tomoe/佐城トモエ/巴 (Blue Archive)




















詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
- Due to Civitai's TOS, some images cannot be uploaded. THE FULL PREVIEW IMAGES CAN BE FOUND ON HUGGINGFACE.
- For models version v1.5.1 or v2.0+, you can simply use them on webui like other LoRAs, they are trained on kohya script.
- For models version v1.5 or v1.4-, you have to use both 2 files to run it. see "How to use Pivotal Tuned models" in description for details.
- The pruned character tags are long hair, breasts, pink hair, halo, large breasts, braid, pink eyes, very long hair. You can add them into prompts when core features (e.g. hair color) of character is not so stable.
- Recommended weight of pt file is 0.7-1.1, weight of LoRA is 0.5-0.85.
- Images were generated using some fixed prompts and dataset-based clustered prompts. Random seeds were used, ruling out cherry-picking. What you see here is what you can get.
- No specialized training was done for outfits. You can check our provided preview post to get the prompts corresponding to the outfits.
- This model is trained with 82 images.
- Training configuration file is here.
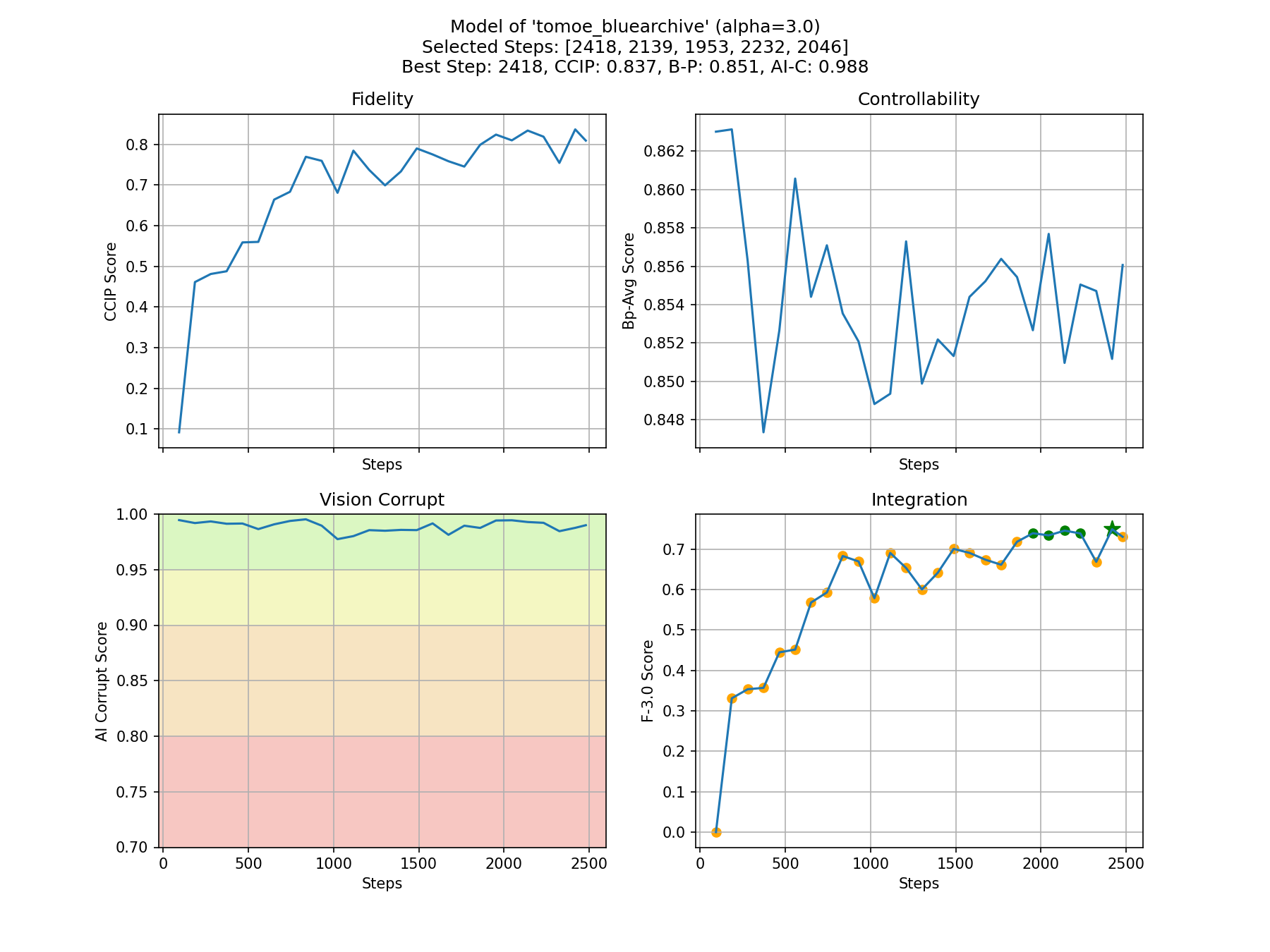
- The step we auto-selected is 2418 to balance the fidelity and controllability of the model. Here is the overview of all the steps. You can try the other recommended steps in huggingface repository - CyberHarem/tomoe_bluearchive.
How to Use This Model
This part is only for model version v1.5.1 or v2.0+.
You can simply use it like other LoRAs. We trained this model with kohya scripts.
