AiARTiST Fully Bloomed 梦想绽放 LoRA XL版本




















詳細
ファイルをダウンロード (1)
モデル説明
AiARTiST Fully Bloomed 梦想绽放 LoRA模型 XL版本
文件名:AiARTiST_FullyBloomed.safetensors
----------------------------------------------------------------------
评论区如果不停止刷屏,我们将逐步放出Uncle_Martin1977 抄袭我们模型的完整记录,
所有来这里喷的朋友,请看一下我们模型的出图质量,你们认为融合一个劣质模型会让
我们的模型质量更好吗?所有训练参数都在Metadata中保留,我们从不主动隐藏。
这个LoRA之所以制作并发布,是因为很多模型作者看不惯某些恶俗团伙的行事做派,
一起帮忙出训练集,提供训练思路,并有目的的发布出来。
就为了不希望看到很多模型作者为了一点点个人收益,胡乱抄袭别人的想法和创意。
让我们一起维护中文模型圈的发展秩序!
----------------------------------------------------------------------
Bloomed of Mind's Canvas
放下执念,迎来花开
在生命的织锦中,有一个深刻的教训
——放下我们根深蒂固的依恋,为新的开始让路。
旅程不是紧紧抓住每一片叶子或花瓣,而是让经历的起伏变成我们体内孕育成长的种子。
“Letting Go of Obsessions, Welcoming the Bloom”它代表了一个变革的过程,在这个过程中,我们将自己从过去的遗憾、未来的焦虑和对无法实现的完美的不懈追求中解脱出来。就像一棵树在秋天落叶,为春天的复兴做准备一样,我们必须释放不再对我们有用的东西,为鲜花的绽放创造空间。
当我们不再抗拒生活的自然节奏时,我们发现真正的美是在放弃控制的过程中展现出来的。每次我们剥去一层依恋,我们就更接近于理解存在的复杂和谐,痛苦与快乐、损失与收获交织成一个宏伟的设计。
因此,“放下执念,迎接绽放”不仅仅是一句话;更是一种哲学,是一种开启自我发现之旅的邀请。它鼓励拥抱变化,培养韧性,并庆祝生命本身的短暂。因为只有放下执着的重担,我们才能充分地呼吸生命中盛开花朵的芳香。
(以上文字由AI生成)
In the tapestry of life, there lies a profound lesson—letting go of our deep-seated attachments to make way for the blossoming of new beginnings. The journey is not about clutching tightly onto every leaf or petal that comes our way but rather allowing the ebb and flow of experiences to nurture the seeds of growth within us.
"Letting Go of Obsessions, Welcoming the Bloom," speaks to this very essence. It represents the transformative process where we untangle ourselves from the chains of past regrets, future anxieties, and the relentless pursuit of unattainable perfection. Just as a tree sheds its leaves in autumn to prepare for the rejuvenation of spring, we must release what no longer serves us to create space for fresh blooms to unfold.
In this dance of existence, the art of surrender becomes the catalyst. When we cease to resist life's natural rhythm, we find that it is in the act of relinquishing control that true beauty unfolds. Each time we peel away a layer of attachment, we come closer to understanding the intricate harmony of existence, where pain and joy, loss and gain, are interwoven into a grand design.
Thus, 'Putting Down Attachments, Welcoming Flowering' is more than just a phrase; it is a philosophy, an invitation to embark on a voyage of self-discovery. It encourages embracing change, cultivating resilience, and celebrating the ephemeral nature of life itself. For it is only when we lay down our heavy burdens of stubborn clinging that we can fully inhale the sweet fragrance of life's abundant blossoms.
( Generated by AI )
----------------------------------------------------------------------
这是一个能够与各大写实模型配合良好的风格化艺术摄影模型的SDXL版本,
能为大模型或者是其他辅助LoRA风格中的人像部分拍摄盛放般的艺术照片。
使用非常简单,根据需要选择一个风格模板,使用风格词触发一个版式,
修改排版中的元素,就可以生成一念绽放特色艺术摄影了,期待您的创意!
This is an SDXL version of a stylized photography model that can work well with various realistic models,Able to take stunning art photos for large models or other auxiliary LoRA style portraits.
