SDXL - Lenticular Effect ( Kinda )

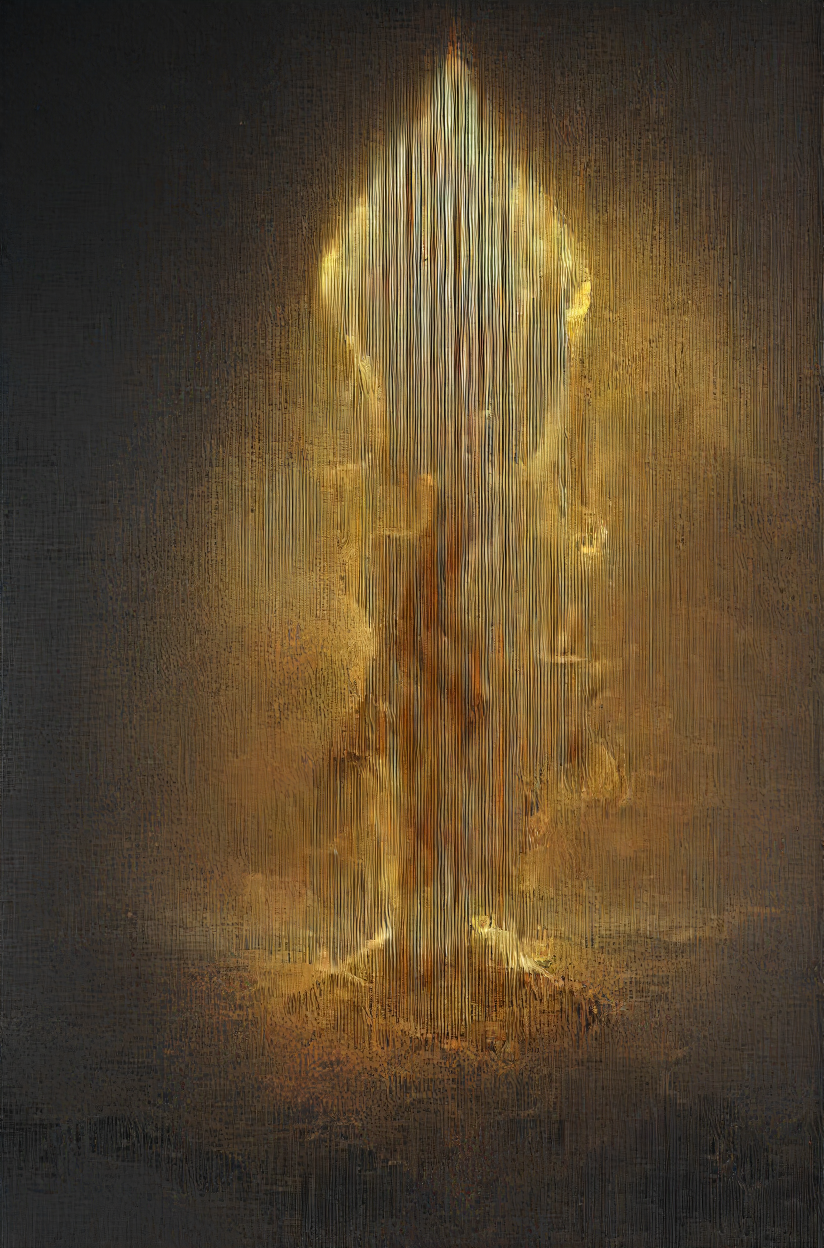

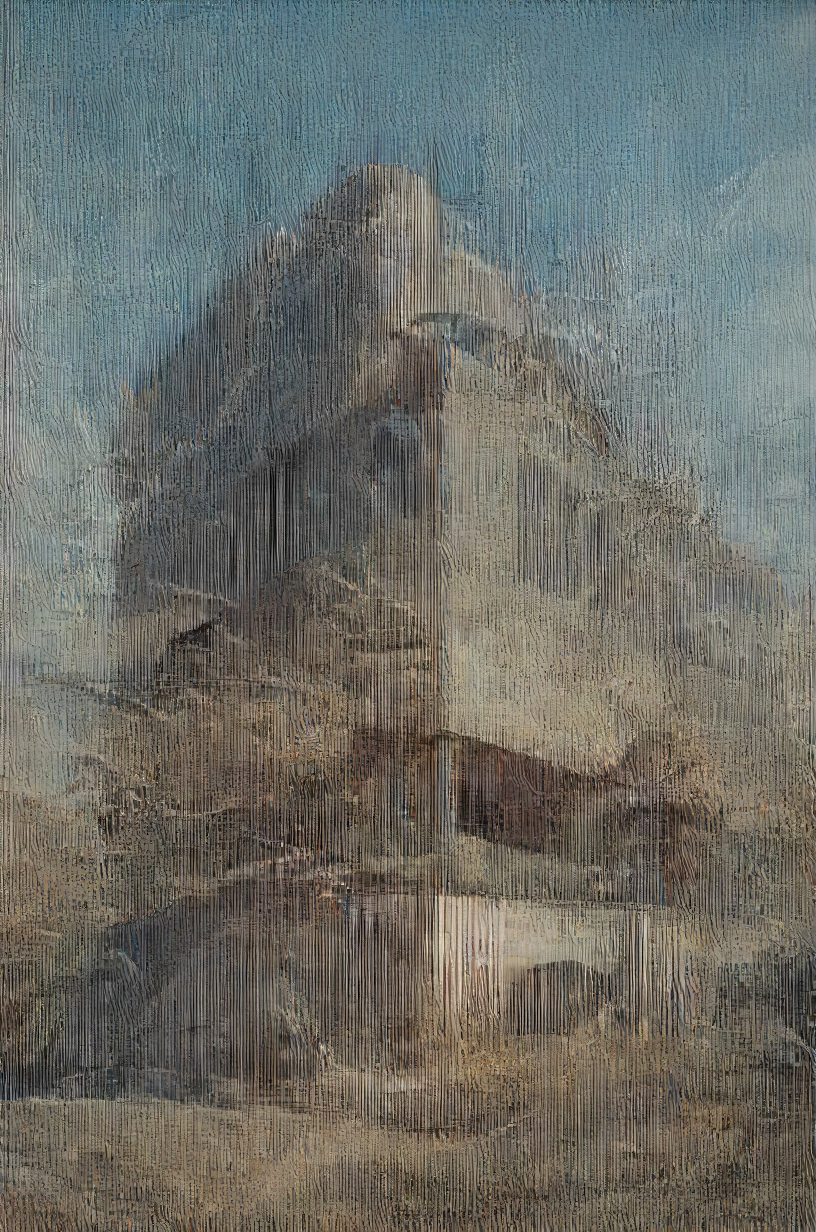



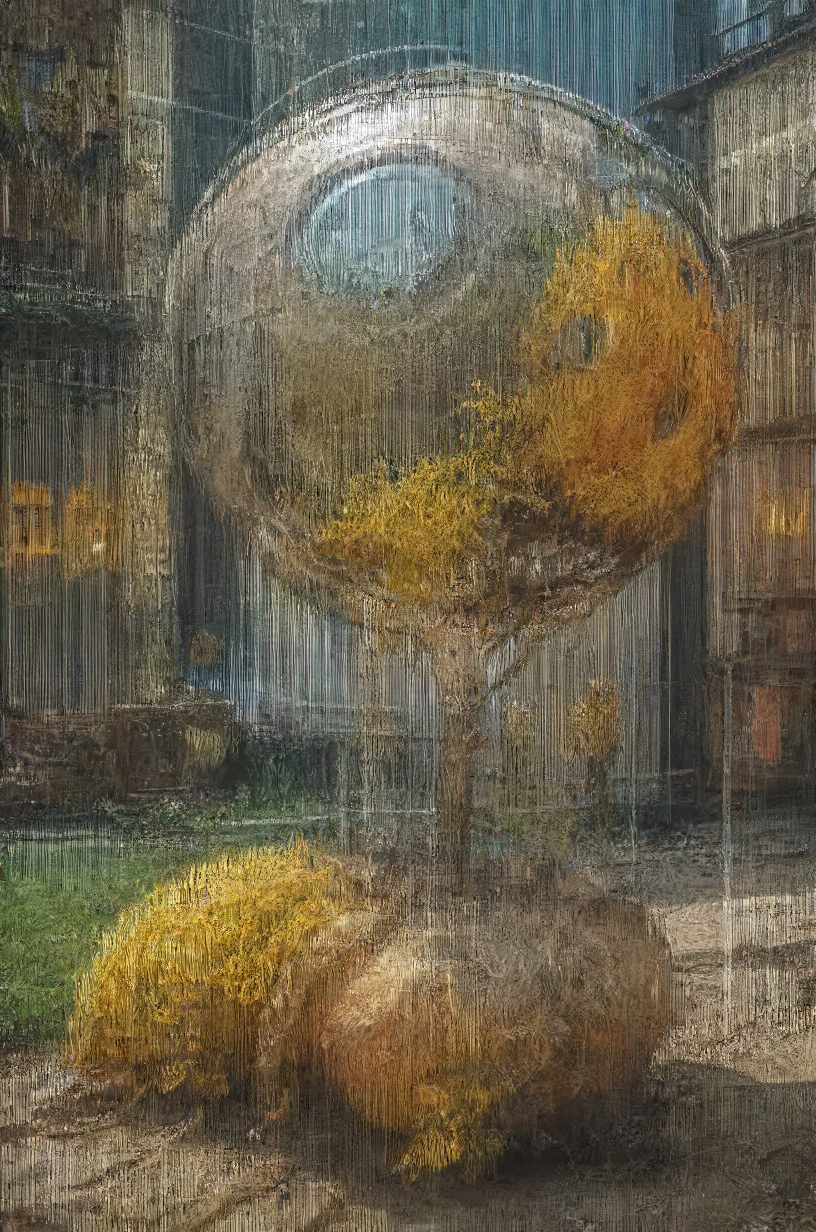





详情
下载文件 (1)
模型描述
V1.0
Lenticular effect ( not the real deal, just based on the idea )
It's basically just 2 or more pictures layered on top of each other, mostly with different contented, that change depending on the viewing angle. Tilt all the way to one side gives you one picture 1 , other side picture 2. Guess Google can explain it a bit better and more in depth if interested. Didn't even know there is a particular name for it, was always a hologram for me.
This is pretty much what happens if you get a trip of nostalgia or remember something and try to make a LoRA out of it just to see what it will do, knowing it can't work because several factors aren't right or missing... in this case mainly preparing in a dataset in Photoshop that is at least consistent in the way it's done and the lack of motion.
Wasn't really going to release it, just fooling around here and there because it has just a use for me, kinda, especially for testing purposes.
I was aiming for the middle part, where both pictures blend into each other, along with being laminated on plastic or whatever. Of course, without motion there is no point to go for the actual effect and there are other ways to do that more easily. It's just blending from one picture to another. But, there is always something that catches my attention. With every image i've posted so