Old Consistency V32 Lora [FLUX1.D/PDXL]





















세부 정보
파일 다운로드 (1)
모델 설명

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious is not a PDXL offshoot, it's different and very good. Play with it if you get a chance.
I trained a version of Simulacrum specifically for it.
V3-2 Instead of V3.22:
The goal of v3.22 ended up shifting and I got lost in the rabbit hole of flux testing and figuring out new mechanisms. After I learned enough and determined I know enough about how to subject fixate, how to tag, and how flux itself understands tagging; I can actually build a proper version 3.
Thank you everyone who put up with my learning and experimental cycle. It's been a legitimate rollercoaster of tests, failures, and some true successes. I know what can be done, how to do it, and I have a methodology to approach and iterate upon what I've learned to create what I want to create. The process isn't perfect and will be refined as I progress, so it'll be a matter of understanding and iterative development no matter what I build. I'm confident enough, that I have found and crossed the first big Dunning Kruger cliff and that I can start actually learning and teaching useful information after the experiments, while hopefully doing my best to process and understand the information in useful ways for the basic and advanced user alike.
I've determined, that my original approach heading to V4 is viable, but the process I was using isn't valid like I thought originally when I was iteratively learning the systems. More learned aspects and more failures to learn from, to develop the tilled land for the successes to come.
Directives based versioning.
I plan to introduce THREE core directive trainings per version and a singular vanilla nd version.
I'll be using highly general directives based training for not only the core system and for specific core themed images themselves to bleed all of the intended themed aspects throughout the system.
The technical portion of the tagging process is going to be unique and difficult to understand if you aren't familiar with the reasoning behind why I'm doing certain things to the system, so the images and tagging will likely be highly confusing if you want detailed specifics.
The simplistic tagging system will remain in it's own right, and still be fully capable of producing the necessary outcomes when needed.
The "nd" or a "no directive" version for every release will ensure the testing differences and the outcomes are similar, like the bird in the mine; it's time to go when the bird stops tweeting. Likely these sister models will be capable merge and normalization for reuse and bleeding concepts together that may or may not have worked due to the used directive.
Fixation on INDIVIDUAL characters is now the utmost paramount goal for this model. There will only be one fixated character and the resolution for that character will be scaled to a downward and upward ratio matching the correct FLUX training formatting parameters.
V3.2 Problems Were Less Pronounced Than I thought:
The majority of the outcome of concern was based on missing information that I plan to shore up over time. Just a matter of iterative development.
That being said, the trained version of 3.21 is currently in testing and will be released soon. It has improved capability with pose control and a shifted focus on the model using a fairly long camera based directive.
The outcome has shown good compatibility with the majority of loras I've tested and even works with some very stiff loras that can't seem to be prodded or rotated with the current v32.
It has shown good compatibility with Flux Unchained, a multitude of character models, face based models, human models, and so on. The majority of the system doesn't overlap or break other systems so far, so that's good.
V3.2 Problems To Address:
There is some consistency issues with some of the poses and angles. There's also some cross contamination with various other loras when they use the from side, from behind, from above, and from below tags. I'll be using new tags as a kind of verification unit and training an entirely separate LORA to ensure camera control fidelity in the future.
Seems to work fine mostly for anime, but when loras get involved there's problems.
Combination tags for version 3.21;
There's a few baseline tests I need to run to ensure the camera works properly based on placement, so I'll be testing tags like:
a subject from front view above angle
a subject from front view side angle while above
a subject from rear view above angle while in front
a subject from side view above angle while in rear
and more similar tags in the base flux_dev, that way I can ensure what I built will correctly position the camera where it belongs, and the fidelity of the image isn't lost in the process.
From what I gather, the system trains huge depths if you use generic options like this. Some more testing is needed to be sure.
Tags like grabbing from behind, sex from behind, etc will likely not cooperate with behind tags, so I'll be using rear tags.
"from side", "from behind", "straight-on", "facing the viewer", and anything that is directly associated with any character specific safebooru, danbooru, gelbooru, placement rotations won't be trained in. It'll be entirely based on VIEWING a character, rather than INTERACTING with a character.