他のLoRAと同様に簡単に使用できます。このモデルはkohyaスクリプトで訓練されました。
다른 LoRA처럼 간단히 사용할 수 있습니다. 우리는 이 모델을 kohya 스크립트로 훈련했습니다.
您可以像其他LoRAs一样简单地使用它。我们使用kohya脚本对该模型进行了训练。
(Translated with ChatGPT)
If you are looking for model waifus and or interested in our technology, you can enter our discord server.
How This Model Is Trained
- This model is trained with kohya-ss/sd-scripts, the images are generated with a1111's webui and API sdk.
- The auto-training framework is maintained by DeepGHS Team.
- Dataset used for training is the
stage3-p480-1200in CyberHarem/tomoe_bluearchive, which contains 82 images. - The step we auto-selected is 2418 to balance the fidelity and controllability of the model.
- Training configuration file is here.
For more training details and recommended steps, take a look at huggingface repository - CyberHarem/tomoe_bluearchive.
How to Use Pivotal Tuned Models
This part is only for model version v1.5 or v1.4-.
THIS MODEL HAS TWO FILES. YOU NEED TO USE THEM TOGETHER IF YOU ARE USING WEBUI v1.6 OR LOWER VERSION!!!.
In this case, you need to download both tomoe_bluearchive.pt and tomoe_bluearchive.safetensors,
then put tomoe_bluearchive.pt to the embeddings folder, and use tomoe_bluearchive.safetensors as LoRA at the same time.
If you are using webui v1.7+, just use the safetensors file like the common LoRAs.
This is because the embedding-bundled LoRA/Lycoris model are now officially supported by a1111's webui,
see here for more details.
このモデルには2つのファイルがあります。WebUI v1.6 以下のバージョンを使用している場合は、これらを一緒に使用する必要があります!!!
この場合、tomoe_bluearchive.pt と tomoe_bluearchive.safetensors の両方をダウンロードする必要があり、
その後、tomoe_bluearchive.pt を embeddings フォルダに入れ、同時に tomoe_bluearchive.safetensors をLoRAとして使用します。
webui v1.7+を使用している場合、一般的なLoRAsのようにsafetensorsファイルを使用してください。
これは、埋め込みバンドルされたLoRA/Lycorisモデルが現在、a1111のwebuiに公式にサポートされているためです。
詳細についてはこちらをご覧ください。
此模型包含两个文件。如果您使用的是 WebUI v1.6 或更低版本,您需要同时使用这两个文件!
在这种情况下,您需要下载 tomoe_bluearchive.pt 和 tomoe_bluearchive.safetensors 两个文件,
然后将 tomoe_bluearchive.pt 放入 embeddings 文件夹中,并同时使用 tomoe_bluearchive.safetensors 作为 LoRA。
如果您正在使用 webui v1.7 或更高版本,只需像常规 LoRAs 一样使用 safetensors 文件。
这是因为嵌入式 LoRA/Lycoris 模型现在已经得到 a1111's webui 的官方支持,
更多详情请参见这里。
(Translated with ChatGPT)
The trigger word is tomoe_bluearchive, and the pruned tags are long_hair, breasts, pink_hair, halo, large_breasts, braid, pink_eyes, very_long_hair.
When some features (e.g. hair color) are not so stable at some times,
you can add these them into your prompt.
Why Some Preview Images Not Look Like Her
All the prompt texts used on the preview images (which can be viewed by clicking on the images) are automatically generated using clustering algorithms based on feature information extracted from the training dataset. The seed used during image generation is also randomly generated, and the images have not undergone any selection or modification. As a result, there is a possibility of the mentioned issues occurring.
In practice, based on our internal testing, most models that experience such issues perform better in actual usage than what is seen in the preview images. The only thing you may need to do is adjusting the tags you are using.
I Felt This Model May Be Overfitting or Underfitting, What Shall I Do
The step you see here is auto-selected. We also recommend other good steps for you to try. Click here to select your favourite step.
Our model has been published on huggingface repository - CyberHarem/tomoe_bluearchive, where models of all the steps are saved. Also, we published the training dataset on huggingface dataset - CyberHarem/tomoe_bluearchive, which may be helpful to you.
Why Not Just Using The Better-Selected Images
Our model's entire process, from data crawling, training, to generating preview images and publishing, is 100% automated without any human intervention. It's an interesting experiment conducted by our team, and for this purpose, we have developed a complete set of software infrastructure, including data filtering, automatic training, and automated publishing. Therefore, if possible, we would appreciate more feedback or suggestions as they are highly valuable to us.
Why Can't the Desired Character Outfits Be Accurately Generated
Our current training data is sourced from various image websites, and for a fully automated pipeline, it's challenging to accurately predict which official images a character possesses. Consequently, outfit generation relies on clustering based on labels from the training dataset in an attempt to achieve the best possible recreation. We will continue to address this issue and attempt optimization, but it remains a challenge that cannot be completely resolved. The accuracy of outfit recreation is also unlikely to match the level achieved by manually trained models.
In fact, this model's greatest strengths lie in recreating the inherent characteristics of the characters themselves and its relatively strong generalization capabilities, owing to its larger dataset. As such, this model is well-suited for tasks such as changing outfits, posing characters, and, of course, generating NSFW images of characters!😉".
For the following groups, it is not recommended to use this model and we express regret:
- Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
- Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
- Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
- Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
- Individuals who finds the generated image content offensive to their values.