far on Civit, i could probably explain why i chose it. For the most part, i don't care for quality, how trendy or fancy something is. Strange positions or expression, mood, atmosphere, lighting, unexpected, composition, stupid looking things or sometimes just getting caught on a theme to see where it's going are pretty much my main focus i would say. Spend enough time studying art, anatomy, shapes, gestures and all the boring stuff that goes along with it to know if something doesn't look right or is off and oh boy, much wrong with a lot my pictures... AI has to fk shit up to get me interested. Doesn't mean i don't enjoy a good looking image, especially if someone else did it, but art in any shape or form is the most subjective thing anyway, which adds diversity by itself.
Well...
I liked the effect ( depth, kinda detailed, unfinished, sketchy, painterly streaks )
It produces chaos and randomness at a higher strength that is hard to predict sometimes ( unless the prompt overpowers it ), which is a big + in my book, but need to add more pictures. Unfortunately it takes quite some time to chose and prepare the dataset, because even chaotic images that aren't tagged will be picked up by the training and there is a bias i wanna avoid/get rid off. Quality and diversity should be given a thought too imho, even if hard to tell after Photoshop magic. There is clearly a bias towards certain images even though i avoided adding to much stuff that i tend to prompt for. Most pictures are of humans in artistic positions or landscapes, some creatures and animals etc. Always tried to combine 2 images that have a different theme and art style, but some where clearly more distinguishable/visible then others, so it tends to go for those images.
Base SDXL hates that thing with a passion at higher strength. A good trained or merged model is probably better if you wanna create something that is more let's say "easy on the eyes". Some models pretty much negate the effect a lot and if you want it back, adding lentclr_effect at the front of the prompt should help.
Testing and going trough models sporadically to see what happens. For showcase reason i only used Base XL ( sometimes in combo with my embedding, to get rid of to much clutter ). Was also a bit lazy and reused a few older prompts, mainly to see what happens and so other people know what is going on. While training i saw that the versions with a lower step count ( from 500 - 1000 ) where actually closer to the effect where 2 images blend together, but it only had an impact on models that are more like Base XL and all other models that are merged or trained ignore the LoRA pretty much at a low step count, so 3000 steps it is. Already posted other images a while back in my gallery that are made with an older version and different models.
As always, mixy mixy LoRA/Model mix till i or someone else finds the holy grail, that is somewhere... buried... very deep... on mars... under a mountain.
End of long-winded explanation that doesn't help at all.