ComfyUI Base Workflow Text-L, Text-G, Lora & CivitAi Optimized













詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
I often get asked if I can share my beginner workflow for ComfyUI. Here it is. I always hesitate a bit because there is no universal ComfyUI workflow that always conjures up perfect images for all scenarios. However, this workflow very often forms the basis for further workflows. My focus is on three areas:
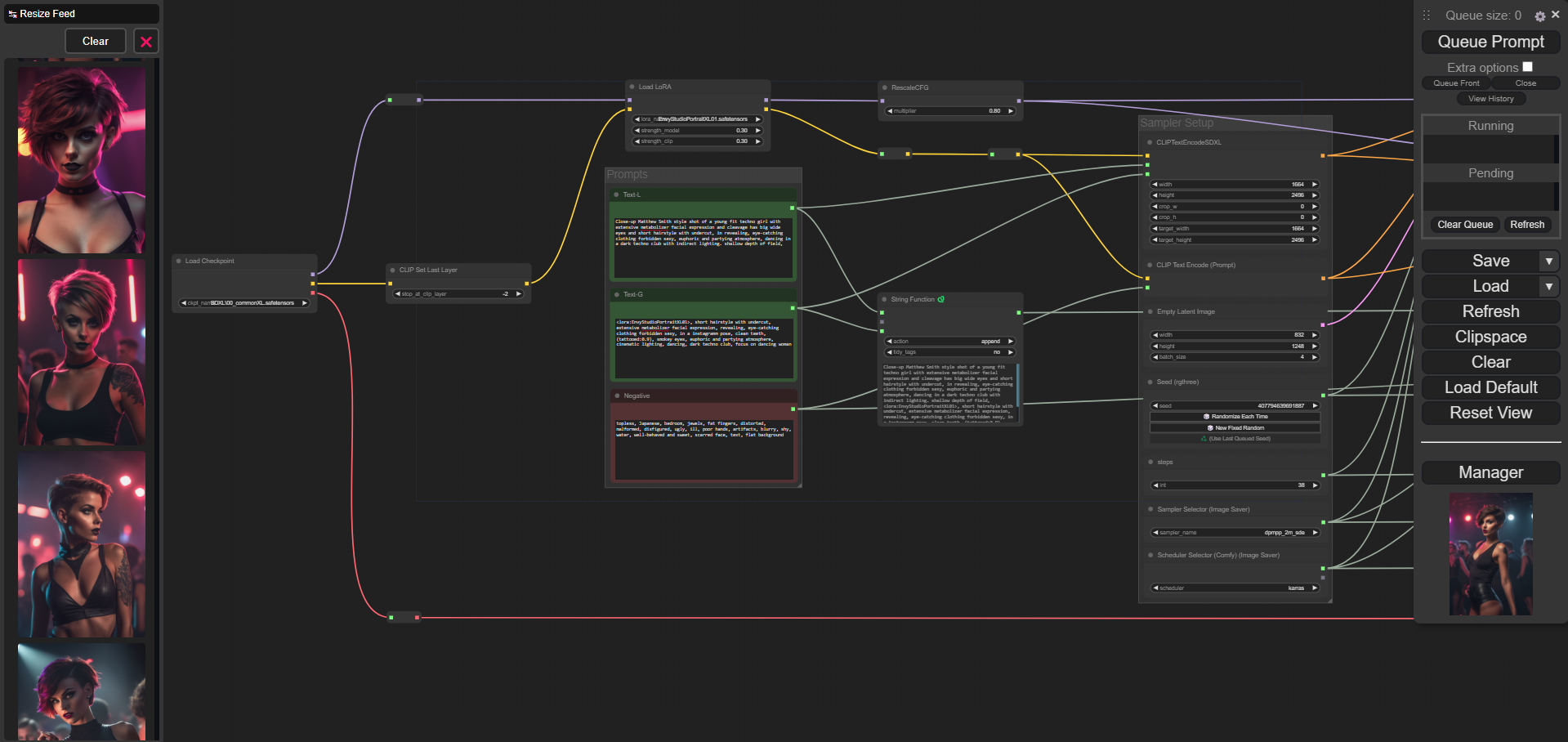
SDXL Prompt with Text-L, Text-G & Negative Encoder.