We also don't want POV arms to be present most of the time, so there has to be a lot of testing to ensure the tagging doesn't accidentally spawn arms, legs, torsos, and fixate on the individual subject in question.
Some of the poses quite frankly didn't work:
There's a combination tag system at play here that simply didn't do it's job, so there will need to be a new set of tag combinations to run character control correctly.
Legs are deformed or don't exist.
Arms can be deformed or badly placed.
Feet are missing.
Upper torso too pronounced too often. <<< overfitted
Lower torso not showing clothing correctly.
Neck not displaying correct attires with scarves, towels, chokers, collars, and more.
Nipples and genitals are an absolute mess. There needs to be a proper folder of their variations for a proper NSFW controller in this case.
NAI should be style specifically and finetuned as style.
Clothing options spawn body types more often than they should.
explicit rating is neigh impossible to access at times, other times it's punching through like a freight train.
There isn't enough questionable images to weight, and the explicit tagged system should also be tagged with questionable to ensure that the questionable information is also accessed.
Some anime characters spawn with bad perspective, which is a bad thing considering the goal is proper associative perspective.
All fours is pretty solid, but it definitely has some perspective problems. It doesn't seem to treat anime characters as 3d often enough, so the environments around the images need a bit more fidelity.
All fours does not work in a lineup without a lot of tweaking.
Kneeling does not work in a lineup without a lot of tweaking.
Lineups and groups specifically seem to be formatted in a unique way for flux and this merits further investigation. Almost like enabling an internal for each loop of some sort.
There were some successes:
Baseline fidelity didn't suffer for the majority of images.
Many new poses DO WORK, if not jank at times.
Anime style has been changed in it's own unique NAI way with an added bit of realism.
Multiple characters can be posed, albeit in a very strange fashion at times.
Standing at any angle has some absolutely fantastic fidelity and image quality with the style of NAI.
V3.3 will have to wait.
V3.3 Roadmap:
I updated the resources at the bottom of this document and branched the older documentation to it's own article for archiving purposes.
With the outcome now reflecting my vision a bit better, I can shift my focus to the next step on the goal list; Overlays.
V3.3 will introduce what I call high alpha burned offset tags, which will streamline things like making comics, game UIs, overlays, health bars, displays, etc.
Theoretically you can make your own fake games in consistency if I make a correct overlay with the correct burns.
This will lay the groundwork for imposing characters in any position from any depth of a scene, but that comes later.
It can ALREADY make sprite sheets in a fair fashion, so I'll be exploring the built in tag system in the coming days to test all of these various subsystems using a bit of prompting elbow grease and a bit of computational power. There's a high probability that this exists already and it simply needs to be figured out.
V4 Goals:
If all of these go well, the entire system should be ready for full production capability that includes image modification, video editing, 3d editing, and a great deal more that I simply can't comprehend yet.
v33 overlays
This is a bit of a misnomer, as it's more of a scene definition framework for the next structure
This one will take both the least and most amount of time and I have a few experiments I need to run with alpha to make it work, but I'm pretty sure overlaying is going to be a choice option not only for displaying messages, but also for scene control due to the way depth works.
v34 character imposing, rotation value planning, and careful viewpoint offsets:
Ensuring that certain characters do exist and are following directives is a primary goal, as sometimes they simply do not.
A full number based rotation valuation using pitch/yaw/roll in a degree based fashion is going to be implemented. It's not going to be perfect as I don't have the math skills nor the image sets nor the 3d software skills to pull this off, but it'll be a good start and hopefully latch onto whatever FLUX has already.
v35 scene controllers
Complex interaction points in scenes, camera control, focus, depth, and more that allow for full scene building along with the characters you place in them.
Think of this like a 3d version of the overlay controller, but on steroids if you want it to be.
v36 lighting controllers
Segmented and scene controlled lighting changes that affect all characters, objects, and creations contained within.
Each light will be placed and generated based on specific rules defined in unreal using a multitude of lighting types, sources, colors, and so on.
