Alt4One V1




















详情
下载文件 (1)
模型描述
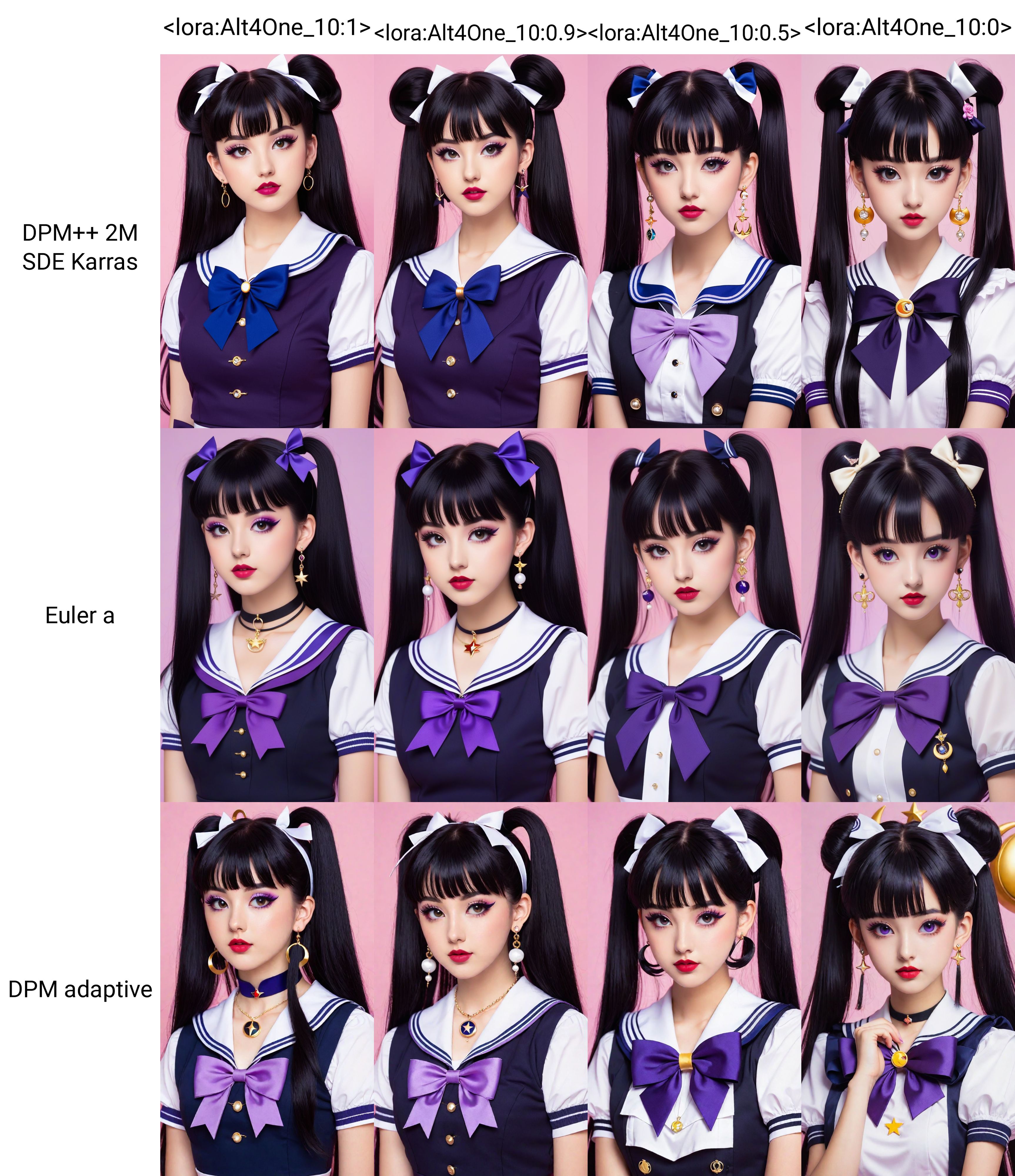
Alt4One
This model was trained on SDXL with 460 images, I'd like to train it on 1000 or more on the next version.
This LoRA's aim is to produce more alternative style, woman, clothing, poses and more. The caption was done using DeepBooru, so it should work well with that style of prompting.