Geeky Ghost AI Voice Assistant Workflow

详情
下载文件 (1)
模型描述
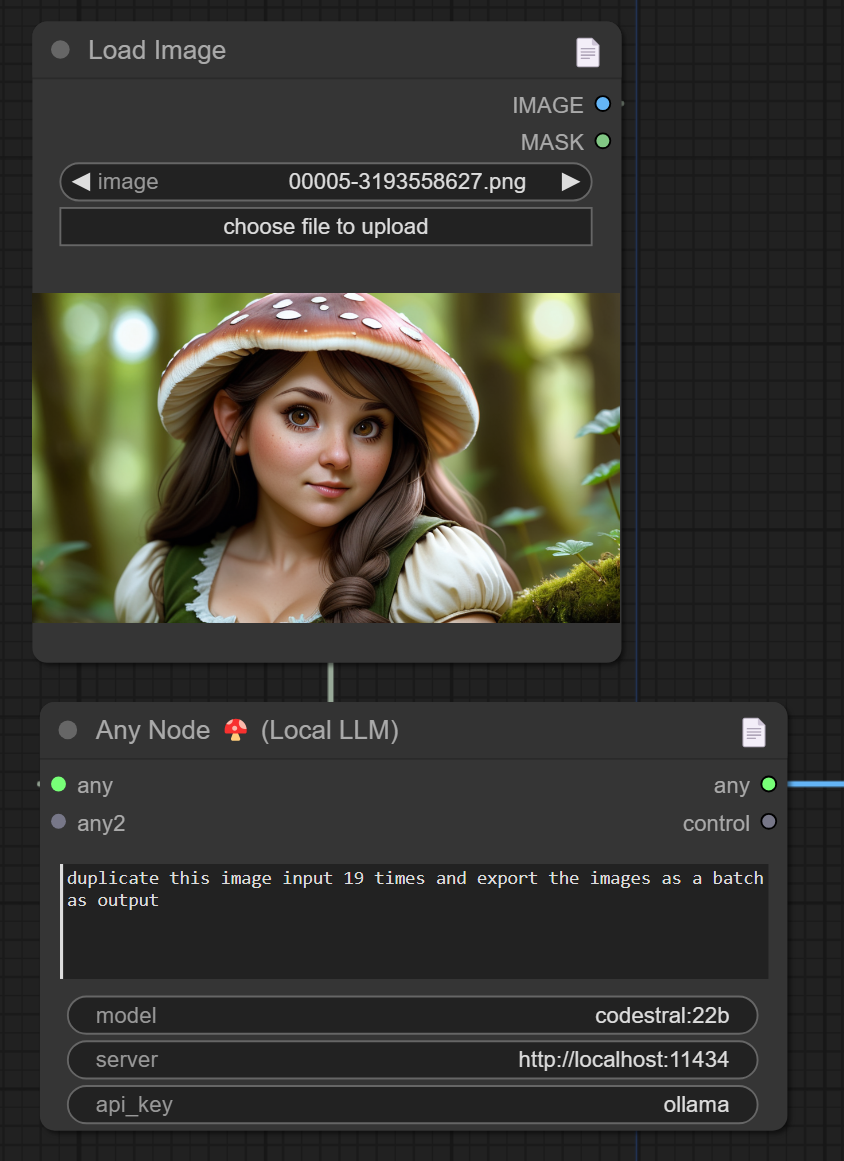
Latest: v4.20 not to be confused with 4.2 (I just don't want to go past 4.2 sorry lol) Added Any Node to duplicate int image, not much of a change, but it's a single image version of wav2lip now. So 1 image is all you need for the wav2lip video thanks to any node. Other ways to do it, but this was a test and it worked so why not. Single Image Version.
