ID Sign - Flux
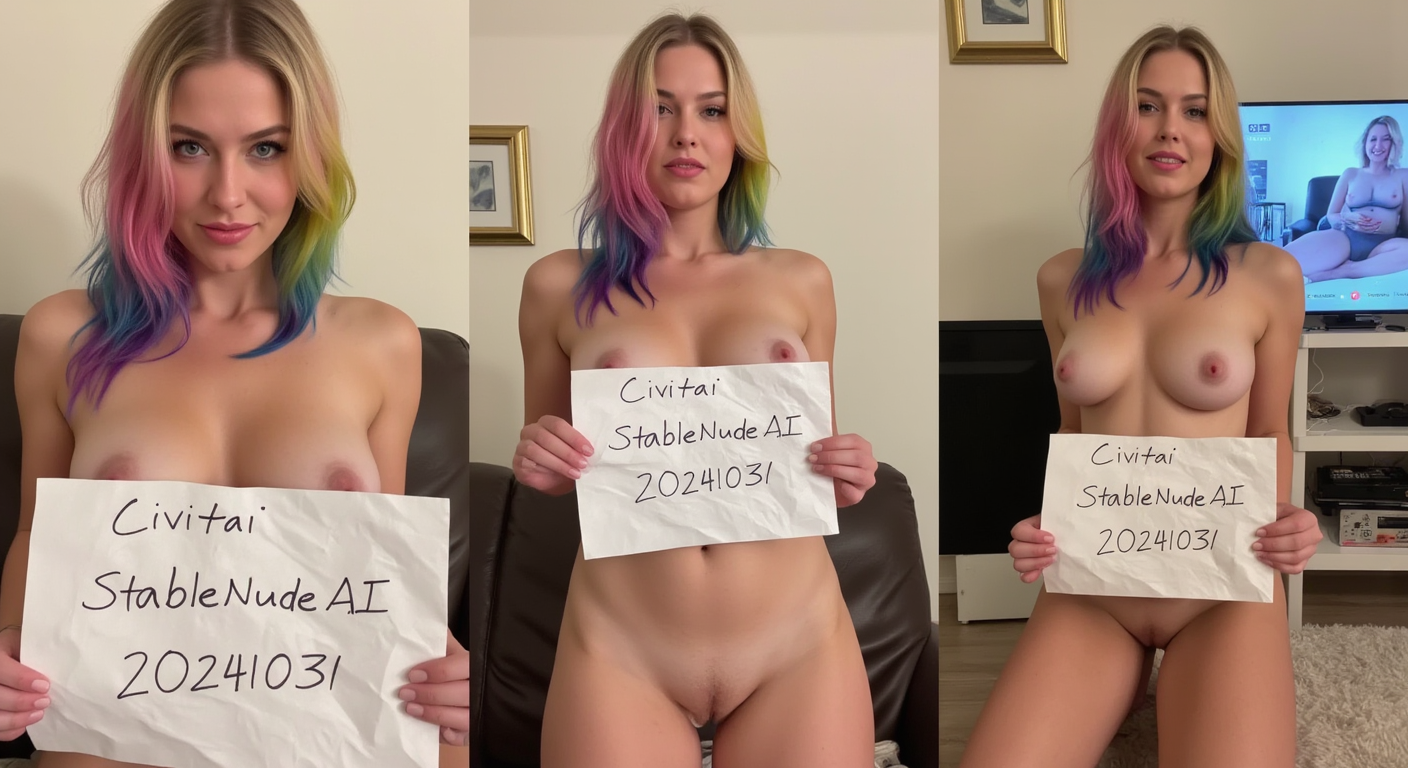









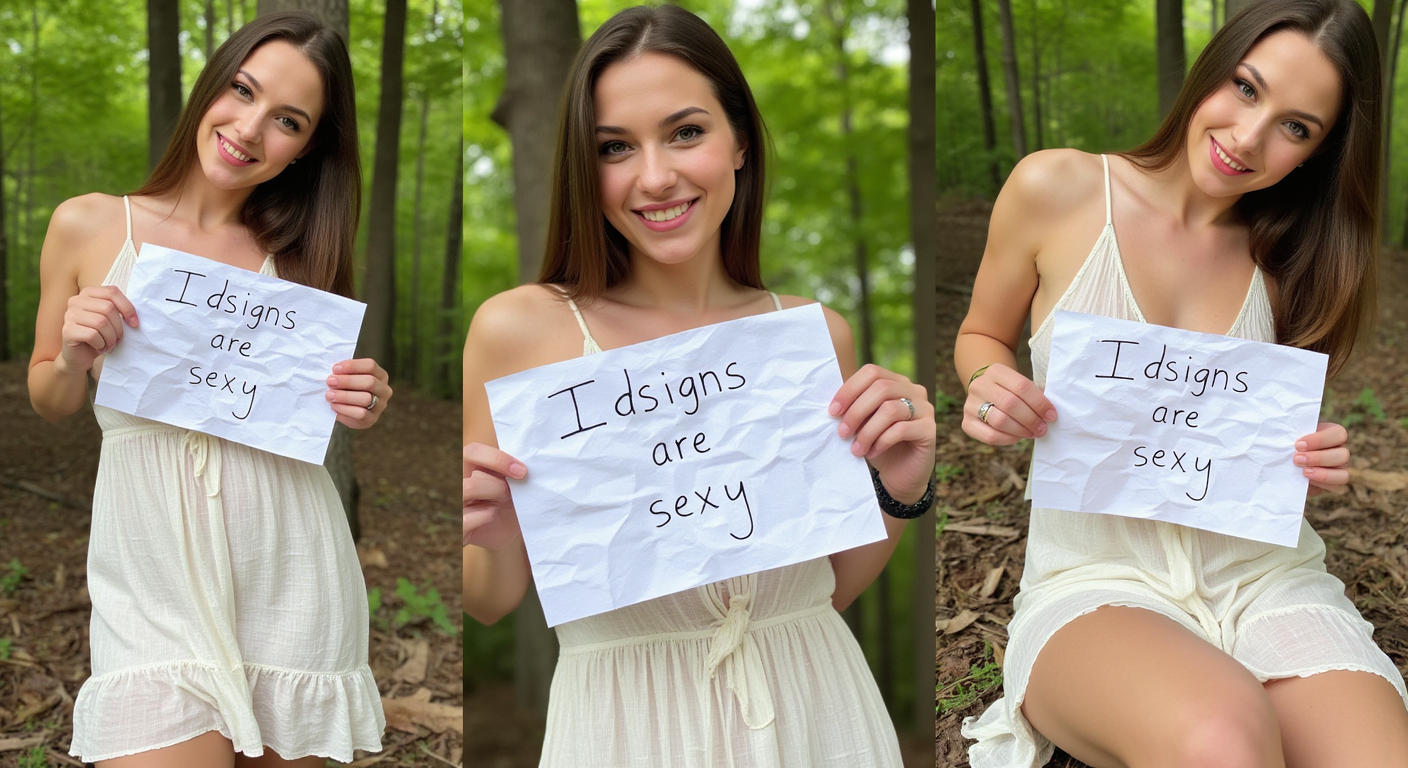






Details
Download Files (1)
Model description
This is not the first attempt at modeling the ID Sign concept, initial attempts where on SDXL. No attempts were able to reproduced the concept adequately. The concept for SDXL was only a single image not a full panel. After seeing OnOff and how well it combined with other LORAs, another attempt was warranted. The prompting text is similar to OnOff. As it worked well, this attempt mimicked it.
An id sign or verification sign at the strictest level requires a piece of crumpled piece of paper with specific information on it. Further, the sign is required to be displayed in multiple images, to ensure that images have not been edited or modified. Generating three views simultaneously enabled consistency between the images. Specifically, focus was given to the consistency of the sign text and the crinkles on the paper.
This model is a LORA for flux1-dev and was trained on the flux1-dev checkpoint. The model was trained with 33 images found online. The images were rescaled to a standardized height and then merged in sets of three to form 11 images for training.
The captions for training were of the form,
"A woman holding a crinkled white paper sign from three views, left photo [SCENE] , center photo [SCENE] , right photo [SCENE]"
Where SCENE was a sparse description of the photo.