It is very easy to use. Choose a style template according to your needs, and use style words to trigger a layout,By modifying the elements in the layout, you can generate a unique artistic photography feature called "One Mind Blooming". Looking forward to your creativity!
----------------------------------------------------------------------
触发词:AiARTiST,Petal skirt (or Natural language description)
Trigger word:Natural language description
人物召唤词:a woman, a girl, a close up of a flower,a digital painting,an asian women
风格描述词:flower bloom, butterfly Theme, Blue Theme, ocean Theme, water Theme
画面元素词:cloud sea,low clouds, light growing, white flower, close-up , black background
and more , example:
parameters 1
flower bloom, light growing , flower bloom ,Petal skirt , low clouds ,glowing neon color,at night,1girl,solo,sea,black hair,ponytail,looking at viewer,long hair,up,lips,sash,water splashing,hair ornament,realistic,wide sleeves,surrealist,flowers,bloom,smoke, <lora:AiARTiST-Fullybloomed-mix3:0.75>
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2921893757, Size: 512x1024, Model hash: d8fd60692a, Model: LEOSAM HelloWorld 新世界 SDXL真实感大模型v5.0, Variation seed: 3524987395, Variation seed strength: 0.58, Seed resize from: 1200x1016, Denoising strength: 0.4, Clip skip: 2, ADetailer model: face_yolov8s.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer version: 23.11.1, Hires upscale: 1.5, Hires upscaler: Latent, Lora hashes: "AiARTiST-Fullybloomed-mix3: c1e0600b4635", Mask blur: 4, Inpaint area: Only masked, Masked area padding: 32, Version: f0.0.17v1.8.0rc-latest-269-gef35383b
parameters 2
Fashion Magazine Cover,still photography, looping video, mesmerizing movement, captivating visuals, seamless blend, engaging storytelling, Vorticism, angular forms, dynamic movement, bold geometry, fragmented shapes, striking contrasts, modernist influence, nature,flowers,modern art,pink and grey, amazing, unreal background, art by (Alessio Albi:1.1),soft lighting, Happy emotions,1girl asian,(close up),the dress like a smoke,long hair,(fractal art) ,extremely detailed,the most beautiful form of chaos, elegant, a brutalist designed, vivid colours, romanticism,details in the dark,Petal skirt ,Petal vein,
, <lora:AiARTiST-Fullybloomed-mix3:0.75>
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3546699821, Size: 512x1024, Model hash: d8fd60692a, Model: LEOSAM HelloWorld 新世界 SDXL真实感大模型v5.0, Variation seed: 476024900, Variation seed strength: 0.58, Seed resize from: 1200x1016, Denoising strength: 0.4, Clip skip: 2, ADetailer model: face_yolov8s.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer version: 23.11.1, Hires upscale: 1.5, Hires upscaler: Latent, Lora hashes: "AiARTiST-Fullybloomed-mix3: c1e0600b4635", Mask blur: 4, Inpaint area: Only masked, Masked area padding: 32, Version: f0.0.17v1.8.0rc-latest-269-gef35383b
parameters 3
AiARTiST a beautiful woman in a blue dress with pink flowers butterfly Theme flower bloom Petal skirt <lora:AiARTiST-Fullybloomed-mix3:1>