Theoretically FLUX should fill in the gaps.
v37 body types and body customization
With the introduction of the basic body types, I want to introduce a more complex body type creation that includes but is not limited to things like:
fixing the poses that don't work correctly
adding a multitude of additional poses
more complex hair:
hair interaction with objects, cut hair, damaged hair, discolored hair, multicolored hair, tied hair, wigs, etc
more complex eyes:
eyes of various types, open, closed, squinting, etc
facial expressions of many types:
happy, sad, :o, no eyes, simple face, faceless, etc
ear types:
pointed, rounded, no ears, etc
skin colors of many types:
light, red, blue, green, white, grey, silver, black, jet black, light brown, brown, dark brown, and more.
I'll try to avoid sensitive topics here as people seem to care about skin color a whole lot overall, but I really just want a bunch of colors like the clothes.
arm, leg, upper torso, waist, hips, neck, and head size controllers:
bicep, shoulder, elbow, wrist, hands, fingers, etc with sizers for length, width, and girth.
collarbone, and whatever torso tags there are
waist and whatever waist tags there are
body size generalizations specifics based on a gradient of 1 to 10 rather than some sort of pre-defined system that something any of the boorus used
v38 outfits and outfit customization
Nearly 200 outfits give or take, each with their own custom parameters.
v39 500 choice video game, anime, and manga characters sampled from high fidelity data
five hundred cigaret- err... I mean... Lots of characters. Yes. Definitely not an absolutely large amount of meme based characters that have no rational linkage to character design or archetype.
After that you can build anything or train any character.
massive fidelity and quality boost:
including 10s of thousands of images from various sources of high and top quality anime, 3d models, and photographic semirealism to superimpose and train this particularly finetuned version of flux into a stylistic submission that fits within the parameters.
each image will be fidelity scored and tagged within a ratio of score_1 to score_10 in a similar fashion to pony, but I'll have my own unique spin on the system depending how well or badly it goes.
V3.2 Release - 4k steps:
This one isn't for the kids, most definitely. This is a SFW/QUESTIONABLE/NSFW base model that can be trained into anything.
It's also NOT built to be a smut maker, it just can if prompted. It's part of the package deal when you enable behaviors of certain things by teaching AI certain things, you get baggage. The images are roughly 33% 33% 33% currently, give or take a handful. It's weighted TOWARDS safe similar to how NAI works.
I'm from a firm standpoint of enabling and teaching information so the individual can decide what to do with it. Teaching an uncensored AI a bunch of uncensored things using a fairly controlled and careful degree, I believe is healthy for the AI's progression and growth into full fidelity understanding, as well as healthy for those who are generating images FROM the AI not having to see nightmare fuel 24/7.
This thing shows some promise beyond anything I've seen by a large margin.
Use my ComfyUI workload. It's attached to all the images below.
Safe enabled by default:
questionable < unlocks more questionable random traits
explicit < unlocks the fun stuff to randomly show up
Perspective Activation tags: try mixing; from front, side view, etc
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
Primary added and enhanced poses:
all fours
kneeling
squatting
standing
bent over
leaning
lying
upside-down
on stomach
on back
arm placements
leg placements
head tilts
head directions
eye directions
eye placement
eye color solidity
hair color solidity
breast size
ass size
waist size
a multitude of clothing options
a multitude of character options
a multitude of face expressions
sex poses very much a WIP and I seriously would avoid trying them until they are properly refined. They are FAR beyond my scope and I really don't have the brainpower right this minute to determine the route to take.
The pose maker, angle maker, situation setup, concept imposer, and interpolation structure is in place and I'll train more versions.
Enjoy.
V3.2 Roadmap:
8/25/2024 5:16 - I've identified that the process has worked, and the system is functional to a high degree beyond expectations. The AI has developed emergent behaviors that have posed the characters in exponentially more powerful ways than anticipated. Testing is commencing and the outcome looks absolutely fantastic.