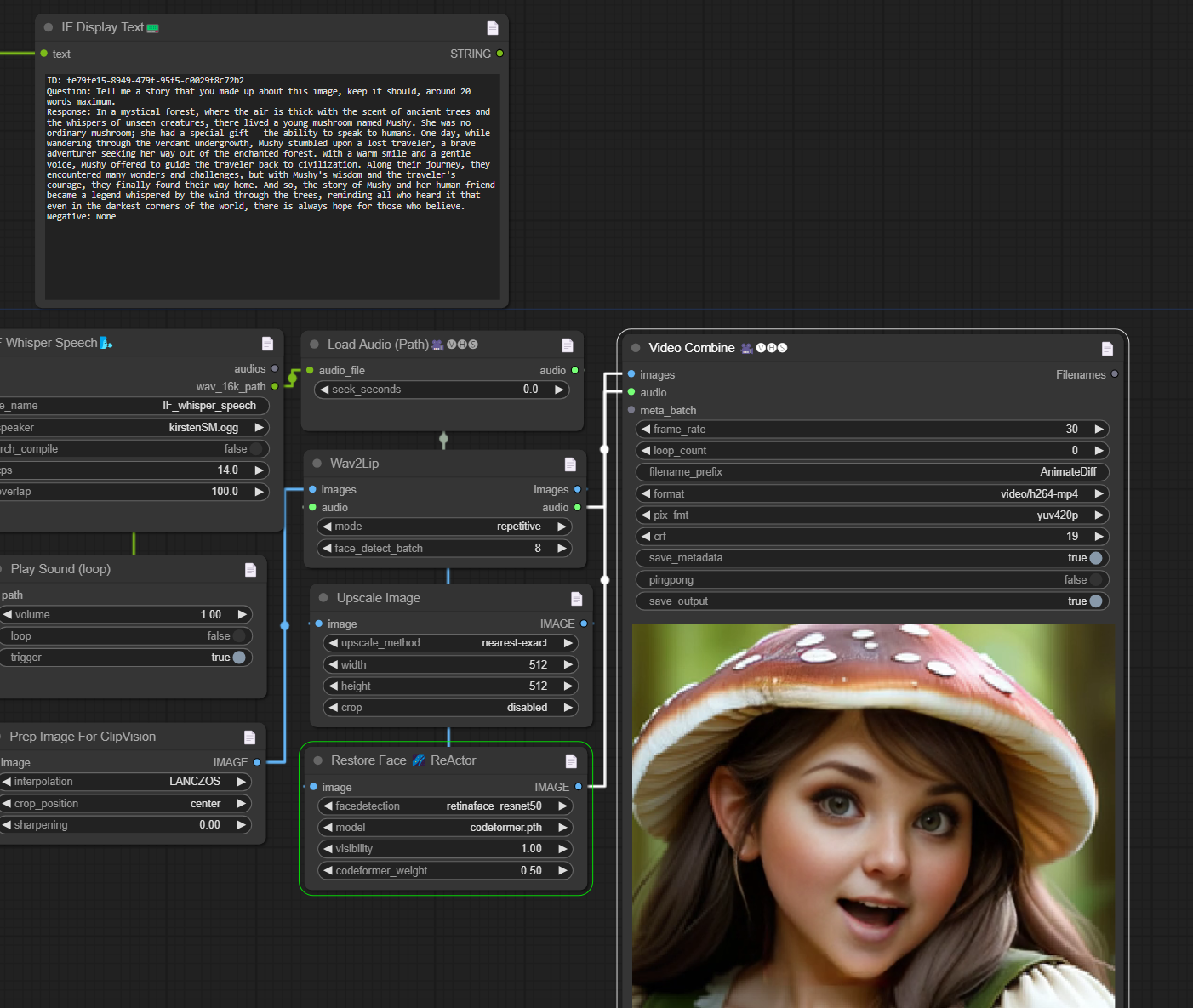
Best Version - v4.2 - So, added wav2lip to the workflow, someone had a working node going, now you can load a video, and have whisper create the voice for your assistant and now, you have a voiced animated avatar. Fun workflow, piecing it together was awesome lol. Crafting LLM profiles, plugging different connectors to places they didn't belong. Play sound (loop) is the only node I can get good audio for this inside the workflow. You have to convert the path to an input, then use the wav output from whisper as an input for play sound. this makes the voice play so you can hear it.
It then sends it with the video you uploaded to wav2lip to create the video. Node works, but it's not as good as forge and auto yet. Creator of the node did an awesome job non the less. Can only go up from here and here's not bad lol.
older-------------
Ran voice through wav2lip and sadtalker for some fun and pulled an old character I made to be the face of Darwin lol.
Added more groups, notes explaining things a bit.
AI Assistant through text or voice.