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3414939050, Size: 512x1024, Model hash: d8fd60692a, Model: LEOSAM HelloWorld 新世界 SDXL真实感大模型v5.0, Denoising strength: 0.4, Clip skip: 2, ADetailer model: face_yolov8s.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer version: 23.11.1, Hires upscale: 1.25, Hires upscaler: Latent, Lora hashes: "AiARTiST-Fullybloomed-mix3: c1e0600b4635", Mask blur: 4, Inpaint area: Only masked, Masked area padding: 32, Version: f0.0.17v1.8.0rc-latest-269-gef35383b
「 建议直接抄样图提示词,然后根据需要增添修改细节词 」
推荐lora权重:0.65~0.85,中值 0.75
推荐采样步数:25~30 CFG scale: 5~8
推荐采样方法:DPM++ 2M Karras ,Eular a,DIMM
欢迎尝试其他采样方法,FP8推理可以正常出图,显存占用低。
推荐分辨率:任意分辨率,文生图界面「必须」选中1.5倍高分辨率修复
如果图片尺寸还是不够,发送到「后期处理」2倍Resize高清化
图片后期处理高清化设置: 8x_NMKD-Superscale_150000_G 可叠加
4x-UltraSharp 或 R-ESRGAN 4x+ Anime6B
测试问题请留言,业务合作 +V 联系 18008889980 +Q 517131 +Q群 103787031
AiARTiST | Metaverse 中国·山东 数字人/AiGC/元宇宙方向
RED-OMNI Kontext Editor 5/31/2025
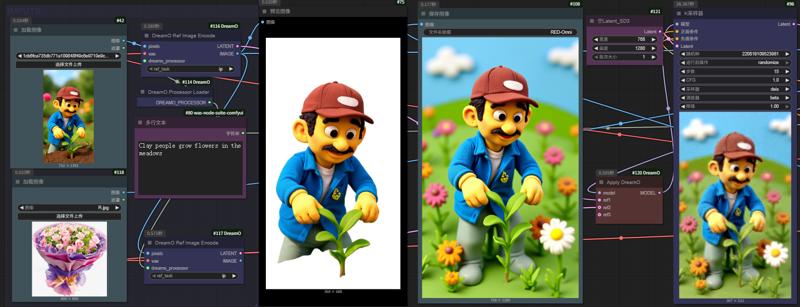
Supported Tasks
IP: Similar to IP-Adapter, supports characters, objects, and animals. Uses VAE-based feature encoding for higher fidelity and better character identity preservation than previous methods.
ID: Focuses on facial identity, similar to InstantID and PuLID. Offers higher facial fidelity but introduces more model contamination than PuLID.
Tip: If the face appears too glossy, reduce the guidance scale.Try-On: Supports virtual try-on for tops, bottoms, glasses, and hats, including multiple garments. Generalizes well to unseen multi-garment and ID+garment combinations despite limited training data.
Style: Similar to Style-Adapter and InstantStyle. Style consistency is less stable and cannot be combined with other conditions currently. Improvements are in progress.
Multi Condition: Combines ID, IP, and Try-On for creative outputs. Feature routing constraint minimizes conflicts and entanglement among entities.
ComfyUI: Native support via ComfyUI-DreamO
进阶用法 Advanced Usage
OmniConsistency 是由 Show Lab, National University of Singapore 开源的一致性风格转绘模型与算法组合。由于同样是使用了 FLUX.1 dev 作为训练基座,经过测试,DreamO 与OmniConsistency 的用法上可以通过 ComfyUI 做到“梦幻联动”。
OmniConsistency is a combination of consistency preserving style transfer models open-source by Show Lab, National University of Singapore. Due to the use of FLUX. 1 dev as the training base, it has been tested that DreamO and OmniConsistency can achieve a "dreamlike linkage" in their usage through ComfyUI workflow.
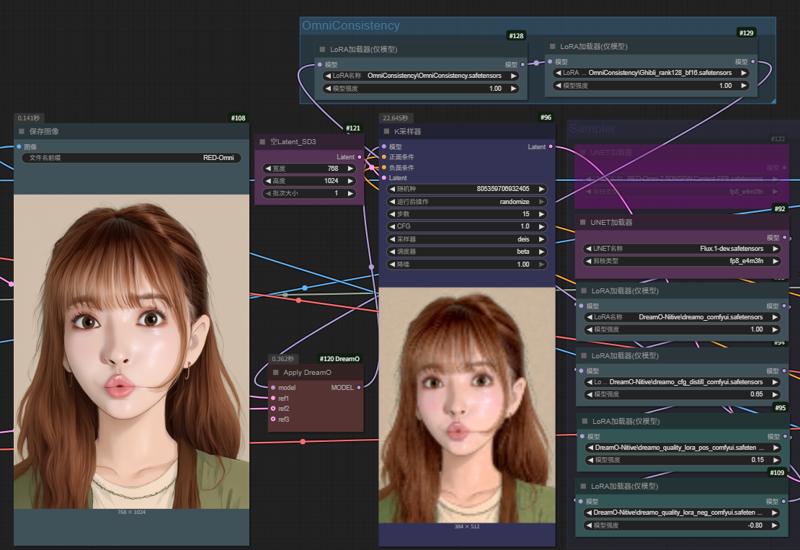
只需要将 showlab/OmniConsistency 仓库中的一致性LoRA与22种不同风格的LoRA,接入 RED-Omni(2.5DNSFW) 或者通过 DreamO 原生方式接入 Flux.1 dev 模型组,即可同时进行参考内容的自然语言编辑与风格转绘。[ 更多用法期待您去发掘 ]
Just connect the Omniconsistency LoRA in the showlab/OmniConsistency repository with 22 different styles of LoRA, and connect them to RED-Omni (2.5DNSFW) or connect them to the Flux. 1 dev model group through DreamO native mode to simultaneously perform natural language editing and style transfer of reference kontext.
