try1.0(sdxl fine tune practice) sdxl 的微调尝试练习





















詳細
ファイルをダウンロード
モデル説明
このモデルのトレーニングデータセットはHugging Faceに公開されています。必要に応じてダウンロードできます
https://huggingface.co/datasets/TLFZ/civitai-try1.0-model-train-dataset
try1.0
これはNAI3を模倣してAnimagineV3.1をファインチューニングした試みであり、アーティストのタグを付与しています。過小適合と過剰適合が同時に発生する可能性が高い、粗い初心者向けの試みです(可能であればダウンロードしないでください)。
これはNAI3のAnimagineファインチューニングを模倣した試みであり、アーティストのタグを付けています。過小適合と過剰適合が併存する、粗い初心者向けの試みです(可能であればダウンロードしないでください)。
try1.01
このバージョンでは、トレーニングデータセットのタグ付けと画像コンテンツを変更したため、前のバージョンと比べて大きな進歩があります。
大まかな手順は以下の通りです:
まずVPNを使って海外アクセスを実行
次に、NAI3の交流チャット(以前の元素法典のNovelAIグループで、NAI3の登場後に「解構法典」グループが作られ、QQグループ番号は852429527です。B站で「novelai」と検索し、関連動画の概要欄から取得できます。個別メッセージは不要です。私のスキルも限られています……現存するツールを使ってモデルを作成するだけです(グループメンバーは私より優れています:))のメンバーが使用しているNAI3アーティストコーパスのスタイル融合テストセット、たとえば「【腾讯文档】【精簡200アーティスト】~K7の個人的アーティストランキング」や「300スタイル法典:融合タイプ」などを参考にします。
以下のような画像です:
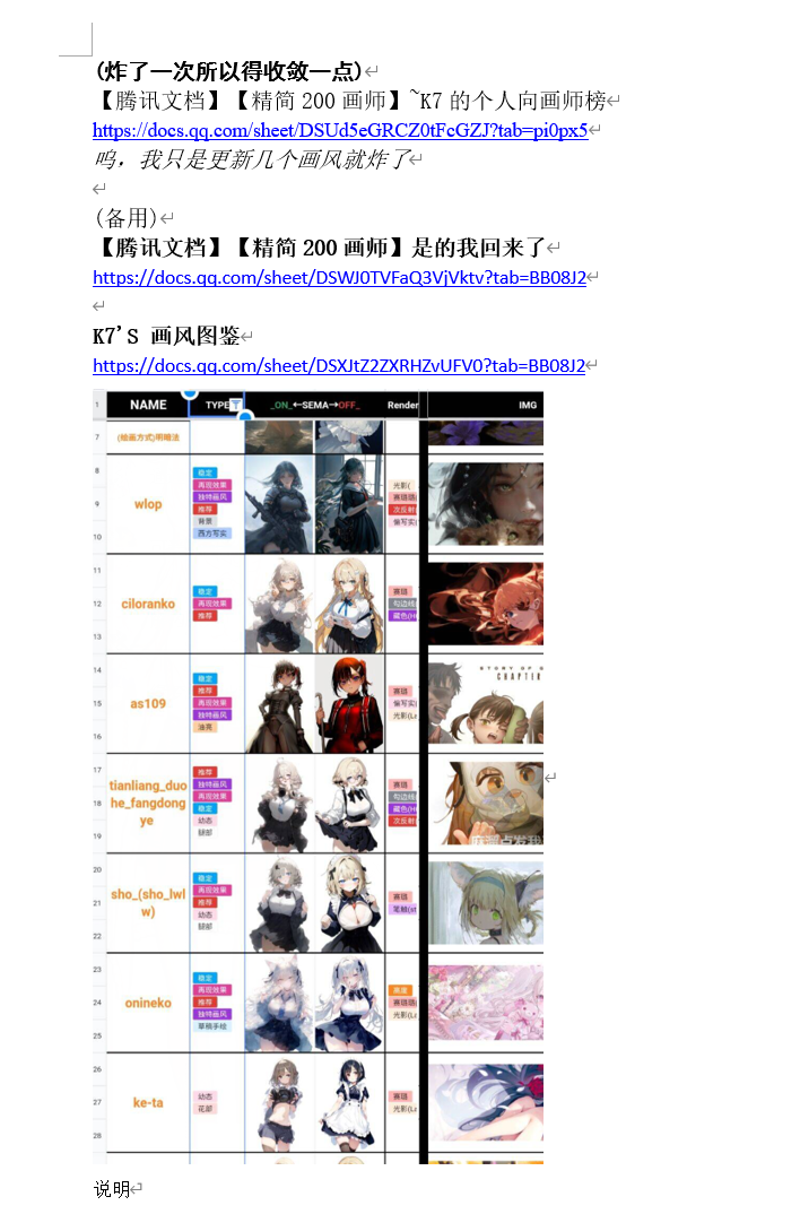


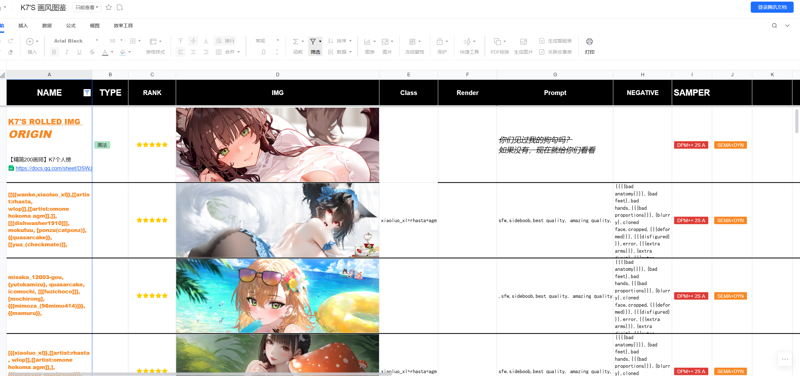

好きなアーティストや複合スタイルを選び、目的とするスタイルの融合効果に基づいて関連するアーティストの名前を収集
その後、GPT-4oとグループメンバーの支援・助言のもと、waifucのクローラーを使ってDanbooruとGelbooruの関連アーティストタグのすべての画像と、それらの手動品質タグ付けを収集
あるいはExHentaiサイトからqbittorrentを使って各ギャラリーのBTシードファイルをダウンロードし、アーティストのFanboxまたはPatreonの無修正高画質画像パッケージを取得
次に、クラックされたDuplicate Cleaner 5ソフトウェアを使って、非常に類似した差分画像を大部分削除
人手(人間の知能……)で、アーティストの初期スタイルの画像をほぼすべて削除(このステップも非常に重要です)。ただし、美学スコアリングモデルは存在するようですが、私はあまり役に立たないと感じています……美学モデルは、同じアーティストのスタイル内での優れた、あるいは初期のスタイルの画像を十分に区別できないようです。あるいは、優れた美学スコアリングモデルを見つけていないだけかもしれません……
そしてwaifuc内のスクリプトを使って、透明背景の画像を白色背景に変更し、線画と白黒画像を削除
次に、tagger1.4のswinv2-v3モデルを使って各アーティストフォルダにタグ付けし、アーティスト名のプロンプトを追加。しきい値を0.35に、人物しきい値を0.1に設定して機械タグ付け
そして最後(おそらく最も重要なステップ!!!)、BooruDatasetTagManagerソフトウェアを使って人手で見落とされたタグを追加し、誤ったタグを削除・修正。この人手タグ付けのアイデアと技術は、CivitAIのトップページにあるrullesさんの記事「Prompt Guidance, Tags to Avoid and useful tags to include」https://civitai.com/articles/1009 から学びました。またDanbooruや類似の画像ホスティングサイトのウィキでは、タグ付け方法や使用可能なタグを確認できます(ただし、一部のタグの例画像は非常に過激です……)。
