AutoMask IPA Img/Vid-2-Vid LCM AnimateDiff Workflow for ComfyUI

세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
Introduction
This workflow allows you to segment up to 8 different elements from an input image, or video, into colored masks for IPA to stylize and animate each element with.
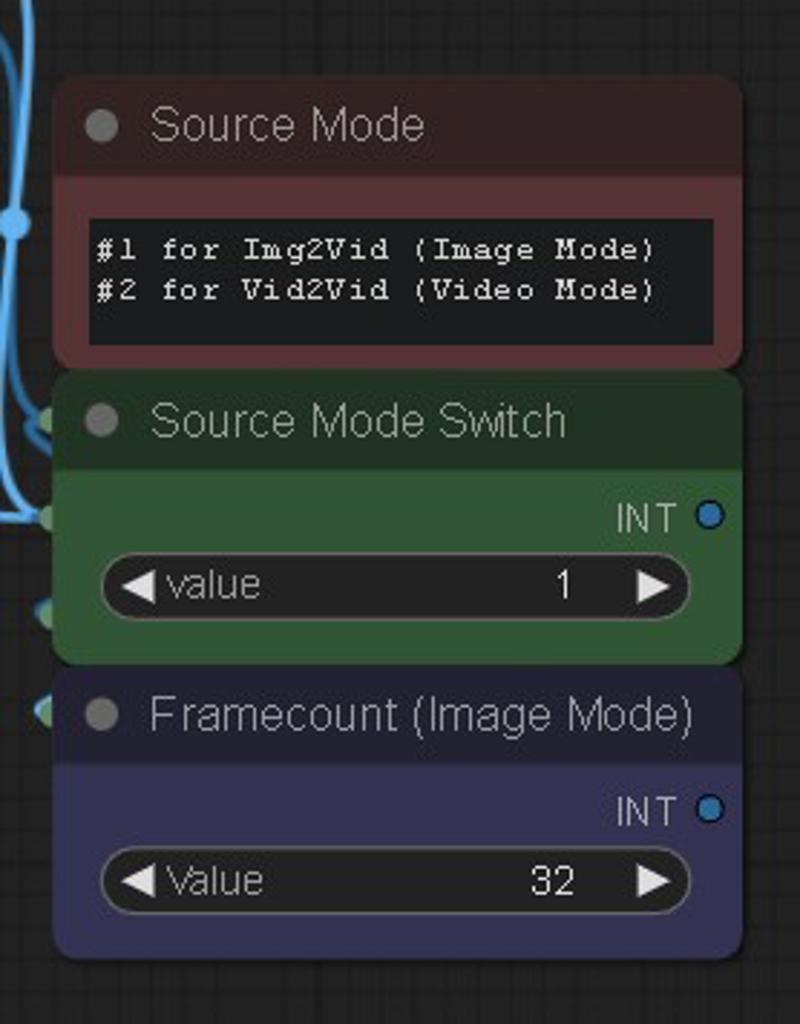
First, select your source input mode in the middle with the switch. 1 is Image Mode, 2 is Video Mode.
At the top of each colored layer is a GDINO-SAM node and a prompt field to type in which element to isolate from your input. The black group is your background and anything that isn't masked. The prompt fields are filled with some basic examples, but you can change them into whatever you want related to your input, like objects, landscape stuff, or even colors.
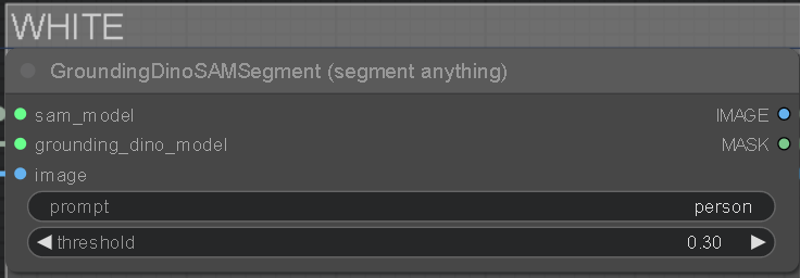 You can increase the threshold under the prompt to affect how strong it tries to isolate the keyword. Lower threshold is weaker and will mask bleed into other things, too high and it won't mask anything. A good spot is around 0.30.
You can increase the threshold under the prompt to affect how strong it tries to isolate the keyword. Lower threshold is weaker and will mask bleed into other things, too high and it won't mask anything. A good spot is around 0.30.
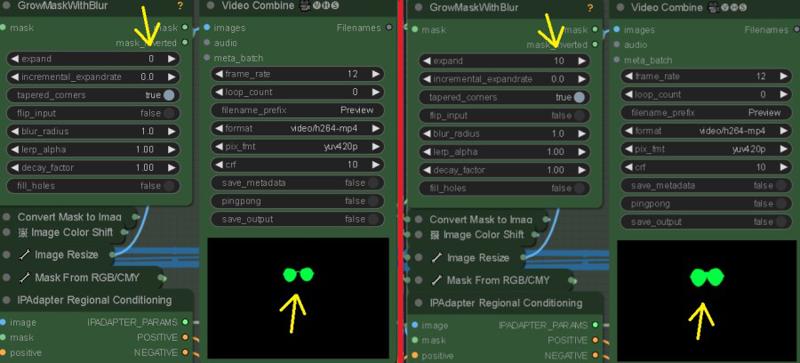
On the "GrowMaskWithBlur" node, you can customize the mask using the expand and blur radius settings.