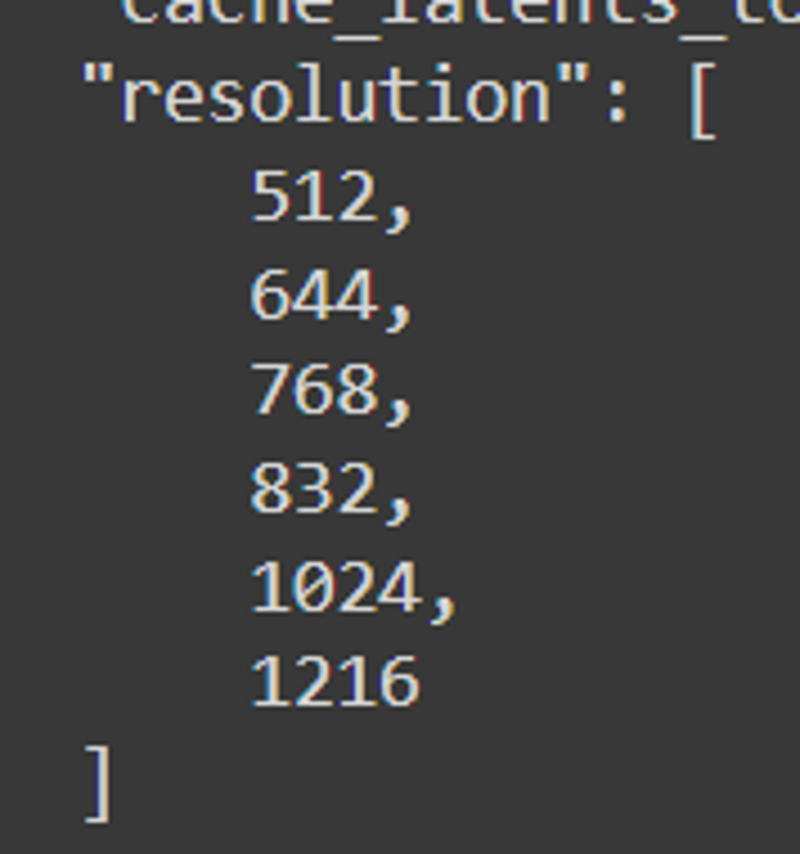
Final resolutions were: 512, 640, 768, 832, 1024, 1216
8/25/2024 3 pm - Everything is properly tagged and the poses are prepared. The real training begins now, and the process is going to involve multiple dimension tests, lr count tests, step checks, and considerably more to assess the correct candidate for v32 release.
8/25/2024 4 am- First version of v32 showed minimal deformity around step 1400 and then high grade deformity around step 2200, which means the lazy WD14 tagging didn't work. Manual tagging incoming. It's going to be a fun morning.
8/24/2024 evening - It's cooking now.
 I suspect this one won't work. I've autotagged everything and clipped out the pose angles for now. I'm going to see what wd14 can do on it's own. After the either successful or unsuccessful training goes, I'll restore the original pose angles and established tag order. Lets see how it works now that all of the intentional data is clumped together and the use cases are dense.
I suspect this one won't work. I've autotagged everything and clipped out the pose angles for now. I'm going to see what wd14 can do on it's own. After the either successful or unsuccessful training goes, I'll restore the original pose angles and established tag order. Lets see how it works now that all of the intentional data is clumped together and the use cases are dense.With 4000 images I suspect it'll take a while to cache the latents, but with the attention spent on the specific "use case" dolls and bodies, it should turn out okay at least.
8/24/2024 noon -
 We grinding.
We grinding. Everything is formatted in such a way that it'll have shadow implication backgrounds, which will assist with flux generating images based on surfaces and locations. Everything is built to pose based on the missing poses that flux can't handle. Everything is built to fixate on subjects that can be multiplicatively superimposed in a multitude of locations.
Everything is formatted in such a way that it'll have shadow implication backgrounds, which will assist with flux generating images based on surfaces and locations. Everything is built to pose based on the missing poses that flux can't handle. Everything is built to fixate on subjects that can be multiplicatively superimposed in a multitude of locations.I've been focusing on proper arm placement and ensuring tagged arms that overlap will build arms from point A to B.
8/24/2024 morning - So there's apparently some arm problems too, but it's okay I'll get it worked into the list. Thanks for pointing this one out, there's definitely some cross-contamination here that needs to be addressed. I use a specific comfyui loopback system that isn't present in the website's system, so I might need to disable on-site generation for this version.
 8/23/2024 - I'm up to about 340 new high detail anime images with near-uniform pose, pitch/yaw/roll identifiers to ensure the solidity, colorations shifts, size differentiation with breasts, hair, and butt. There's 554 more to go. V3.2 will be heavily dedicated to anime, afterwords I plan to source from pony to produce enough synthetic realism to create the necessary realism elements as well. Unless flux allows it after training, in which case I'll just use flux.
