Colossus Project Flux


Details
Download Files (1)
About this version
Model description
Deep under a mountain lives a sleeping giant, capable to eighter help humanity or create destruction...
A Colossus arise...
After my SDXL series its time for the FLUX series of this Project... This time I trained this thing from ground up. For training I used my own images. I have created them with my schnell Flux model DemonFlux/Colossus Project schnell + my SDXL Colossus Project 12 as refiner.
This SD Flux-Checkpoint is capable to produce nearly everything.. Colossus is very good creating extremly realistic pictures, anime and art.
If you like it, feel free to give me some feedback. Also if you want to support me you can do this here. I have spend some good money to build a computer that is capable to actually train Flux-models.. Also training and testing takes also a lot of time and electricity..
https://ko-fi.com/afroman4peace
Version V12 "Hephaistos"
Publishing this checkpoint makes me happy and sad at the same time.. V12 will be the last checkpoint of this series.. The main reason are the upcomming EU-AI laws... Another reason is the license from Flux .1 DEV itself. Thank you all for the support! I have sunken a lot of time into this Project over the last year. Now its time to move on to a different Project.
Anyways.. I will end this series on a high note...
V12 is build on V10B "BOB" but got basically the best parts of this series blockmerged into this one checkpoint. (It was the result of a new merge method which took about 1:30h to merge and used up my entire 128GB RAM). I also enhanced the face and skin textures in comparison to V10. The eyes are much more realistic and more "alive" than before.
Test it out yourself and give me feedback about V12. "Thanks" to my slow internet connection I will first upload the FP8_UNET. After that the FP8 "all in one" version and then the FP16_unet and FP16_BEHEMOTH. I will also try to get it converted into int4 and fp4 (wish me luck on that matter)
As always give me some feedback about V12..
Version V12 "Behemoth" (AIO)
This "all in one" model is the best of my V12 series.. well and the biggest in size of course :-)
The Behemoth is got an costom T5xxl and Clip_l baked inside the model. If you prefer quality over quantity this is the checkpoint for you!
Version V12 FP4/int4
Thanks to Muyang Li from Nunchakutech who did the quantification of V12. https://huggingface.co/nunchaku-tech and their amazing nunchaku!
This version is truly mindblowing. Combining quality with speed never seen before.
ATTENTION!
There are two versions FP4 and int4. FP4 is for Nvidia 50xx graphic cards only! While int4 works with 40xx and below. (you need at least a 20xx series graphics card)
You also can download both versions directly here: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
INSTALL GUIDE and WORKFLOW
Here is a quick install guide and WIP workflow.
https://civitai.com/articles/17313
DETAILED GUIDE for the Workflow
https://civitai.com/articles/17358
I am still working on my new workflows for Nunchaku.. so the following workflow is still very WIP (work in progress) I will add a detailed article at the weekend.
Version V12 FP16_B_variant
Thanks to a small mistake I made late at night (2AM) I renamed and uploaded the "wrong" checkpoint. Its an very experimental checkpoint never meant to be published. Its not much tested but performed really good when I have created the showcase. Its might better than the standard version.
It likes to lean more into asian faces.. That is because I wanted to test something to mix in a side project I am still working on. Tell me your experience with this checkpoint :-)
Version V12 AIO FP8
This version is a all in one version of V12. This means that all clips are baked inside it. It will give the same output as the FP8_unet with my custom clip_l
Version V12 GGUF Q5_1
This version was a request. Its not bad in quality..
Version V10B "BOB"
This is an alternative version of V10. I have created this to improve the FP8 version of V10. In general the FP8 version is more precise and the colors are better. Sadly I have not much time recently.. (RL goes first). Thats why this took so long.. Let me know if you prefer this version. I do have a FP16 version of "BOB" too. Depending on the feedback I will also consider to publish a int4 version.
WORKFLOW:
here is the workflow for V12 and V10: https://civitai.com/articles/17163
Version V10_int4_SVDQ "Nunchaku"
First I want to say thanks to theunlikely https://huggingface.co/theunlikely who converted the FP16_Unet into int4_SVDQ. Go visit his page and leave a like.
This version is more or less equal to the FP8 version. Even on the normal mode inside my workflow this thing is about 2X-3X faster than the regular model.. With the "fast mode" of the workflow I can render an 2MP image in around 19 seconds with my 3090ti.