最後に、ローカルの3090 GPUと、https://github.com/Akegarasu/lora-scripts からクローンしたkohya-ss/sd-scripts用のLoRA & DreamboothトレーニングGUI&スクリプトプリセット&ワンクリックトレーニング環境を使って、DreamboothのSDXLファインチューニングスクリプトを実行します。
https://github.com/Akegarasu/lora-scripts合計31人のアーティストの画像集、約7613枚の画像を使用。1エポックあたり約11063回のリピートを8エポック実行。合計バッチサイズは約88504。現在、関連するアーティストのスタイルを7〜9割程度再現できます(私は50万〜100万ステップがベストだと推測しますが、トレーニング時間を短縮したいので、高学習率を選択し、トレーニングステップ数を減らしました。24GBのVRAMはやや遅く、8エポックは約17時間かかりました)
また、NAI3のアーティストコーパス形式による複合スタイルの出力もサポートしており、例画像にも関連するプロンプトが含まれています。
角、髪、動物の耳など、機械タグ付けが苦手な部分にのみ注目したため、個人の精力、VPNの品質、ネット速度の制限により、人物タグの修正が完全ではなく、物体が混在する場合があります。特に、一部の人物名が認識できなかったり、他のキャラクターと誤認識されることがあり、非常に困ります。
次回のトレーニングでは、現行のトレーニングプロセスを継続し、3〜4人のアーティストスタイルを追加しつつ、トレーニングデータのタグ付けの学習と修正に大部分の精力を集中する予定です。
上記をまとめると、楽しくお使いください……(ただし、このモデルを利益目的で使用しないでください。トレーニングデータセットはアーティストの許可を得ていないため、このモデルはAIに関する学習と経験共有の目的のみに使用してください)。
以下はファインチューニングに使用したパラメータです
model_train_type = "sdxl-finetune" pretrained_model_name_or_path = "D:/stablediffusion/lora-scripts/sd-models/animagineXLV31_v31.safetensors" vae = "D:/stablediffusion/sdwebuiakiv4.2/models/VAE/sdxl-vae-fp16-fix.safetensors" train_data_dir = "D:/stablediffusion/lora-scripts/train/try" resolution = "1024,1024" enable_bucket = true min_bucket_reso = 256 max_bucket_reso = 1536 bucket_reso_steps = 32 output_name = "try1.01" output_dir = "./output" save_model_as = "safetensors" save_precision = "bf16" save_every_n_epochs = 1 save_state = true max_train_epochs = 20 train_batch_size = 1 gradient_checkpointing = true gradient_accumulation_steps = 32 learning_rate = 0.000007 learning_rate_te1 = 5e-7 learning_rate_te2 = 5e-7 lr_scheduler = "cosine_with_restarts" lr_warmup_steps = 0 lr_scheduler_num_cycles = 3 optimizer_type = "Lion8bit" min_snr_gamma = 5 log_with = "tensorboard" logging_dir = "./logs" caption_extension = ".txt" shuffle_caption = true weighted_captions = false keep_tokens = 1 max_token_length = 255 