8/23/2024 - I'm up to about 340 new high detail anime images with near-uniform pose, pitch/yaw/roll identifiers to ensure the solidity, colorations shifts, size differentiation with breasts, hair, and butt. There's 554 more to go. V3.2 will be heavily dedicated to anime, afterwords I plan to source from pony to produce enough synthetic realism to create the necessary realism elements as well. Unless flux allows it after training, in which case I'll just use flux. These SHOULD ensure fidelity and rating separation on a pose-by-pose basis, especially since I have a new methodology of using from and view keywords. Theoretically it should function nearly identically to NovelAI's pose control when I'm done, which is basically my goal. The characters and differentiation of characters is an entirely different story of course.
These SHOULD ensure fidelity and rating separation on a pose-by-pose basis, especially since I have a new methodology of using from and view keywords. Theoretically it should function nearly identically to NovelAI's pose control when I'm done, which is basically my goal. The characters and differentiation of characters is an entirely different story of course.Everything must be perfectly orderly and lined up, or else it just simply won't add the necessary context at the necessary rates to affect the baseline model enough to actually be useful.
By design SAFE will be the default, so the entire system is going to be built weighted towards safe, with the ability to enable NSFW.
I'll train multiple iterations of this particular LORA to ensure the differentiation between the two can remain strict, while still allowing for the more NSFW crowd to be entertained with the more NSFW version.
My hope here is, when this is trained; I can dump a choice picked dataset of 50,000 images into the system and it'll simply create something magical. Something potentially along the same power grade as pony for anything that the heart desires. Then I can rest knowing the universe is grateful. After that you guys can probably dump whatever you want into it and it'll just make it into whatever you want due to the innate power of flux with the spine of consistency.
I plan to release the training data for the full consistency initial v3.2 image set when it's organized, trained, tested, and ready. I'll release the v3 data this weekend when I have time.
I've identified a series of pose inconsistencies, mostly with the lying keyword coupled with the angle keywords. I'll be testing each combination and shoring up their bottom line consistency before moving onto the next phase; the base outfit choices, outfit changes, and derivatives based on the poses that do and don't work. Not to mention I need to include more detailed information for the the questionable and NSFW elements later on as well. You can take a guess as to what those are after the next version.
Until then, I need to make sure the poses actually work as directed so I'll be creating new intentional combination keywords, shoring up the full pose counts to more images per pose, more images per angles, and more angles per situation. I'll also be creating a series of datas that function like placeholders for creating more complex situations and images, but flux doesn't really need many so I'll have to be doing that as I go. I'll also be including a series of "base" tags that will default certain things when hitting fail points to other things. That should help with the consistency a bit.
V3 Documentation:
Tested primarily on the FLUX.1 Dev e4m3fn at fp8, so the prepared checkpoint merge will reflect this value when it's upload is complete. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
This runs on the base FLUX.1 Dev model, but it will work on other models, merges, and with other loras. The results will be mixed. Experiment with load order, as the model values shift in sequence in varying degrees.
This is nothing short of a spine to FLUX. It empowers useful tags very similar to danbooru, to establish camera control and assistance that makes it much easier to make very customizable characters in situations that FLUX likely CAN DO, but it requires a great deal more effort to do most of these situations by default.
I HIGHLY advise running a multiple loopback system to ensure image fidelity. Consistency improves quality and fidelity over multiple iterations.
This is HEAVILY individual oriented. However, due to the way I structured the resolutions, it can handle MANY people in similar situations. The loras that cause immediate change on the screen without context will often be completely useless, as they generally do nothing to contribute to the context. The loras more specific to adding TRAITS to people or creating contextual interactions between people seem to work just fine. Clothing works, hair types work, gender control works. Most of the loras I tested work, but there are some that do nothing.
This is not a merge. This is not a combination of loras. This lora was created using synthetic data generated from NAI and AutismPDXL over a period of a year. The image set is quite complex and the choice images used to create this one weren't easy to pick out. It took a lot of trial and error. Like an absolute ton of it.
There is a SERIES of core tags introduced with this lora. It adds an entire backbone to FLUX that it simply doesn't have by default. The activation pattern is complex, but if you build your character similar to NAI, it'll appear similar to how NAI creates characters.
