crying_with_tears_flux










詳細
ファイルをダウンロード
モデル説明
V2.0
特別な感謝:
データセットはダウンロード可能です(26枚の画像)。ワークフローはV1.0と似ていますが、アニメスタイルの訓練データセットを得るために生成モデルを変更しました。追加のプロンプトを使用することで、ポーズ(見上げ/見下ろし、笑顔など)を調整できます。
あることに気づきました:現実的な訓練データを使用した場合、LoRAは現実的な写真を生成できますが、アニメスタイルの画像を生成するのは難しいです(「anime」というプロンプトを追加しても)。一方で、アニメの訓練データを使用すると効果的です。アニメスタイルを避けるには、生成時に「photorealistic」というプロンプトを追加できます。
(訓練データに「アニメスタイル」というタグを追加しましたが、これが影響している可能性がありますか?)
{
"engine": "kohya",
"unetLR": 1,
"clipSkip": 1,
"loraType": "lora",
"keepTokens": 0,
"networkDim": 2,
"numRepeats": 6,
"resolution": 512,
"lrScheduler": "cosine",
"minSnrGamma": 5,
"noiseOffset": 0.1,
"targetSteps": 1040,
"enableBucket": true,
"networkAlpha": 12,
"optimizerType": "Prodigy",
"textEncoderLR": 0,
"maxTrainEpochs": 20,
"shuffleCaption": false,
"trainBatchSize": 3,
"flipAugmentation": false,
"lrSchedulerNumCycles": 3
}
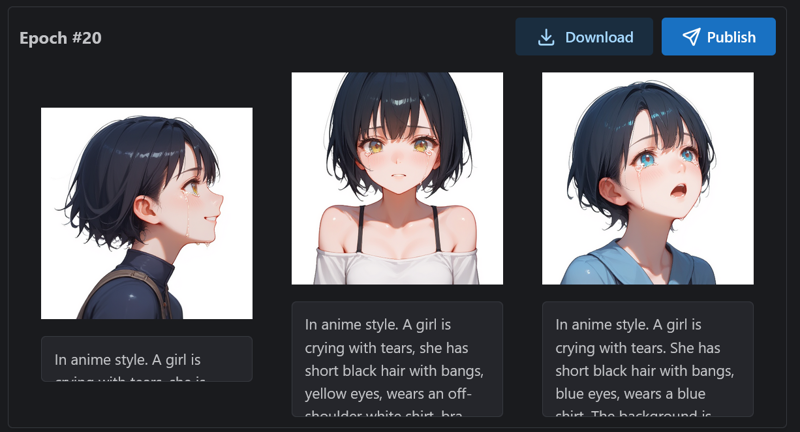
