Style Components (ComfyUI & Forge)

Details
Download Files (1)
About this version
Model description
Style Components (ComfyUI & Forge)
Please go to the GitHub pages for the Forge extension / ComfyUI nodes for instructions and more information. From now on, minor changes will not be added to this Civitai page. Please follow the GitHub pages for the latest updates.
Old description for v0.2.0
Style Components (Forge extension)
Style control for Stable Diffusion 1.x and SDXL anime models.
(you don't actually need to download the model files, just try the Colab demo.)
From v0.1.0, a Forge extension is made available.
In v0.2.0, an additional Forge extension supporting exclusively SDXL (AutismmixPony) is added. Note that now the style components have different meanings from v0.1 (SD1).
What is this?
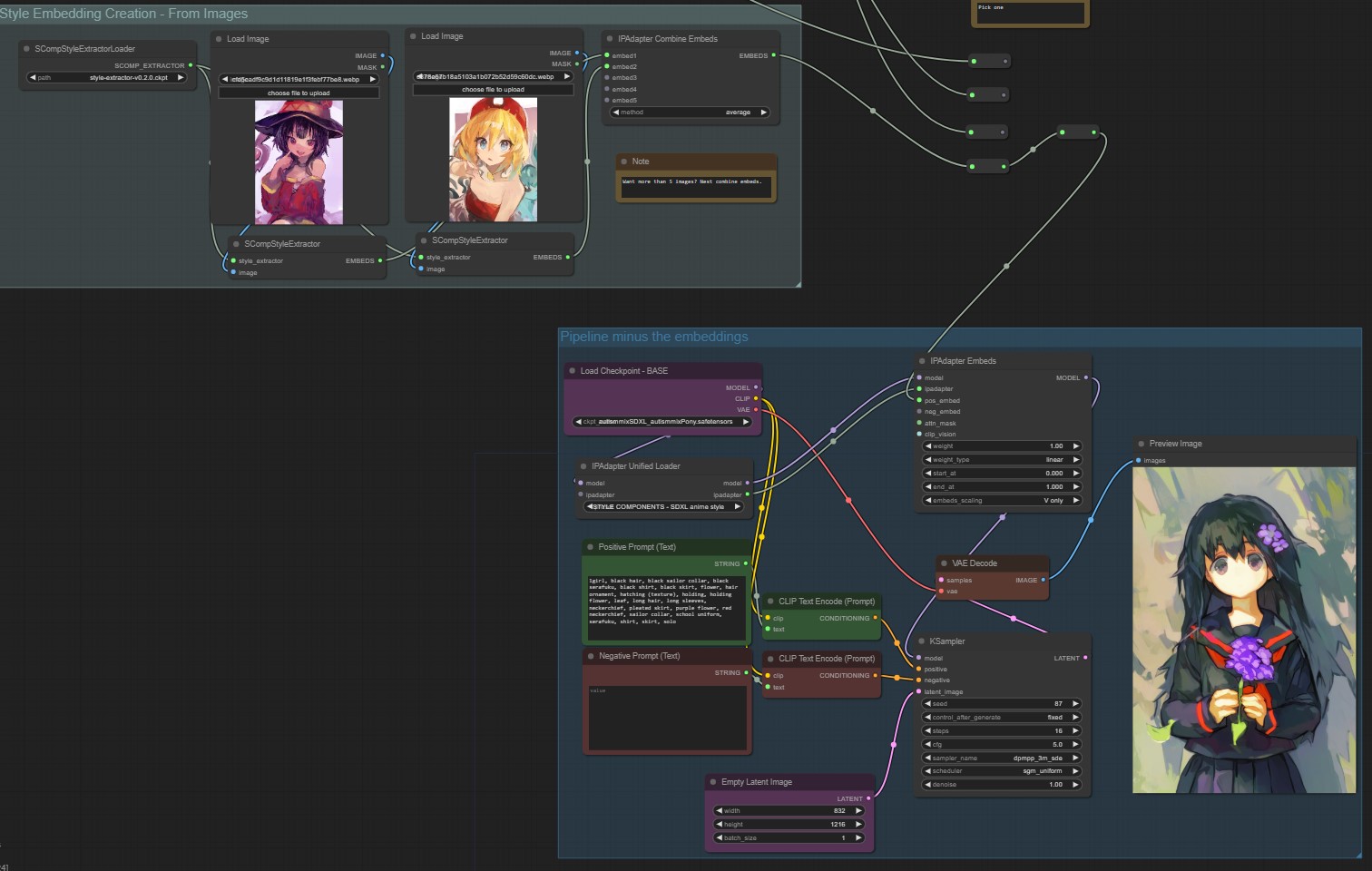
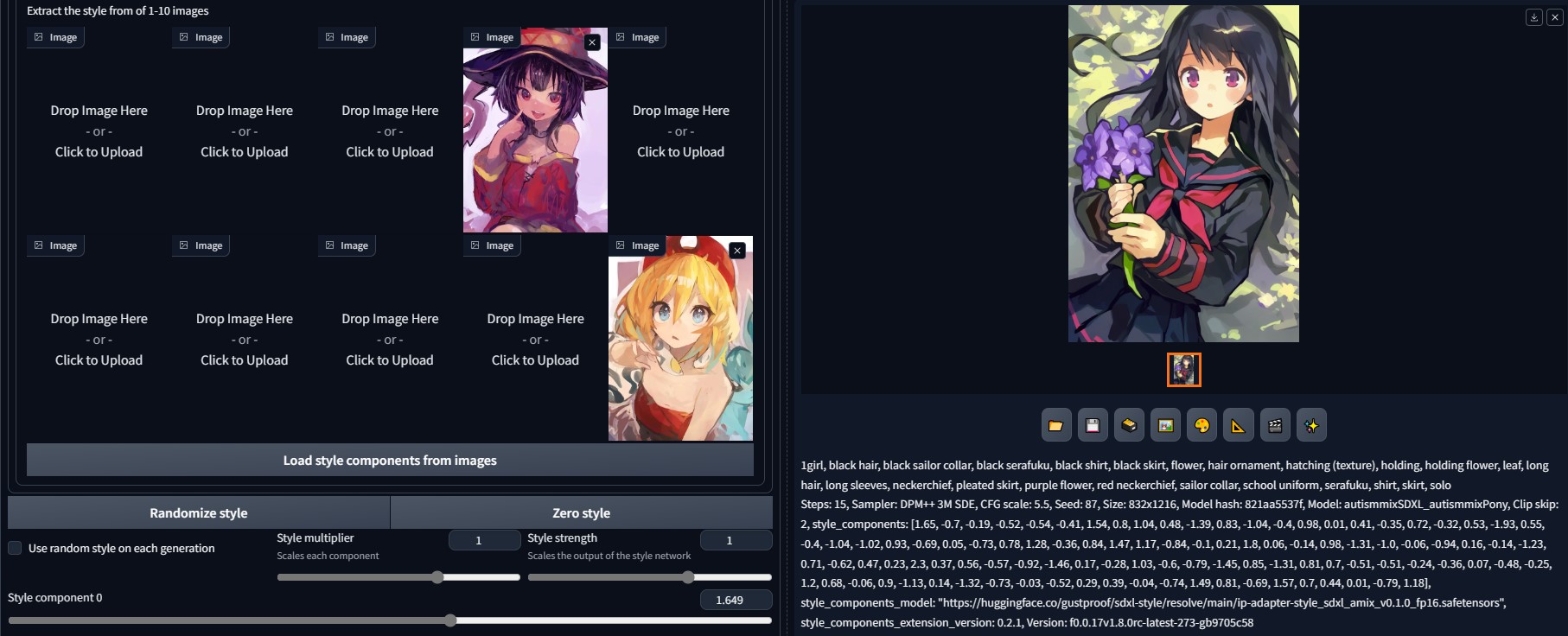
It is IP-Adapter, but for (anime) styles. Instead of CLIP image embeddings, the image generation is conditioned on style embeddings, which can either be extracted from images or created manually. The component values can be viewed in PNG info.
Why?
Currently, the main means of style control is through artist tags. This method reasonably raises the concern of style plagiarism. By breaking down styles into interpretable components that are present in all artists, direct copying of styles can be avoided. Furthermore, new styles can be easily created by manipulating the magnitude of the style components, offering more controllability over stacking artist tags or LoRAs.
Additionally, this can be potentially useful for general purpose training, as training with style condition may weaken style leakage into concepts. This also serves as a demonstration that image models can be conditioned on arbitrary tensors other than text or images. Hopefully, more people can understand that it is not necessary to force conditions that are inherently numerical (aesthetic scores, dates, ...) into text form tags.
