SD3 Pack - txt2img, img2img, 4K Upscaling








詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
SD3 Control Net update!
much information and tips on the settings are in the video :D
Canny, Pose and Tile - updated the pack with four new workflows.
txt2img with controlnets
img2img with controlnets
& Blip Auto Prompt versions of both
You will Need:
https://huggingface.co/InstantX/SD3-Controlnet-Canny
https://huggingface.co/InstantX/SD3-Controlnet-Pose
https://huggingface.co/InstantX/SD3-Controlnet-Tile
place inside /models/controlnet/SD3/
SD3 is here!
installation / explanation (pack v1 video)
the latest non-commercial image generation model has arrrived
simply download the weights here:
https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
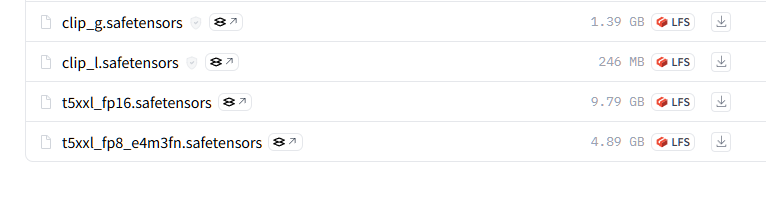
10.6 GB sd3_medium_incl_clips_t5xxlfp8.safetensors - contains all 3 encoders, T5 in FP8
15.8 GB sd3_medium_incl_clips_t5xxlfp16.safetensors - contains all 3 encoders, T5 is FP16
5.97 GB sd3_medium_incl_clips.safetensors - contains only CLIP G+L
4.34 GB sd3_medium.safetensors - contains no text encoders in the checkpoint.
you can choose to load the CLIP text encoders separately, if you download them to your models/CLIP/ folder. The weights are here:
https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
! UPDATE COMFYUI !
Update: 16th June: adds image 2 image workflow
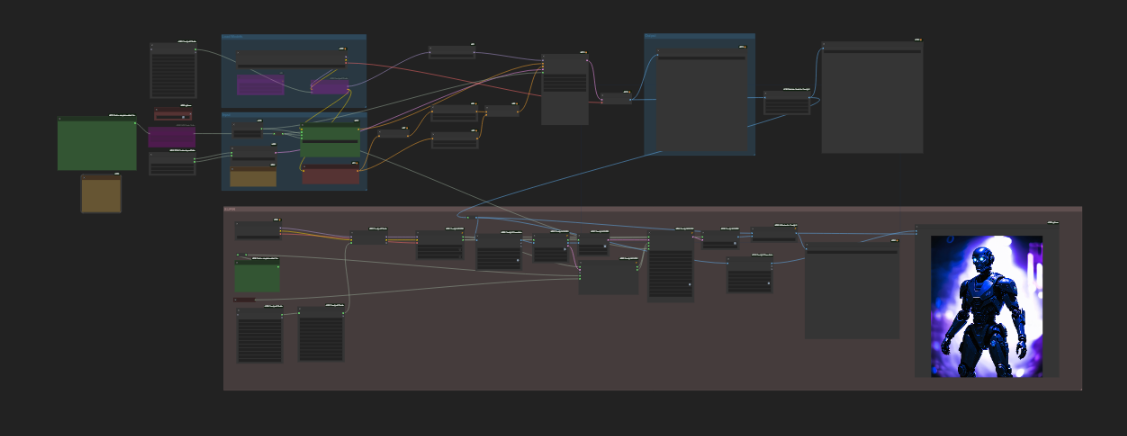
Pack contains 3 workflows:
SD3-HYPER-SUPIR
- SD3-medium
- 1MP aspect ratio modulo 64
- random line for batch prompting
- lora loader (chaotic)
- Triple Clip Encode
- 4K 16:9 Hyper SUPIR upscaling
Although SDXL Lora do have an effect on generation (G+L), they are not guiding toward the trained tokens.
SD3 supports multi line prompting so the "random line" batch prompting is disabled by default.
SD3-HYPER-SUPIR-Reactor
- adds Reactor Restore Face
SD3-img2img-HYPER-SUPIR
- adds img2img
- basic version features less custom nodes
Reactor version allows Facefix, not faceswap, although that can be added.