[ More Fun is waiting for explorer ] Looking forward to BFL Kontext (dev)
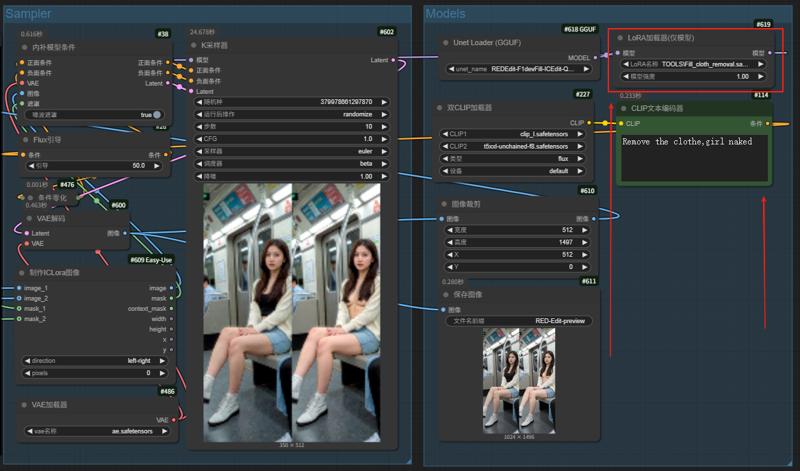
REDEdit IC (FP8) 5/11/2025
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
ICEdit 多模态控制器(IC引导下的图像编辑)
![]()
基于 Flux.tools-Fill 最低仅需 6G 显存
近期出现的多模态控制器对C端用户越来越不友好
动不动就要20-30+显存,望而却步
开发团队在体会了C端玩家社群暴击之后,非常积极的提供了官方工作流(赞👍)
After experiencing the critical hits in the C-end player community, the development team actively provided the official workflow.
并且给出了更完善的客户端使用方法:
You need to add the fixed pre-prompt "A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}" before inputing the edit instructions, otherwise you may get bad results! (This is mentioned in the paper!) Datou has updated his ComfyUI workflow, have a try! (The code for the Hugging Face gradio demo already embeds this prompt. So, you can simply input the editing instructions without additional setup.)
The width of the input image must resize to 512 (no restriction to height).
Please use the Normal LoRA not the MoE-LoRA, because the MoE-LoRA cannot be correctly loaded with ComfyUI lora loader.
官方normal(non-moe)LoRA:RiverZ/ICEdit-normal-lora at main
非常推荐在本地搭建独立的推理环境(或使用 十字鱼 提供的整合包)
5.11 🔥 更新RED-Edit v1.1(基于ICEdit normal LoRA) 多指令优化
5.11 🔥 右侧下载列表中的 Trainning data 工作流更新
同时执行脱掉衣服,带上太阳镜和口罩,成功率大幅提升🔥 画质优化 推荐步数15步
Prompts:A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {Women's naked,Wearing sunglasses,facemask}
进阶玩法 Advanced users:叠加 Flux.fill LoRas 可以获得更稳定的修改结果
Object Removal Flux Fill v2
@xiaozhijason / Object Removal Flux Fill v2 - v2.0 | Flux LoRA | Civitai
Fill.LoRas Model Description by xiaozhi
This is an Object Removal LoRA fine-tuned from Flux Fill Dev model.
The lora is designed to remove objects from specified masked areas, making it useful for image editing tasks where unwanted objects need to be erased seamlessly.
This lora is inspired by Object Drop. Object Drop achieved amazing result on removing objects and I want to try it with Flux fill model.
Due to the computing power limitation, this alpha version only trained on very small dataset.
If anyone interested in and want to sponsor the computing power, please contact me.