Inpainting and outpainting
SVD, Cascade, AnimateDiff
Spritesheet maker
Text to voice generation using .ogg audio files as training IF Whisper to Speech (Audio with vocals only, 3 minutes seems to be fine, but 10 as in their example seems to be better)
Added my layering group node setup
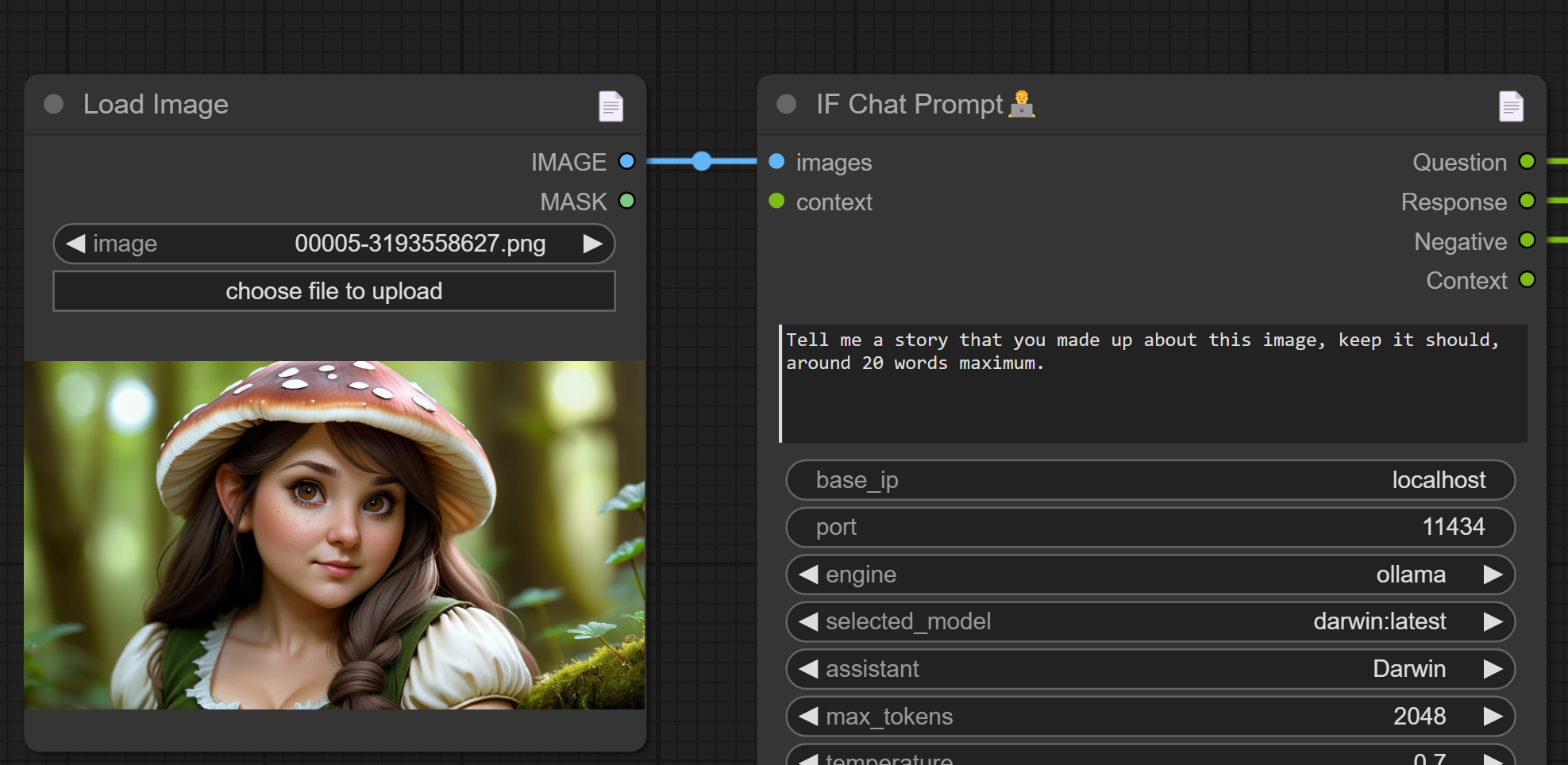
Voice assistant test workflow. Trying out some nodes for my Rosebud AI workflow. Darwin is a custom personality, so not included.
Needs Ollama installed and running
Impact Frames or IF nodes make this possible
WIP