Fursuit Head LoRA for PonyXL






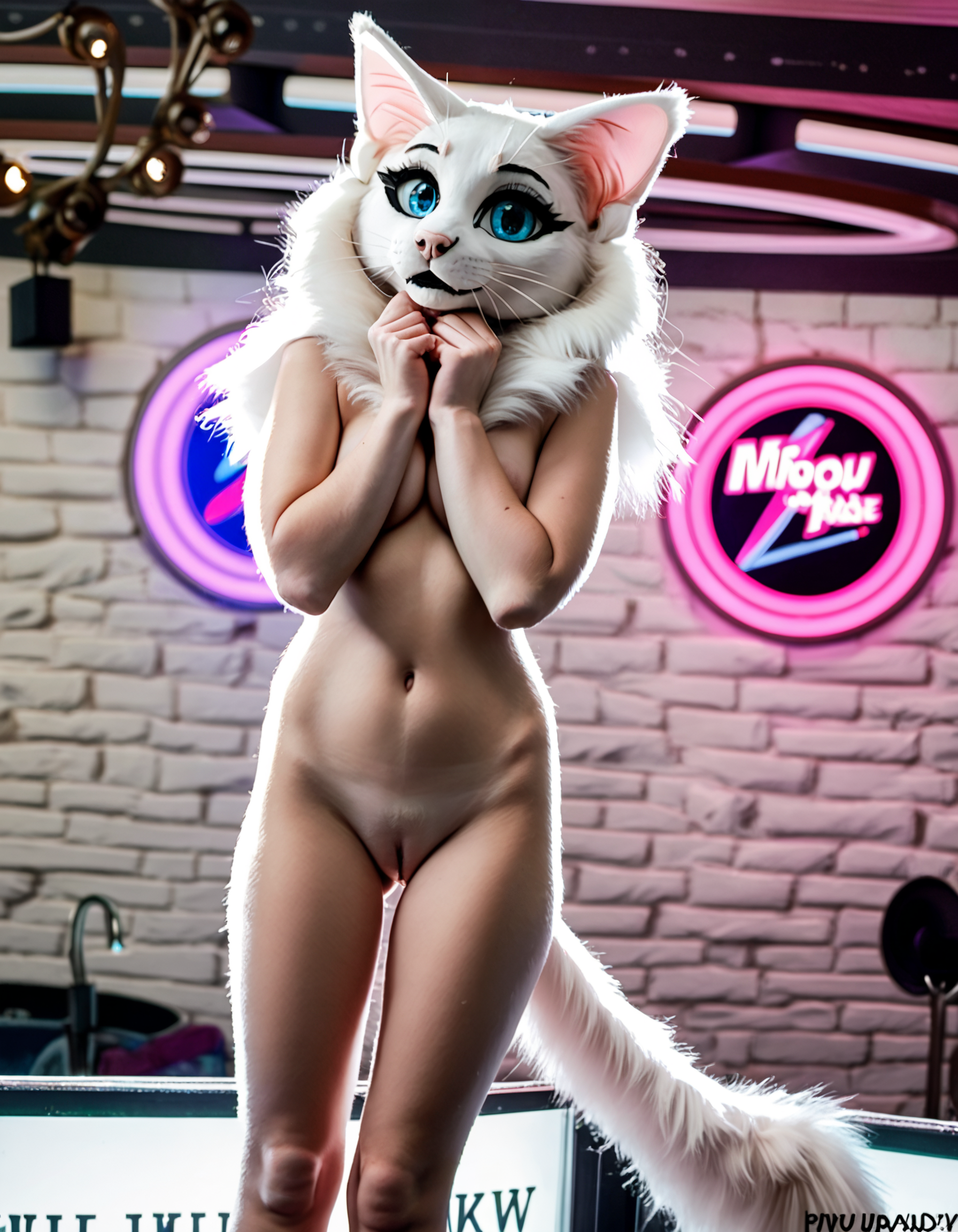










详情
下载文件 (1)
关于此版本
模型描述
Fursuit Head LoRA for PonyXL models.
PonyXL does understand the concept of fursuits, but not the concept of partial fursuits or fursuit heads, and even then generation quality tends to be spotty at best.
Lora was trained off 76 high-quality images of people wearing a variety of different species of fursuit heads in a variety of poses in OneTrainer using Prodigy at 10 epochs and 2 repeats. Masked training and heavy image prompting was used to focus predominantly on the concept of a fursuit head itself.
Training was done on a custom model merge of a Everclear and Pony Realism.
Dataset was composed of 50/50 real photographs and illustrations. Of that, a split of 25/75 of SFW and NSFW was used. A split of 50/50 male and female was attempted, but dataset is primarily composed of males.
Recommended Settings:
Keyword:
furryzsuithead mask
Negative Prompts:
Complex Mask, Feral
Situational Negative Prompts:
Tail, Gloves, Shoes, Paws, Anthro
Recommended Min-Max Weight Range:
0.4 - 0.8
Recommended Precise Weight Range:
0.55 - 0.75 (Depending on prompt)
Notes and Considerations:
XY Prompts were NOT generated with recommended negatives, hence the disparity in quality compared to example images
Lora seems to function quite well when tag is prefixed with "[Species] AND/OR [Color Fur/Scales] furryzsuithead mask", as can be seen in the example images, but adherence tends to decrease the more niche the species, and the less "standard" the facial structure (species with prominent snouts tend to work best)
Because "Mask" was used as the classifier for training, the colors and style associated with "masks" in the base model (typical Mexican-style face masks) can bleed over depending on prompting; this can (often) be mitigated fairly well with higher weights, color prompting, and the tag "Complex Mask" in the negative prompt
Whilst NSFW generations usually don't require "human" in the positive prompt, SFW generations have a propensity to generate stuffed toy animals rather than humans even with the recommended negative prompts, so adding "human" to the positive prompt is usually necessary
I am not particularly skilled at LoRA training, meaning the LoRA WILL alter image composition & bleed to other aspects of the image in a potentially less desirable way, though effect seems to be less prominent the lower the weighting
Whilst masked training helped, because training data was heavily prompted, expect various other prompt tags to be impacted to some extent
Because the model it was trained on was a realistic model and I don't have non-realistic models downloaded, I cannot say whether it will work well in non-realistic models, but feel free to share your results
If you have any suggestions to mitigate the above issues either as they exist or in potential future releases, please let me know!
OneTrainer Parameters:
LoRA Rank:
128
LoRA Alpha:
2
Dropout Probability:
0.01
Optimizer:
Prodigy
Scheduler:
Cosine
Epochs:
10
Repeats per Epoch:
2
LR:
1
LR Cycles:
1
Bath + Accumulation:
1
Stop Training Text Encoder After:
8 Epochs
Stop Training Unet After:
Never
Noising Weight:
-0.1
Noising Bias:
0.45
Unmasked Weight + Probability:
0.09
MSE Strength:
0.75
MAE Strength:
0.25
Loss Weight Function:
Debiased Estimation
Prodigy Settings:
Beta 1:
0.9
Beta 2:
0.995
EPS:
1e-08
Weight Decay:
0.005
Decouple:
True
Safeguard Warmup:
True
Bias Correction:
False
Initial D:
1e-06
D Coefficient:
1
Growth Rate:
inf