caption_tag_dropout_rate = 0.1 multires_noise_iterations = 6 multires_noise_discount = 0.3 seed = 1337 no_token_padding = false mixed_precision = "bf16" full_bf16 = true xformers = true lowram = false cache_latents = true cache_latents_to_disk = true persistent_data_loader_workers = true train_text_encoder = true
try1.02
アーティストをもう少し追加し、現在のアーティストスタイルの混合はアーティストプロンプトで実行でき、以前のバージョンよりやや生動的になったようです(ただし、人体構造のエラーが増える可能性があります)。トレーニングデータセットは9500枚の画像に増加し、テストした結果、やや過剰適合の単一スタイルと複合スタイルの混合が良い効果を示したため、この選択を採用しました。
また、waifusetというデータベース管理ソフト(あるいはスクリプト?)を利用しました。
これは非常に、あるいは9割方優れており、若干のバグがありますが、市販の動画での使用方法の紹介はほとんどないのが現状です。100〜200枚の単一スタイルでは問題ありませんが、1万枚を超えると、画像の重複タグ削除、タグ付け、誤タグ修正にはスクリプト操作が必要になります。(自分自身が忘れてしまわないように、使用方法のチュートリアルを作成したいと思っています)
もう一つ、以前のバージョンのv1.01モデルは8エポックでトレーニングしたため、やや過剰適合していました。その後、5エポックでテストした方が効果が良いことが分かったので、v1.01モデルは5エポックに変更しました。そのため、モデルのハッシュ値が変わります(モデルはハッシュ値で識別してください。私は自分が使いやすいと感じるモデルをできる限りアップロードしていますが、時々適当に変更してアップロードしてしまうことがあります……)。
新しいプロンプトはv1.02バージョンのプロンプトインターフェースで展開してコピー・検索できます。
(100人のアーティストになると、おそらくやりきれないと思います)
トレーニングデータセット(画像とtxtファイル)はすでに30GBに達しています。現在のスタイル構築はDanbooruやPixivから直接スクリプトでダウンロードし、tagger1.4 v3で追加タグ付け、重複タグ削除、一括解析とタグ整理を行っています(しかし、大量の人物タグが付いておらず、Danbooruもtagger1.4も認識・タグ付けできていないことが多々あります。自分で一つずつ確認する必要があり、例えば「焼金の李恩菲尔德」の公式イラストは、Danbooruやtagger1.4の両方でタグ付けされていません。本人と対応するDanbooruタグは確かに存在するのですが……もう呆れ果てています……)
皆がDanbooruをスクリプトでダウンロードして品質を求めるなら、ExHentaiのシードファイルを手動でダウンロードすることも検討すべきです。
ふと、ExHentaiの特定のアーティスト名やカテゴリのギャラリーのシードファイルをスクリプトでダウンロードできないだろうか?と考えました。
たとえば、まずダウンロードしたいアーティスト名を選択し、言語モデルがサイトの内蔵分類器で事前に検索し、画像ギャラリーのタイトルと概要が一致するか確認した上で、重複のないギャラリーのシードファイルだけをダウンロードするのはどうでしょうか?時間に関しては、言語モデルがアーティストの最も古いギャラリーと最新のギャラリーの間の中間期のギャラリー、あるいはサイトの時間順に2022年や2023年以降のシードをダウンロードするように選択するのも可能ではないでしょうか?(何を言っているかわからないが、適当に考えたこと)でも、結局人間の知能(手動)が最も安全です……
などと、琥珀青葉さんがすでに同様のモデルをすでに訓練していたことを発見しました……/model/399873?modelVersionId=546178 しまいには、自分は無駄に輪を再発明しているのではないかと疑問に思いました……(琥珀青葉さん、本物ですか?笑)
皆さんは、琥珀青葉さんのモデルをぜひ使ってください!