What is SVDQ "Nunchaku"?
This new quantification method allows it to shrink Flux models (in this case a native FP16 model) from 24GB to about 6.7GB. But thats not all: you can run generations faster than ever before without loosing too much quality. Sure you will see a small difference between my 32GB_Behemoth but for this thingy you will need a lot more Vram/RAM to even run it.
For more information visit: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Installation: Please visit my workflow/install guide: https://civitai.com/articles/15610
Version V10 "Behemoth" (FP16_AIO)
This version is still experimental. The main focus was to get more realistic results. Also I managed to reduce some "Flux Lines". This thing is based on Colossus Project V5.0_Behemoth, V9.0 and another Project I call "Ouroborus Project"
The FP16 version is very stable. I am also releasing a FP8 version soon. This version is also very good but not as stable..
I let you experiment with it though.. Tell me what you think of this version.
Have frun creating :-)
Version V9.0:
Well I have to explain a lot.. First why is it even V9.0?
I recently moved in a new flat and because of some errors the internet provider did I had no real internet connection.. So while doing the whole moving stuff.. I left my computer running. The result was that I created a lot (most broken) Checkpoints. I do have some very good V8 versions though I might will publish as well..
What changed?
I trained new faces and skin textures into the model by taking basically the best results of V5.0. Also the model got an feet/legs training for better anatomy. The V5.0 versions sometimes clipped the head and feet.. I think that I managed to fix some of those isseues..
In addition I trained it with more of my own landscape images.. And yes I did that all while moving into a new flat... I think it was a overall training time of about 2 weeks computing time which isn't exactly cheap.. (every hour basically costs me around 25 cent in electricity)
Anyway I hope that you like this version.. If you want to support me: Post some nice images/ or maybe tip me even with buzz or on Kofi..
Tell me what you think of it :-)
Version 5.0:
V5.0 is actually based on V4.2 and V4.4 (which will be also released soon). It got additional training on skin details and for anatomy in general which mostly fixed stuff like hands and nipples. The face details are much better. I also tried to fix the some minor flux lines..
In general this version is more realistic than V4.2 and better with smaller details.. Like Version 4.2 this version is also a hybrid de-distilled model. You can use it basically with the same settings like V4.2.
Here is also a new Workflow to play with: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Tell me what you think of this version compared to 4.2 or V2.1..
Version 4.4 "Research":
I have added this version just for completion.. Its slightly more realistic than V4.2 and the base of Version 5.0. You can try it if you want. You can also use the workflow for V5.0 and V4.2..
Version 4.2:
This version is basically a further development of Demoncore Flux and Colossus Project Flux. The goal was to get a more stable outcome with and better skin textures, better hands and more variety of faces. So I have trained it on a hybrid model which is partly Demoncore Flux. I also enhanced the nipples and NSFW a bit. Tell me if you prefer V4.2 over version 2.1 :-)
For the showcase images: I have only used native images with SDXL resolution or 2MP resolution (for example 1216x1632). This model can handle even higher resolutions.. I have tested this checkpoint for up to 2500x2500 but I only recommend going for around 2000x2000.
For the settings I recommend using about 30 steps and 2-2.5cfg. I mostly use 2.2 or 2,3 in my workfow. For the showscase I have used DPM++ 2M with Simple sheduler.
I will add more versions soon but I don't have much time before Christmas..
Settings
I will add a more new dedicated Comfy workflow soon. You can always download and open the showcase images for now..
The "All in One version also works well with Forge too..
Basically it works with the same settings as Version 2.1 (see below)
Give it 20-30 steps with around 2.2cfg..
Version 2.1_de-distilled_experimental (MERGE)
This version is completely different and works actually different than a normal Flux model!
Its a experimental merge between my version 2.0 and a de-distilled version https://huggingface.co/nyanko7/flux-dev-de-distill. This happend a bit by accident but the results are mindblowing. You will get mindblowing details. Also follows the prompts extremely well... So the next thing I am gonna do is to train on the de-distilled model directly. I have already done some test Loras with it. This is highly experimental so please let me know if you find errors which are not listed down below. If you have good images post them.. post also the bad ones this can help improve thing :-). May try also version 2.0 and tell me which type of checkpoint fits you best.
!Attention!
The normal Flux workflow isn't working with this version. YOU NEED to download my workflow for it!