The potential and power of this model isn't to be understated. This is absolute powerhouse of a lora and it's potential is beyond my scope.
It STILL can produce some abominations if you aren't careful. If you stick with standard prompting and you stick with a logical order, you should be building beautiful art in no time with it.
Resolutions are: 512, 768, 816, 1024, 1216
Suggested steps: 16
FLUX guidance: 4 or 3-5 if it's stubborn, 15+ if it's very stubborn
CFG: 1
I ran it with 2 loopbacks. The first being an upscale 1.05x and a denoise at 0.72-0.88, and the second being a denoise 0.8 almost never changed, depending how many traits I want introduced or removed.
CORE TAG POOL:
anime - converts the styling of poses, characters, outfits, faces, and so on into anime
realistic - converts the styling to realistic
from front - a view from the front of a person, shoulder lined-up facing forward towards the viewer situation, where the center mass of the torso is facing the viewer.
from side - a view from the side of a person, the shoulder vertical facing the viewer situation, where the shoulders are vertical meaning the character is from the side
from behind - a view from directly behind the person
straight-on - a straight-on vertical angling view, meant for a horizontal planar angle
from above - a 45 to 90 degree tilt facing downward on an individual
from below - a 45 to 90 degree tilt facing upward on an individual
face - a face detail focused image, good for including face details specifically if they are stubborn
full body - a full body view of an individual, good for more complex poses
cowboy shot - the standard cowboy shot tag, works fairly well with anime, not so well with realism
looking at viewer, looking to the side, looking ahead
facing to the side, facing the viewer, facing away
looking back, looking forward
mixed tags create the intended mixed results, but they have mixed outcomes
from side, straight-on - a horizontal planar camera aimed at the side of individual or individuals
from front, from above - 45 degree tilt facing downward from camera above front
from side, from above - 45 degree tilt facing downward from camera above side
from behind, from above - 45 degree tilt facing downward from camera above behind
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front from side, from below
from front from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
Those tags may seem similar, but the order will often create very distinctly different outcomes. Using the from behind tag ahead of the from side, will for example weight the system towards behind rather than side, but you'll often see the upper torso twisting and the body angling 45 degrees in either direction
The outcome is mixed, but it's definitely workable.
traits, coloration, clothes, and so on also work
red hair, blue hair, green hair, white hair, black hair, gold hair, silver hair, blonde hair, brown hair, purple hair, pink hair, aqua hair
red eyes, blue eyes, green eyes, white eyes, black eyes, gold eyes, silver eyes, yellow eyes, brown eyes, purple eyes, pink eyes, aqua eyes
red latex bodysuit, blue latex bodysuit, green latex bodysuit, black latex bodysuit, white latex bodysuit, gold latex bodysuit, silver latex bodysuit, yellow latex bodysuit, brown latex bodysuit, purple latex bodysuit
red bikini, blue bikini, green bikini, black bikini, white bikini, yellow bikini, brown bikini, purple bikini, pink bikini
red dress, blue dress, green dress, black dress, white dress, yellow dress, brown dress, pink dress, purple dress
skirts, shirts, dresses, necklaces, full outfits
multiple materials; latex, metallic, denim, cotton, and so on
poses may or may not work in conjunction with the camera, may need tinkering
all fours
kneeling
lying
lying, on back
lying, on side
lying, upside down
kneeling, from behind
kneeling, from front
kneeling, from side
squatting
squatting, from behind
squatting, from front
squatting, from side
controlling legs and such can be really picky, so play with them a bit
legs
legs together
legs apart
legs spread
feet together
feet apart
hundreds of other tags used and included, millions of potential combinations
Use them in conjunction ahead of any specifiers for a person's traits, but after the prompt for flux itself.
PROMPTING:
Just, do it. Type whatever and see what happens. FLUX has a ton of information already, so use the poses and such to augment your images.
Example:
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes

a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
 a woman eating at a restaurant, from above, from behind, all fours, ass, thong
a woman eating at a restaurant, from above, from behind, all fours, ass, thong Yeah it worked. They usually do.
Yeah it worked. They usually do.
Legitimately, this thing should handle most insanity, but it will definitely be outside of my comprehensive scope. I've tried to mitigate the chaos and include enough pose tags to make it work, so try to stick to the more core and useful ones.