Fill-LoRas author Contact
Twitter: [@Lrzjason](https://twitter.com/Lrzjason)
Email: [email protected]
CivitAI: https://civitai.com/user/xiaozhijason
ICEdit & 小志 让我们重新相信光
RED-Edit 是在 RED-Fill (NSFW) 基础上合并了 ICEdit 训练权重,最低仅需 8步 推理
工作流及模型文件在下载列表中,工作流打包为 "Trainning data" 压缩文件
Compared with commercial models such as Gemini and GPT-4O, our methods are comparable to and even superior to these commercial models in terms of character ID preservation and instruction following. We are more open-source than them, with lower costs, faster speed (it takes about 9 seconds to process one image), and powerful performance.
感谢: @river-zhang 及团队成员 浙江大学 & Harvard University
@article{zhang2025ICEdit,
title={In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer},
author={Zhang, Zechuan and Xie, Ji and Lu, Yu and Yang, Zongxin and Yang, Yi},
journal={arXiv},
year={2025},
url={https://arxiv.org/abs/2504.20690},
}
REDiDream Pro (FP8) 4/28/2025
Introduction to REDiDream Pro
HiDream-I1 是一个拥有170亿参数的开源图像生成基础模型,以秒级的速度实现业界领先的图像生成质量。REDiDream Pro是一个基于 HiDream-I1 full 版本开发的高效图像生成模型,通过额外训练和基于 DEV / FAST 版本的优化,显著提升了生成效率和稳定性,并在适当程度上解锁了NSFW能力。
HiDream-I1 is an open-source image generative foundation model with 17 billion parameters, achieving state-of-the-art image generation quality in seconds.
REDiDream Pro is an efficient image generation model developed based on the HiDream-I1 full version, optimized through the DEV / FAST version and additional training to significantly improve generation efficiency and stability, And to some extent unlocked NSFW generative ability.
Now we have GGUF quantization 现在我们终于有了GGUF量化:
https://huggingface.co/Sikaworld1990/Redidream/tree/main
Thx to Sikaworld1990
Thx to sikasolutionsworldwide709
Thx to City96 https://huggingface.co/city96
以下是其主要特性和功能的介绍:
主要特性 | Key Features
高效生成 | Efficient Generation
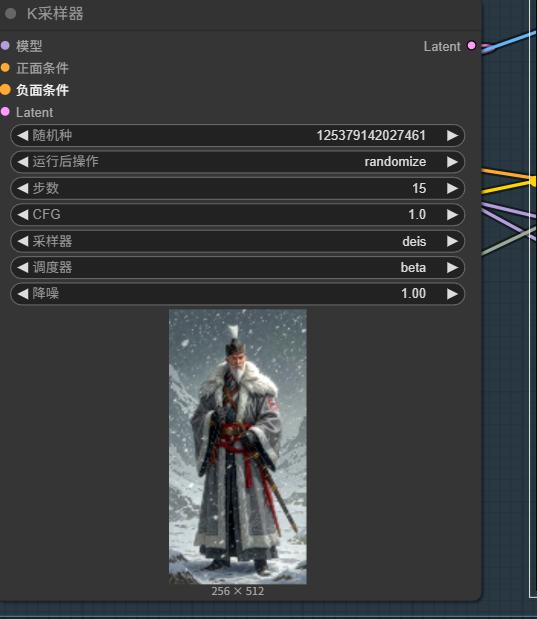
REDiDream Pro在 HiDream-I1 full 基础上优化,生成速度介于 dev 和 fast 版本之间,推荐推理步数为 15 步。
Optimized from HiDream-I1 full, with generation speed between dev and fast versions,
recommended inference steps: 15.
稳定性提升 | Enhanced Stability
通过 DEV FAST 版本优化,REDiDream 提供更稳定的图像生成性能。
Optimized via the DEV FAST version, REDiDream offers more stable image generation performance.
开源与灵活性 | Open Source and Flexibility
继承 HiDream-I1 的 MIT 许可证,不限制用户进一步修改和分发。
Inherits HiDream-I1’s MIT license, allowing users to freely modify and distribute without restrictions.
商业友好 | Commercial-Friendly
生成图像可自由用于个人项目、科学研究和商业应用,符合 HiDream-I1 的许可条款。
Generated images can be freely used for personal projects, scientific research, and commercial applications, compliant with HiDream-I1’s license terms.
