Joe's Adaptive Guidance GGUF FLUX.1-schnell Workflow












詳細
ファイルをダウンロード
モデル説明
イントロ
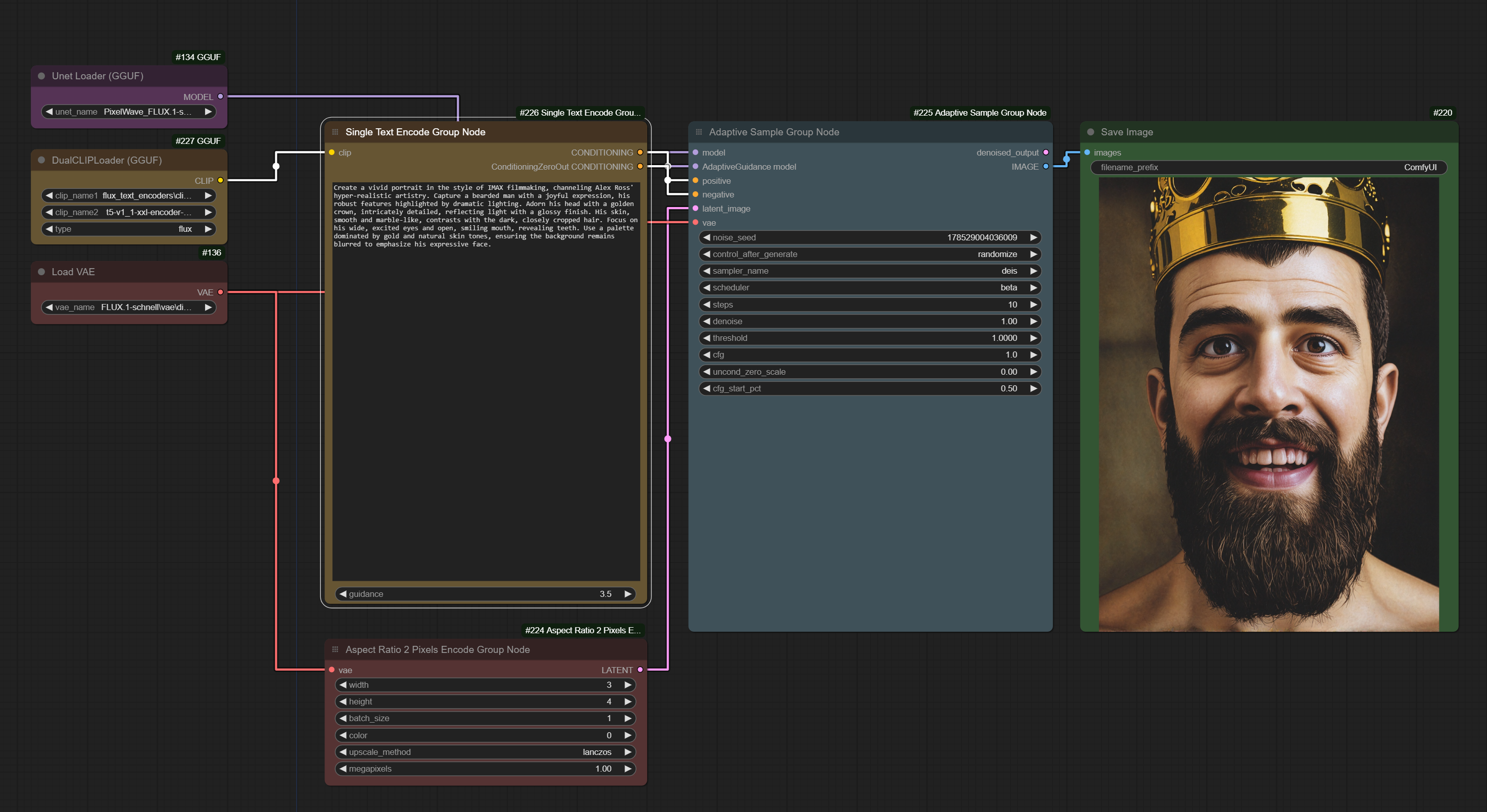
アダプティブガイダンスカスタムノードを発見した後、これはサンプリングガイダンスを新規の方法で調整するだけのシンプルなカスタムノードですが、これによりデディスティルモデルが可能になると同時に、ディスティルされたハイパーモデルやSchnellでも興味深い結果が得られるようになりました。私はまだApacheライセンスのSchnellを大変気に入っています。そこで、私が作成したかったのは、GGUF UNetおよびGGUFテキストエンコーダーも使用する、非常にシンプルなワークフローを共有することです。
これまで私がテストしてきた他のワークフローは、主に他の人の学習支援を目的としていましたが、これは私が実際に人々が画像を簡単に作成し、ComfyUIに慣れることを期待して共有する最初のワークフローです。私はすでにForgeとWebUIを完全に離脱しています。
コメントをお願いします。
このワークフローは、Windows 2022およびWindows 11上で4060Ti、4080 Super、4090でテスト済みです。
LoRA
LoRAと共にこのワークフローをテストしましたが、LoRAを個別のノードとしてこのワークフローにドラッグして接続するか、Power LoRAローダーを使用すると最も安定して動作します。
UNetモデル Flux
UNETフォルダーにGGUFモデルが必要です(Q6より低いものは推奨しません)。
推奨モデル
Flux Fusion V2 GGUF(最良の結果)
または
GGUF形式のSchnellベースまたはマージモデル
提供されている設定はハイパーモデルとSchnellモデルで動作しますが、Devモデルやデディスティルモデルでは動作しません。このワークフローはDevモデルやデディスティルモデルに対応するよう調整可能ですが、これはこのワークフローの目的ではありません。
VAE
私は公式Schnell Hugging FaceページのVAEを使用していますが、AEのVAEでも動作します。現在、FluxではVAEモデル間の差異はほとんどありません。
GGUFテキストエンコーダー
次に、clip_lとt5のGGUFバージョンが必要です。Q6またはQ8を推奨します。
https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf
これにより、CLIPの読み込みとオフロードが高速化されます。
必要なカスタムノード:
アダプターガイダーはこちら
https://github.com/asagi4/ComfyUI-Adaptive-Guidance
GGUFがまだない場合はこちら(テキストエンコーダーとUNetのGGUF対応を可能にします)
https://github.com/city96/ComfyUI-GGUF
アスペクト比空画像
アスペクト比セレクターを使用していることに気づくでしょう。この機能が広まればとても嬉しいですが、カスタムノードなしでも、アスペクト比(例:16/9、4/3、3/5など)とベースメガピクセルを入力することで、希望する画像サイズを自動生成できます。