Example SCENE's: "standing naked","kneeling in panties from side", "reclining naked","naked from side"
Recommended Settings
The model works well with a,
1 strength
3-3.5 Distilled CFG
30 steps
Euler Simple
fluxunchainedArtfulNSFW checkpoint
resolution 1408x768
Prompting
Following this prompt format gave good results.
"A woman holding a crinkled white paper sign from three views, The sign says ("TEXT":1.3), Describe the commonalities for all photos, left photo SCENE_1, center photo SCENE_2 , right photo SCENE_3 <lora:idsign_flux_v1:1>"
The whole scene can be prompted with the common factors of the image. These prompts work with full sentences e.g. "a brunette woman in a bedroom","at the beach","a woman wearing a dress with large breasts"
The individual scenes can be prompted too. Brief prompts had better sign consistency. e.g. "lying on a bed","Sitting on a chair", "Standing outside"
Other prompting may work.
Strengths
creates id signs with the correct text
creates id signs with consistent text and crinkles
allows prompting of each photo
works with a variety of subjects
can create more than 3 views (not part of training data, credit to flux)
Weaknesses
photo consistency only happens 2-10% of the time (very prompt dependent)
signs held at non-simple perspectives do not work
the photos are not perfectly consistent
Version 2
A smaller LORA size was attempted, it did not work as well. The model would benefit from a more diverse set of training images. Another version may be created.