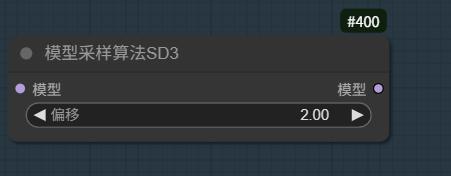
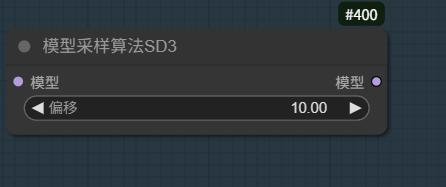
由于模型参数量巨大,并且匹配目前最全的4TE层进行文本编码,所以适当调整模型Shift偏移,可以获得更多的风格特征与NSFW解锁能力。
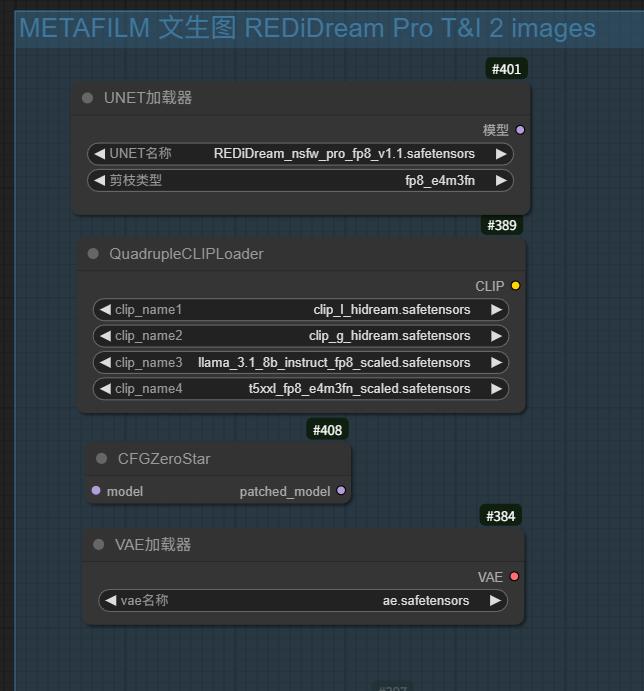
ComfyUI 支持 | ComfyUI Support
原生支持 | Native Support
REDiDream 提供对 ComfyUI 3.30 版本的原生支持,所有例图均通过此版本生成。
REDiDream provides native support for ComfyUI version 3.30, with all example images generated using this version.
训练环境 | Training Environment
REDiDream Pro 由 L40s 48G 硬件训练,并通过 ComfyUI 制作完成。
REDiDream Pro was trained on L40s 48G hardware and developed using ComfyUI.
性能需求 | Performance Requirements
硬件需求 | Hardware Requirements
REDiDream Pro 的性能需求与 HiDream-I1 dev 版本相当,适合高效推理。
REDiDream Pro’s performance requirements are comparable to HiDream-I1 dev, suitable for efficient inference.
生成速度 | Generation Speed
生成速度介于 HiDream-I1 dev 和 fast 版本之间,优化了效率与质量的平衡。
Generation speed falls between HiDream-I1 dev and fast versions, balancing efficiency and quality.
许可协议 | License Agreement
模型许可 | Model License
Transformer模型采用MIT许可证。变分自编码器(VAE)来自FLUX.1 [schnell],文本编码器来自google/t5-v1_1-xxl和meta-llama/Meta-Llama-3.1-8B-Instruct,需遵守各自的许可条款。
Transformer models are licensed under the MIT License. The VAE is from FLUX.1 [schnell], and text encoders are from google/t5-v1_1-xxl and meta-llama/Meta-Llama-3.1-8B-Instruct, subject to their respective license terms.
使用责任 | Usage Responsibility
用户拥有生成内容的所有权,但需遵守许可协议,不得生成非法、有害或针对弱势群体的内容。
Users own all generated content but must comply with the license agreement, avoiding illegal, harmful, or content targeting vulnerable groups.
REDiDream Pro | 继承许可证
继承 HiDream-I1 的 MIT 许可证,遵守各自的许可条款。
REDiDream inherits HiDream-I1’s MIT License.