You also can figure something yourself out but please don't blame me for bad images. Also this is a highly experimental model... check the downsides below..
UP- and Downsides of this checkpoint:
Well this checkpoint can create extrem details..This will come with a price.. Its slow compared to the normal Flux- checkpoints. The upside of it is that you often doesn't need a additional upscale anymore. Instead of using the Flux Guidance this model uses the cfg scale. Which also mean that it will not work with standart workflows.
You can use negative Prompts! This helps to get stuff out of the image you don't want.
Sometimes can artifact appear.. You can solve this by a small and simple upscale (I am working on this). Here is an example.. this strangly happens not with every seed.. UPDATE: This is not a issue with the model itself.. more a workflow one.. I am working on fix for it. If this happens you can try setting the first upscale to 1.14 instead of 1.2.

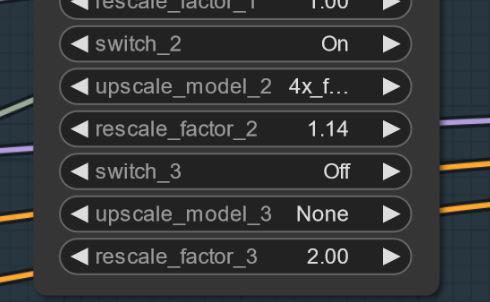
Settings and Workflow V2.1:
Here you can find the workflow for it: https://civitai.com/articles/8419
Settings: other then the normal Flux it doesn't need the Flux Guidance scale. Use the cfg instead. I mostly use 3 cfg for the workflow.. Some images may require lower cfg-scales
the most important thing is may to shut off the flux guidance scale..
Without the Workflow I have tested it with 30 steps and 2-3cfg. This is also may the settings for Forge. try to experiment here.
I recommend using the word "blurry" in the negatives
Sampler and scheduler:
You can pick from a range of working samplers:
Euler,Heun, DPM++2m, deis, DDIM ware working great.
I mostly used "simple" as scheduler
If you find better settings tell me.. :-)
For Forge I recommend using the AIO model.. here is a example setting for Forge
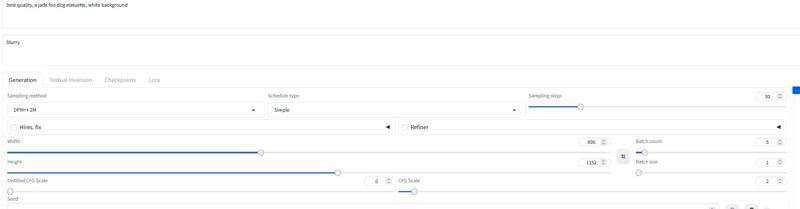
Version 2.0_dev_experimental
Well.. this a experimental version.. The goal was to create a more coherent and faster model. I have trained in some additional own trained loras and then merged the resulting models in a special way (Tensor merge). It got a costom T5xxl which I have modified with "Attention Seeker". For gaining speed and additional quality I have merged in the Hyper Flux lora from ByteDance. This means that it shifted the working area.. I show you what this means.. Here is the main title image..
16 steps V 2.0
 30 steps V 1.0
30 steps V 1.0
 Downsides:
Downsides:
Well first.. This version is a bit bigger than the last one.. second I still have to create the Unet only version. I will update this when its done..
Settings and Workflow V2.0:
You can run the model now with less steps.. 16 steps equals 30 steps from the old model.
I still recommend using around 20- 30 steps because it will get you more quality in most cases.
Sampler: I prever Euler with Simple as scheduler. The guidance can be set from 1.5-3 (feel free to test it outside this range of course). The guidance of 1.8 still works well for realistic images. You can also test out other samplers. DPM++2M and Heun also working great.
Workflow 2.0:
I have created a new workflow for V2.0 and V1.0. This got the new Flux Prompt Generator. Additionally I got the second upscaler stage working. https://civitai.com/articles/7946
Forge:
I have tested this model also with Forge and it worked very well.. The images may can differ between Comfy UI and Forge though..
Version 1.0_dev_beta:
This model is my first entry of the series. So please give me some feedback and post some images. This helps me to improve this project further. There are several versions to choose from. The best model regarding quality is the FP16 version Well the FP16 version is huge in size and will need a beefy graphics card and lots of RAM. The FP8 version is the version I consider as good solution between quality and performence. If you want to get a GGUF version download the Q8_0. The GGUF Q4_0/4.1 version was a request. They small in size but you will loose some quality.