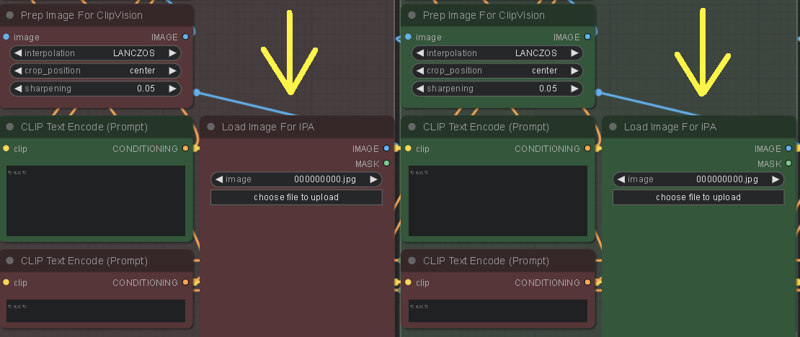
You also need to load up some images into the "Load Image For IPA" Nodes for each colored mask group you're using. These will style your masks.
Customizing the "weight" in the "IPAdapter Advanced" node, can increase how much the image is stylized into the mask. Also, "weight_type" can also have an affect. "Ease In-Out" and "Linear" are good to play around with.

The Black mask will stylize everything that isn't masked, and creates the mask for the Source Input Background Mode if chosen. The colored masks are merged together and saved for visual/editing purposes only. Disable their "save output" if you wish. To save VRAM, it's recommended to let the Black mask be the last and most behind element in the scene, like a sky.
Colored masks stack as followed: far (White) to near (Yellow). If creating a custom stack, order the colors accordingly to the distance of scene elements..
Colored mask layers not being used should be bypassed with the "Fast Groups Bypasser" node. You can also bypass the "Input Gen & ControlNet" so you can fine-tune your masks before going into the KSampler.
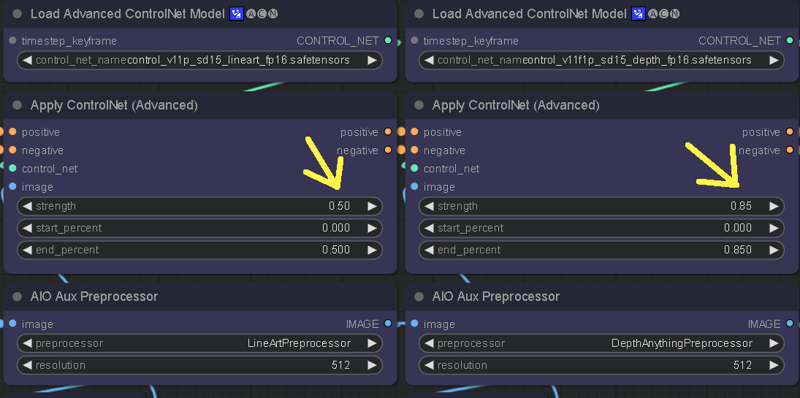
The ControlNet weights can be adjusted to control how delineated the IPA stylization is. Lower weight on the CN will give more freedom to the masks and retain less of the Source Input edges, causing mask bleed. Higher CN weight will produce more of the Source Input structure, but less quality on the stylization.
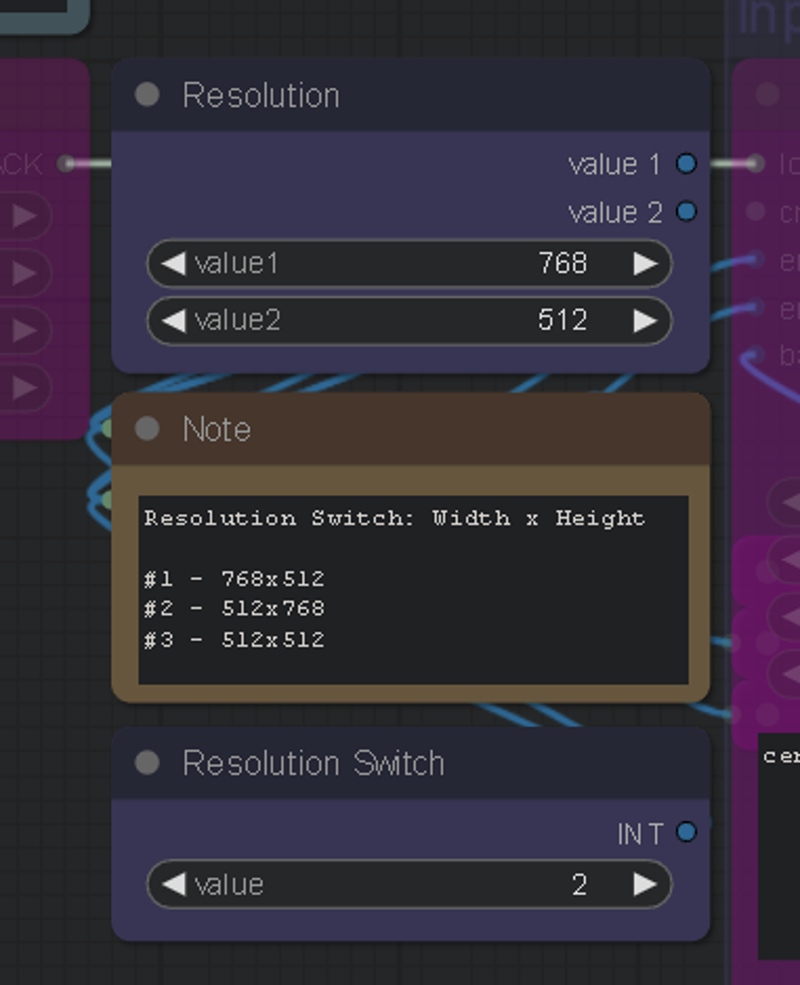
There's also a resolution switch to quickly change your aspect ratio, you can edit the resolution to your liking as well.