致谢 | Acknowledgements
模型来源 | Weights Sources
HiDream-ai/HiDream-I1-Full · Hugging Face
Comfy-Org/HiDream-I1_ComfyUI · Hugging Face
GuangyuanSD/REDiDreamviaHiDreami1Uncensored · Hugging Face
组件来源 | Component Sources
变分自编码器来自FLUX.1 [schnell](Apache 2.0许可证),文本编码器来自google/t5-v1_1-xxl(Apache 2.0许可证)和meta-llama/Meta-Llama-3.1-8B-Instruct(Llama 3.1社区许可协议)。
The VAE is from FLUX.1 [schnell] (Apache 2.0 license), and text encoders are from google/t5-v1_1-xxl (Apache 2.0 license) and meta-llama/Meta-Llama-3.1-8B-Instruct (Llama 3.1 Community License Agreement).
REDiDream 命名来源:
After going through this journey, we Re-Did-(a)Dream
RED. UNO In-Context (FP8) 4/14/2025
REDAIGC FT Model used to match UNO In-Context Generation
(with improved quality compared to F.1 dev)
解决了FLUX FT底模无法适配UNO组件的问题,FP8权重(显存占用16GB),同时支持Diffusers以及ComfyUI
---
Diffusers 脚本:
https://github.com/bytedance/UNO
Dit-LoRA 权重:
bytedance-research/UNO · Hugging Face
ComfyUI-nodes 组件:
https://github.com/QijiTec/ComfyUI-RED-UNO
Diffusers-VAE版本:
https://huggingface.co/GuangyuanSD/16C_vae_Diffusers
---
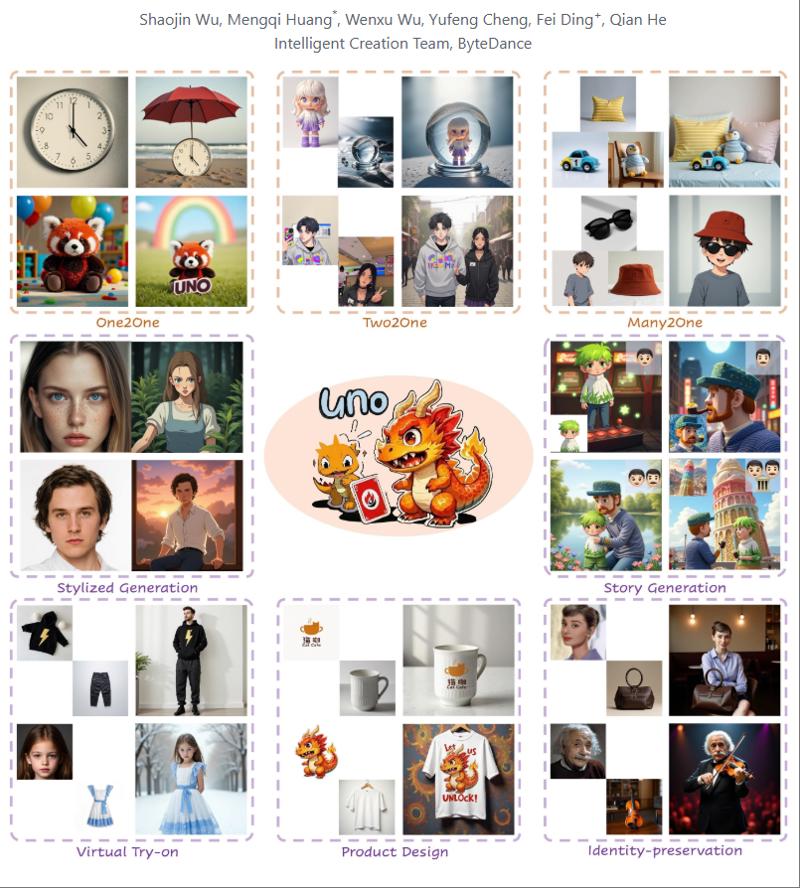
propose a highly-consistent data synthesis pipeline to tackle this challenge. This pipeline harnesses the intrinsic in-context generation capabilities of diffusion transformers and generates high-consistency multi-subject paired data. Additionally, we introduce UNO, which consists of progressive cross-modal alignment and universal rotary position embedding. It is a multi-image conditioned subject-to-image model iteratively trained from a text-to-image model. Extensive experiments show that our method can achieve high consistency while ensuring controllability in both single-subject and multi-subject driven generation.