Over 430 separate failed attempts to create this, finally lead to a series of successful theories. I'll be making a full write-up of the necessary information and releasing the used training data likely this weekend. It was a long and difficult process. I hope you enjoy it everyone.
V2 Documentation:
Last night I was very tired, so I didn't finish compiling the full writeup and findings. Expect it asap, probably during the day while I'm at work I'll be running tests and marking values.
Flux Training Introduction:
Formerly, PDXL only required a small handful of images with danbooru tags to produce finetuned results comparable to NAI. Less images in that case was a strength due to it reducing potential, in this case less images did not work. It needed something, more. Some oomph with some power.
The model has a lot there, but the differentiations between the various learned data is considerably higher variance than expected at first. More variance means more potentials, and I couldn't figure out why it would work with the high variance.
After a bit of research I found that the model itself is so powerful BECAUSE of this. It can produce images that are "DIRECTED" based on depth, where the image is segmented and layered over another image using the noise of another image kind of like a guidepost to overlay atop of. It got me thinking, how exactly can I train >>THIS<< without destroying the model's core details. I was first thinking about how to do this with resizing, then I remembered bucketing duh. So this leads to the first piece here.
I basically went into this blind, setting settings based on suggestions and then determining outcome based on what I saw. It's a slow process, so I've been researching and reading papers on the side to speed things along. If I had the mental bandwidth I'd just do everything at once, but I'm only one person after all and I do have work to do. I basically threw the kitchen sink at it. If I had more attention to spare I'd have run 50 of these things at once, but I legitimately don't have the time of day to set something like that up. I could pay for it, but I can't set it up.
I went with what I thought would be the best format based on my experience with SD1.5, SDXL, and PDXL lora trainings. It turned out OKAY, but there's definitely something distinctly wrong with these and I'll get into details as I go.
Training Formatting:
I ran a few tests.
Test 1 - 750 random images from my danbooru sample:
UNET LR - 4e-4
I noticed most of the other elements didn't matter much and could be left default, except the attention to resolution bucketing.
1024x1024 only, cropped center
Between 2k-12k steps
I chose 750 random images from one of the random danbooru tag pools and ensured the tags were uniform.
Ran moat tagger on them and appended the tags to the tag file, ensuring the tags didn't overwrite.
The outcome wasn't promising. The chaos is expected. Introduction of new human elements such as genitalia was either hit or miss, or simply didn't exist most of the time. That's pretty much in line with everyone else's findings I've seen.
I DID NOT expect the entire model to suffer though, as the tags oftentimes didn't overlap I thought.
I ran this test twice and have two useless loras at about 12k steps each. Testing the 1k to 8k showed nearly nothing useful in deviation towards any sort of goal, even paying close attention to the tag pool's peaks and curves.
There's something else here. Something I missed, and I don't think it's a humanistic or clip description. There's something... more.
Around this failure point I made a discovery. This depth system, is interpolative and based on two entirely different and deviant prompts. These two prompts are in fact interpolative and cooperative. How it determines this use is unknown to me, but I'll be reading the papers today to figure out the math involved.
Test 2 - 10 images:
UNET LR - 0.001 <<< very powerful LR
256x256, 512x512, 768x768, 1024x1024
The initial steps were showing some deviation, similar to how much burn it imposed into the SD3 tests. It wasn't good though. The bleeding started at around step 500 or so. It was basically useless by step 1000. I know I'm basically using repeat here, but it definitely seemed to be a good experiment to fail.
Deviations are highly damaging here. It introduces a new context element, and then turns it into a snack machine. Replaces people's elements with nearly nothing useful or completely burned artifacts similar to how a badly set up inpaint happens. It was interesting how much damage FLUX can endure and STILL function. This test was quite potent showing FLUX's resilience, and it was damn resistant to my attempts.
This was a failure, require additional tests with different settings.
Test 3 - 500 pose images:
UNET LR - 4e-4 <<< This should require this divided by 4 and given twice the steps.
FULL bucketing - 256x256, 256x316, etc etc etc. I let it go wild and gave it a ton of images of various sizes and let it bucket everything. It was quite the unexpected outcome.