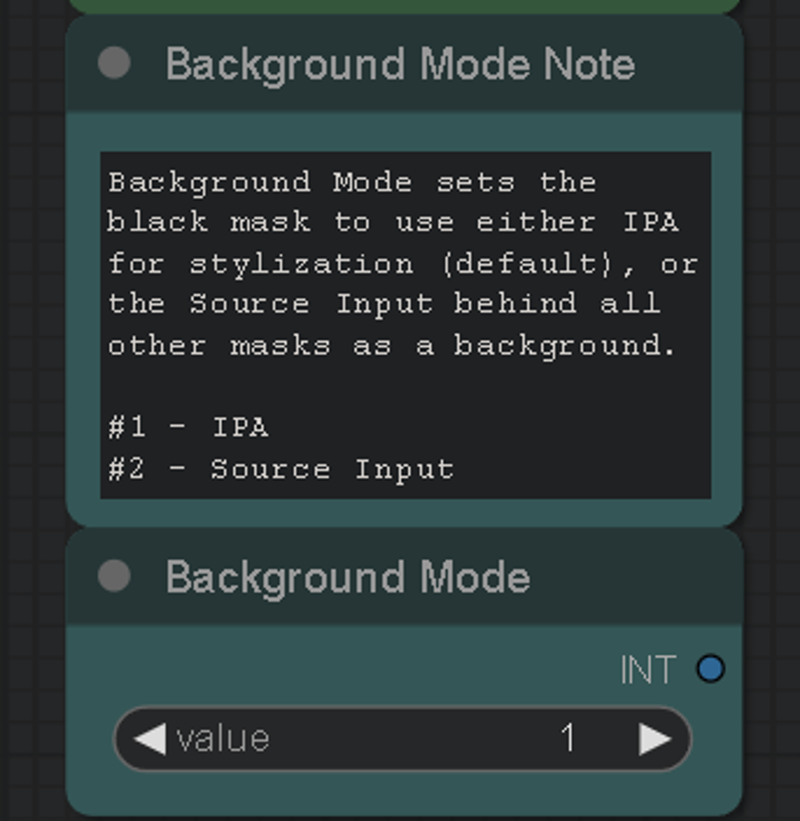
May 24th, version 4 update, Background Mode was also added. This lets you stylize your masks while using your source input as the background, instead of the background mask being stylized by IPA.
Requirements
The "Segmenty Anything SAM model (ViT-H)" model is required for this, to get it: Go to manager > Install Models > Type "sam" > Install: sam_vit_h_4b8939.pth
GroundingDino is also required, but should automatically download on first use. If it doesn't, you can grab it from here: https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha2/groundingdino_swinb_cogcoor.pth
Or here: https://huggingface.co/ShilongLiu/GroundingDINO/tree/main
If you need ControlNet models, you can get them here: https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main
This workflow is in LCM mode by default. You can browse CivitAI and choose your favorite LCM checkpoint. My favorites are PhotonLCM and DelusionsLCM. You can also just use any 1.5 checkpoint and activate the LCM LoRA in the "LoRA stacker" to the far left of the "Efficient Loader".
You can download the LCM LoRA here: https://huggingface.co/wangfuyun/AnimateLCM/blob/main/AnimateLCM_sd15_t2v_lora.safetensors (Install into your SD LoRAs folder)
And the LCM AnimateDiff Model here: https://huggingface.co/wangfuyun/AnimateLCM/blob/main/AnimateLCM_sd15_t2v.ckpt (Install into: "ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\models")
I also really enjoy using the Shatter LCM AnimateDiff motion LoRA by PxlPshr. You can find it here on CivitAI.
Special thanks to
@matt3o for the awesome IPA updates, and everyone else who contributes to the community and all the tools we use. A big shoutout to @Purz from whom I've learned so much, and this workflow was inspired from, and @AndyXR for beta testing.
If you like my work, you can find my channels at: https://linktr.ee/artontap