How do I use it?
Currently, a Colab notebook with a gradio interface is available. As this is only an experimental preview, proper support for popular web UIs will not be added before the models reach a more stable state.
Download the Forge extension and extract it under the extensions directory. Make sure to check the Enable checkbox. For SD V1, use v0.1.0; for SDXL, use v0.2.0.
You can create style embeddings by manipulating the slider values, or importing from regular images. Reference grids for the effects of each component are provided in the preview images.
SDXL tips: The model is trained on AutismmixPony. This is the only currently supported model. The adapter is not trained with Pony tags (source_anime, score_9, ...), so these tags can be omitted when prompting.
Technical details
First, a style embedding model is created by Supervised Contrastive Learning on an artists dataset. Then, from the learned embeddings, the first components of a PCA are extracted. Finally, a modified IP-Adapter is trained on anime-final-pruned using the same dataset with WD1.4 tags and the projected embeddings. The training resolution is 576*576 (SD1) / 1024 * 1024 (SDXL) with variable aspect ratios.
For the SDXL version, the designed is refined to decouple style manipulation from the conditioning. The style extractor is updated with a larger dataset and more parameters.
Due to how the model was trained, the style embeddings capture more of the local style rather than global composition. Also, no efforts were made to ensure the faces were included in the crops in training, so style embeddings may not capture well the face or eye style.
Acknowledgements
This is largely inspired by Inserting Anybody in Diffusion Models via Celeb Basis and IP-Adapter. Training and inference code is modified from IP-Adapter (license).