The outcome is LITERALLY the core of this consistency model, that's how powerful the outcome was. It seems to have done a bit more damage than I thought, but it was actually quite the thing.
Something to note; Anime generally doesn't use depth of field. This model seems to THRIVE on depth of field and blur to differentiate depth. There need to be a type of depth controlnet applied to these images to ensure depth variance, but I'm not sure off the cuff how to pull this one off. Training depth maps along with normal maps might work, but it also might completely destroy the model due to the model not having negative prompting.
More tests necessary. Additional training data required. Additional information required.
Test 4 - 5000 consistency bundle:
UNET LR - 4e-4 <<< This should be divided by 40 and given 20x the steps, give or take. Training something like this into the core model isn't simple, nor is it something that can be done quickly. The math isn't good with the current process to ensure the core model isn't broken, so I ran this and released the initial findings.
I had written up a whole section here plus a follow-up section and I was leading up to my findings section but I clicked back on my mouse button and it removed the whole thing so I'll need to rewrite it later.
The big failures:
The learning rate was WAY TOO HIGH for my initial 12k step loras. The entire system is based on gradient learning yes, but the rate at which I taught the thing was TOO HIGH for it to actually retain the information without it breaking the model. Simply put, I didn't burn them, I retrained the model to do what I wanted. The problem is, I didn't know what i wanted, so the entire system was based on a series of things that were not directed and without gradient depth. So it was doomed to fail, more steps or not.
STYLE for FLUX isn't what people think style IS based on PDXL and SD1.5. The gradient system will stylize things yes, but the entire structure heavily suffers when you attempt to impose TOO MUCH information too quickly. It's HIGHLY destructive, in comparison to PDXL loras which were more of an imposition set of loras. They would AUGMENT what was already there considerably more than training entirely new information into something.
Critical Findings:
ALPHA, ALPHA, and MORE ALPHA<<<< This system runs so heavily on alpha gradients that it's not funny. Everything MUST be specifically handled to handle alpha gradients based on photograph based details. distance, depth, ratio, rotation, offset, and so on are all key integral pieces to this model's composition and to create a proper compositional stylizer the entire thing needs those details in more than a single prompt.
EVERYTHING must be described properly. Simple danbooru tagging is essentially just style. You're forcing the system to recognize the style of the system you wish to implement, so you cannot simply impose new concepts without including the necessary concept allocation tags. Otherwise the style and concept linker will fail, giving you absolute garbage output. Garbage in, garbage out.
Pose training is HIGHLY potent when using LARGE amounts of pose information. The system ALREADY recognizes most of the tags, we just don't know what it recognizes yet. Pose training to link what IS THERE to what YOU WANT using specific tags, is going to be highly potent for tag organization and finetuning.
Step Documentation;
v2 - 5572 images -> 92 poses -> 4000 steps FLUX
The original goal to bring NAI to SDXL has now been applied to FLUX as well. Stay tuned for more versions in the future.
Stability testing required, so far it's showing some distinct capability beyond anything PDXL can handle. It needs additional training, but it's substantially more powerful than expected at such a low step count.
I believe the first layer of pose training is only about 500 images give or take, so that should be what's mostly cutting through. The full training data will be released on HuggingFace when I get together an organized image set and count. I don't want to release the incorrect images or leave garbage in the mix that I picked out.
Continue reading here:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Important References:
I don't smoke, but FLUX needs one once in a while.
A workflow and image generation assistant. I stuck mostly with the core ComfyUI nodes, but continually use others to experiment and save.
A very powerful and difficult to understand AI model with a tremendous amount of potential.
Without them, I would never have never wanted to make this at all. A big shout out to all the staff at NAI for their hard work and the powerhouse beast of an image generator, with their absolute chad of a writing assistant. Throw money at them.
They created flux and deserve a huge portion, if not the majority of the credit for the flexibility of it's model. I'm simply finetuning and directing what feels like a leviathan to it's destination.
A highly potent and powerful tag assistant. I almost wrote my own until I found this powerhouse.
What I used to train my Flux versions. It's a little touchy and finnicky, but it works really well on a multitude of systems and does the job.
Can't forget the rival on the battlefield. The beast is an absolute monster at generating images of a huge gradient field, an invaluable research and understanding tool, and a big inspiration for this direction and progress.