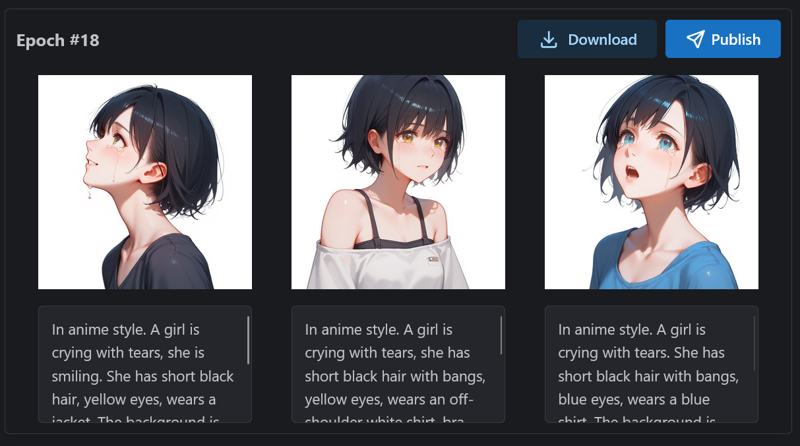 最終的に、エポック#18のモデルを公開することにしました。
最終的に、エポック#18のモデルを公開することにしました。
V1.0
特別な感謝:
データセットはダウンロード可能です(27枚の画像)。これらは上記の2つのモデルによって生成されたもの(1024×1024の後、512×512に縮小)。その後、WebUIのツールでタグ付けし、自動生成されたタグをもとに自然言語で手動で再タグ付けしました。最後に、このLoRAを使用して、追加のプロンプトでポーズ(見上げ/見下ろし、笑顔、口を閉じるなど)を調整できます。
訓練パラメータ:
{
"engine": "kohya",
"unetLR": 1,
"clipSkip": 1,
"loraType": "lora",
"keepTokens": 0,
"networkDim": 2,
"numRepeats": 6,
"resolution": 512,
"lrScheduler": "cosine",
"minSnrGamma": 5,
"noiseOffset": 0.1,
"targetSteps": 1080,
"enableBucket": true,
"networkAlpha": 12,
"optimizerType": "Prodigy",
"textEncoderLR": 0,
"maxTrainEpochs": 20,
"shuffleCaption": false,
"trainBatchSize": 3,
"flipAugmentation": false,
"lrSchedulerNumCycles": 3
}
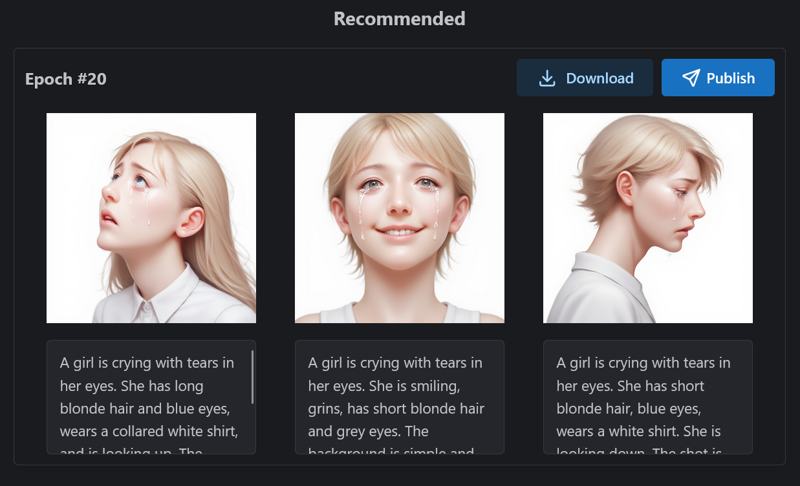
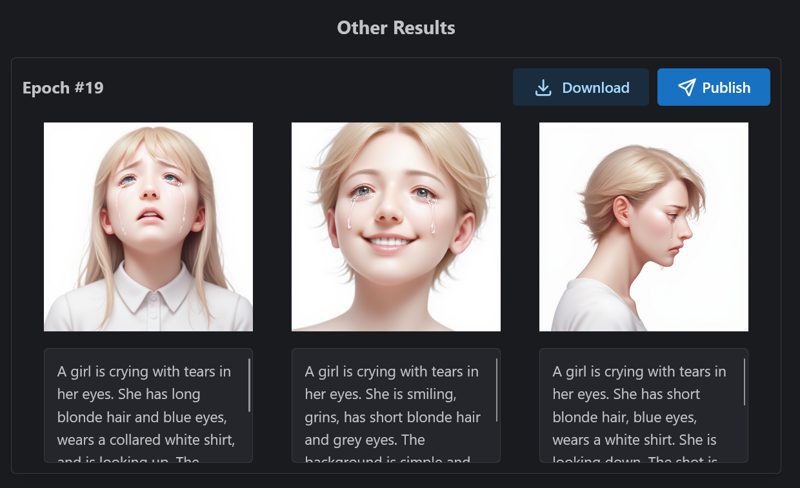 最終エポックは#19よりもわずかに優れていると感じたので、最終エポックを選択しました。
最終エポックは#19よりもわずかに優れていると感じたので、最終エポックを選択しました。
このモデルで生成された画像
画像が見つかりません。