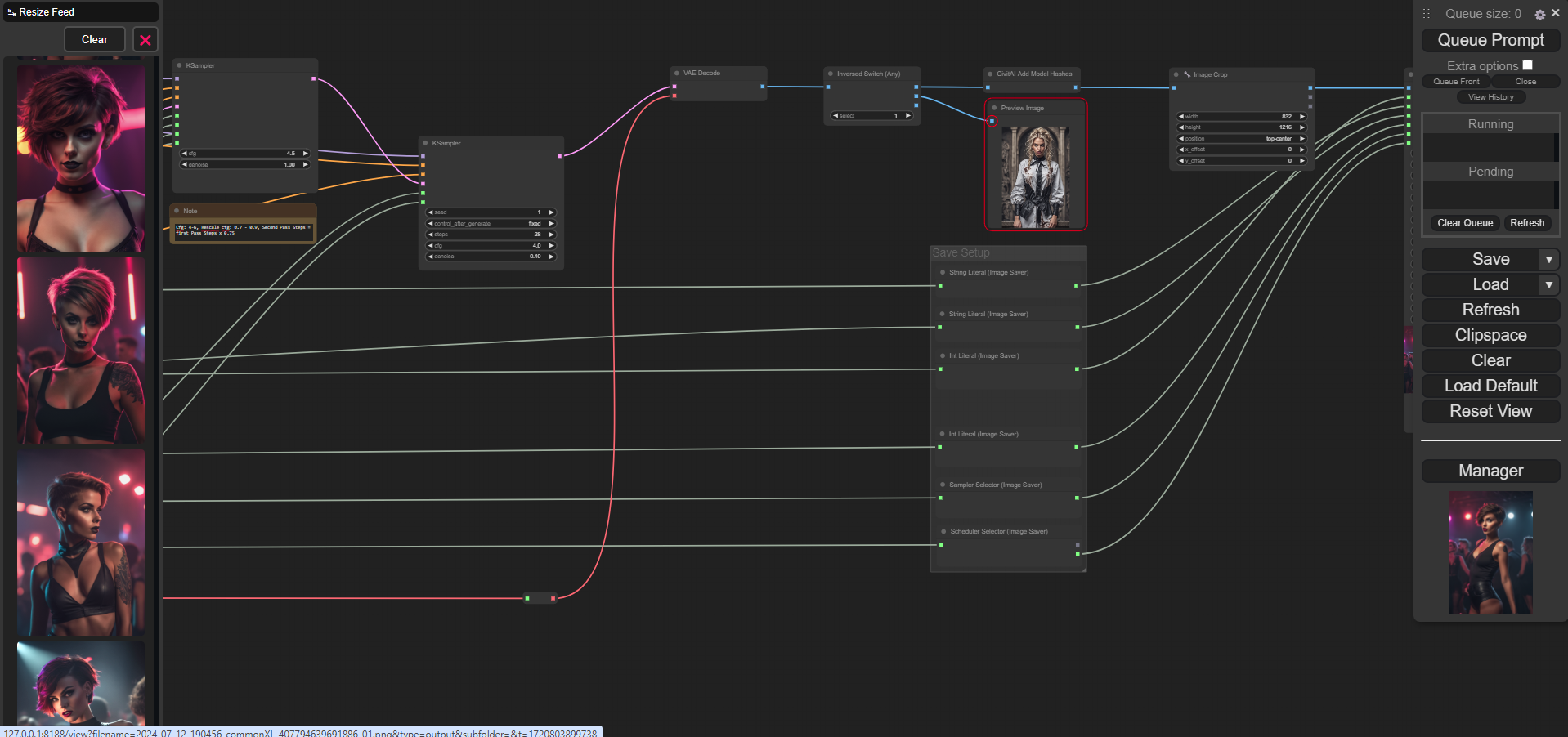
Sampler Setup for Great Flexibility
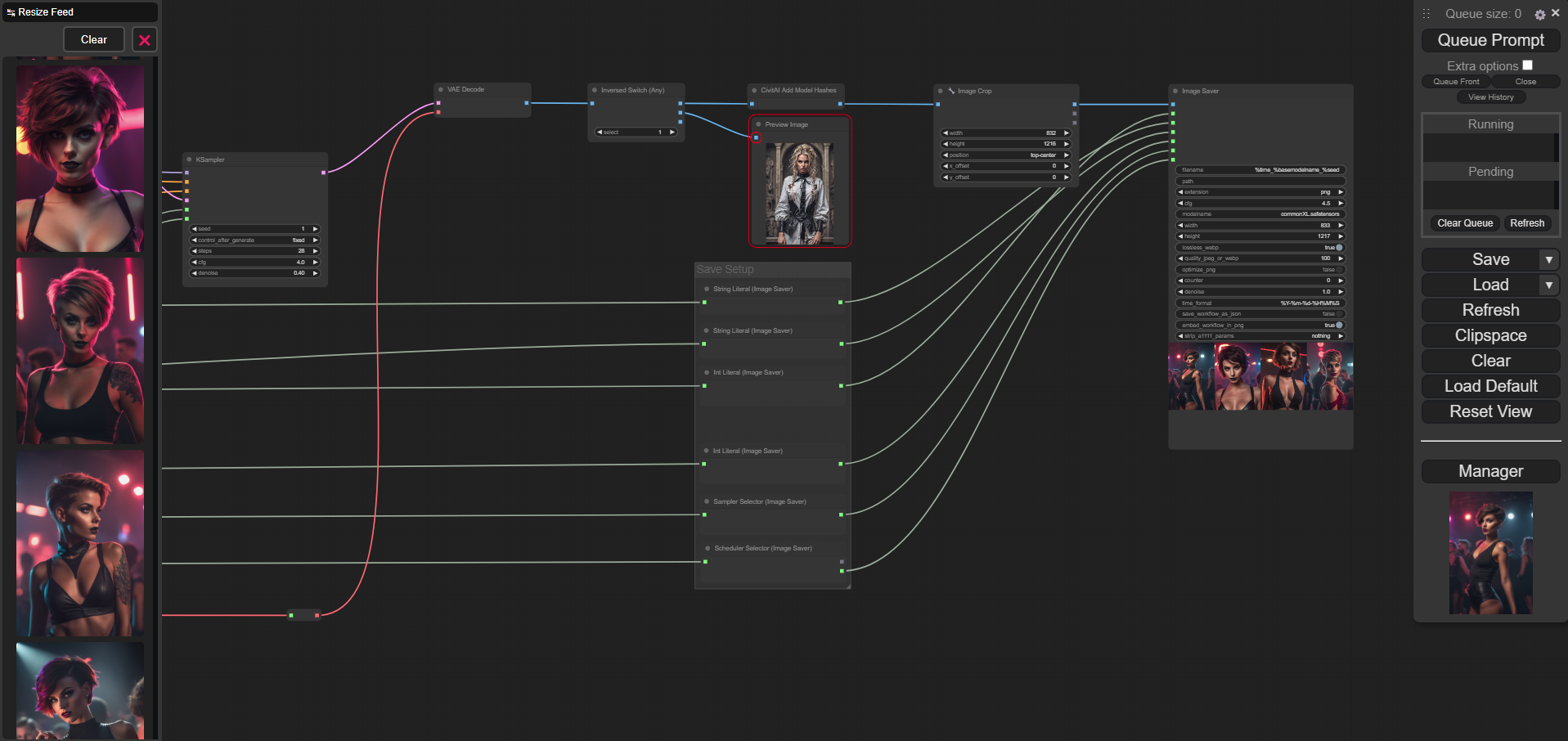
Output Optimization for CivitAi
There is not much to consider when it comes to prompts in the first point. Text-L roughly describes the composition. Text-G is a comma-separated list of short phrases and strong adjectives that describe the style. Negatives are words that you don't want in the outcome.
Points 2 and 3 intertwine. The prerequisite for meta-information being automatically recognized in Civitai when uploading images is the outsourcing of sampler settings. When using CLIPTextEncodeSDXL, I use the width & height values from the Empty Latent Image and multiply them by a factor of 1.25 to 2. This has an impact on the noise in my observation and can affect the quality of the generated images.
I have set an Inversed Switch before the image output with the following settings:
Save Image
Preview Image
This is practical in the prompting phase to avoid having to save every attempt. However, the Inverse Switch Any also allows for further application possibilities to be added arbitrarily - such as upscaling or inpainting.
The CivitAi Add Model Hashes Node follows the switch, which is particularly practical when uploading images to CivitAI that use Loras. The Loras used are then automatically recognized by Civitai and linked under Generation data with the pages on Civitai - a positive side effect - images are not only listed at the checkpoint but also at each Lora used.
The following custom nodes that you need for the workflow:
1. ComfyUI-Manager- https://github.com/ltdrdata/ComfyUI-Manager
2. ComfyUI Impact Pack - https://github.com/ltdrdata/ComfyUI-Impact-Pack
3. pythongosssss/ComfyUI-Custom-Scripts - https://github.com/pythongosssss/ComfyUI-Custom-Scripts
4. rgthree's ComfyUI Nodes - https://github.com/rgthree/rgthree-comfy
5. rk-comfy-nodes - https://github.com/rklaffehn/rk-comfy-nodes
6. ComfyUI Essentials - https://github.com/cubiq/ComfyUI_essentials
7. ComfyUI-Image-Saver - https://github.com/alexopus/ComfyUI-Image-Saver
If you have already installed the ComfyUI manager, load the workflow, click on the manager and then on install missing nodes.