストの強化用標準モデル。
ip-adapter_sd15_light: リソース消費が少ないタスク向けの効率版。
ip-adapter-plus_sd15: 参照画像の忠実度を向上。
ip-adapter-plus-face_sd15: 顔の特徴に特化。
ip-adapter-full-face_sd15: 詳細な顔のスワップに焦点。
ip-adapter_sd15_vit-G: Vision Transformer BigGを使用して詳細な特徴抽出。
SDXLモデル
ip-adapter_sdxl: 複雑なプロンプト用ベースモデル。
ip-adapter_sdxl_vit-h: SDXLの機能と効率のバランス。
ip-adapter-plus_sdxl_vit-h: 詳細度と品質を向上。
ip-adapter-plus-face_sdxl_vit-h: 顔の詳細精度をターゲット。
FaceIDモデル
FaceID: InsightFaceを使用した顔埋め込み。
FaceID Plus: InsightFaceとCLIPで顔の特徴を強化。
FaceID Plus v2: CLIP統合を強化したFaceID Plusのアップグレード版。
FaceID Portrait: 多様性のために複数の顔画像をサポート。
SDXL FaceIDモデル
FaceID SDXL: FaceIDをSDXL用に適応。
FaceID Plus v2 SDXL: 高精細画像をより高い忠実度で提供。