There are basically two types of my models "All in one" models which only needs one file to download. It got the Clip_l, T5xxl fp8 and the VAE baked in. (look down below). Place this inside your checkpoints folder.
The other versions are the UNET-ONLY ones. Here you need to load all files seperately.
In any case you need to download my Clip_L for those to get them working right..
Also important is to choose the right T5xxl clip. For the FP8 version it is the fp8_e4m3fn t5xxl clip. For the FP16 it is the FP16 clip. make sure to select the default weight type. (down below is a example image for the fp8 version)
For the GGUF version you need the GGUF loader!
Some known things for now regarding V1.0:
This is just the first model of the series so at the moment it might can struggle with some prompts or styles like art. The next version will receive more training. Let me know some things the model can't do..
Settings and Workflow:
I have tested it with around 30 steps, Euler with Simple as scheduler. The guidance can be set from 1.5-3 (feel free to test it outside this range of course)
The guidance of 1.8 works well for realistic images.
Feel free to experiment with those settings.. If you get good results, please post them.
I have added the showcase images as training data.. Inside it is the workflow for Comfy. Here is the workflow for download: https://civitai.com/articles/7946
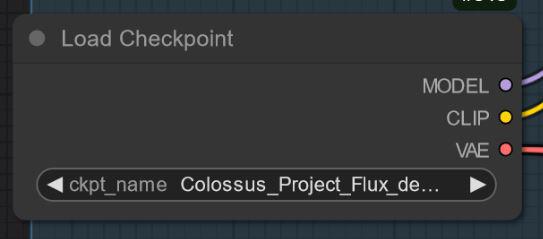
"All in one" model:
UNET_only:
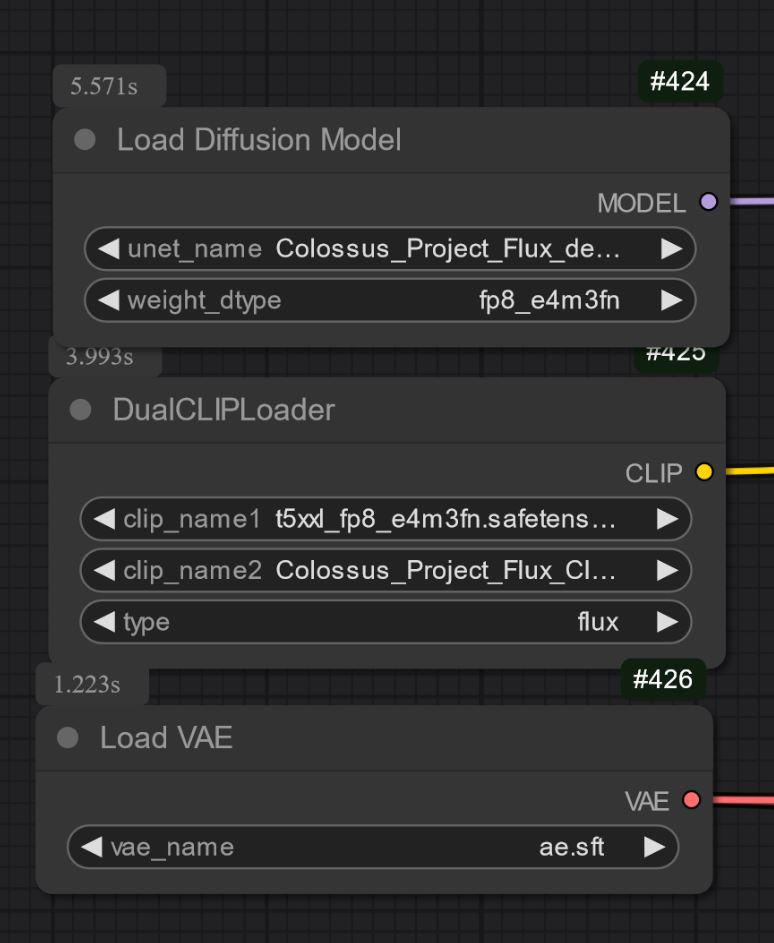 You need download the clip_L as well. its the 240MB file.
You need download the clip_L as well. its the 240MB file.