Simulacrum V4 <|DELTA|> [F1D/DD/F1D2/UNET/CLIP_L]



















詳細
ファイルをダウンロード (1)
モデル説明
!!! SIMV4 CLIP_L IS REQUIRED FOR FP16 UNET !!!
FP16 UNET will NOT function properly without the CLIP_L!
F1FP16 UNET 起動の為に、CLIP_Lが必要です。
F1FP16 UNET 需要夹子 l CLIP_L
CLIP_L was trained with 5 million samples.
Scheduled Release 11/15/2024: 5-6:00 pm gmt-7
Full disclosure, I think 3.8 is probably better.
Configuration SimV4:
The core system of Simulacrum V4 is based ENTIRELY on SUBJECT FIXATION.
humans, humanoids, anthros, furries, robotics, machines, cars, vending machines, and anything else you can imagine or find a lora for.
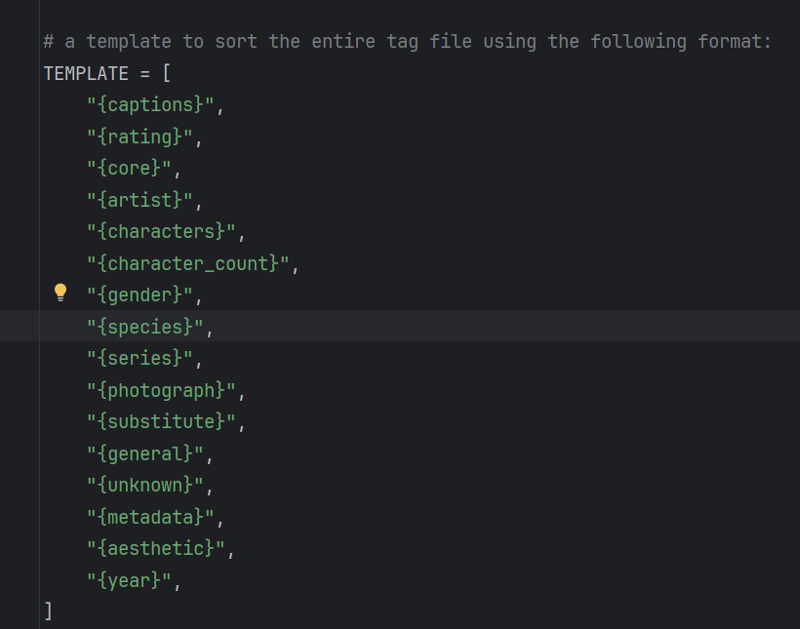
A large percentage of images were trained with this tag format:
Definitions;
Attention Offset and Depiction tags;
Introduced for V4, many tags were identified and their image position offsets were trained into the reaffirmation training for the core.
depiction tags are a bit wonky for now, but they work here and there, use at your own risk.
depicted-middle-left
depicted-middle-right
depicted-middle-center
depicted-upper-left
depicted-upper-center
depicted-upper-right
depicted-lower-left
depicted-lower-center
depicted-lower-right
full-frame > 70% of the image
half-frame > 40% < 70% of the image
quarter-frame > 25% < 40% of the overall image
depicted-middle-left full-frame 1girl
a full image depicting 1girl with her face on the center left, the system implies a bunch of details around it.
depicted-upper-center half-frame face
a face on the upper center, uncertain of the rest.
depicted-lower-right quarter-frame shoes
a pair of shows taking up about a quarter of the image in the lower right corner.
Captions
Everything caption related goes first. System is trained with 255 tokens, and the captions are all less than 80 tokens, each image captioned with two complete captions for training the CLIP_L.
Rating Tags
safe, questionable, explicit, nsfw, sex
Core Tags
"b@s3_s1mul@cr7m", "anime", "3d", "3d model", '3d (artwork)', "blender (medium)", "source filmmaker (medium)", "sfm", "source film maker (medium)", "source filmmaker", "realistic", "real", "photo", "photorealistic", "illustration", "drawing", "painting", "digital", "traditional", "sketch", "render", "rendered", "model", "greyscale", "monochrome", "black and white", "color", "colour",Characters
the name of characters, they often don't exist, but they can.
Character Count
Fairly reliable, sometimes doesn't count correctly on lower steps.
1girl, 1boy, 2girls, 2boys, a woman, two women, etc etc
Fill in with your desired outcome.
Gender
gender solidifiers like female, male, male and female, male/female, female/male, etc.
Species
Your human/animal etc species. Most of the scenes default to human if not specified otherwise.
Series
Styles your image with series/copyright tags, oftentimes completely overloads an image for now. Series/copyright tags are training for v5.
Scene photograph type
"photo","photorealistic","photography","photo-realistic","photo-realism","close-up","portrait","cowboy shot","dutch angle","three-quarter view","profile","headshot","full body","fullbody","half body","halfbody","close up","above view","below view","front view","rear view","side view","back view","overhead view","aerial view","aerial shot","aerial perspective","aerial photography","aerial photograph","aerial image","side shot","side perspective","front shot","front perspective","rear shot","rear perspective","back shot","back perspective",Substitute
Anything the core system deems as important above other things so the system doesn't omit the tags due to the tag file having more tokens than 255.
Includes poses, size groupings, body parts, environmental interactions, and so on.
couple, arms, legs, lying on side, hugging, kissing
midsection, navel, muscular abdomen, cleft of venus
Aesthetic and Quality Tags
very aesthetic, aesthetic, displeasing, very displeasing, disgusting
highres, absurdres, lowres
Year Tags
"1970s", "1980s", "1985s", "1990s", "1995s", "2000s", "2005s", "2010s", "2015s", "2020s", "2025s", "1980","1981", "1982", "1983", "1984", "1985", "1986", "1987", "1988","1989", "1990", "1991", "1992", "1993", "1994", "1995", "1996","1997", "1998", "1999", "2000", "2001", "2002", "2003", "2004","2005", "2006", "2007", "2008", "2009", "2010", "2011", "2012","2013", "2014", "2015", "2016", "2017", "2018", "2019", "2020","2021", "2022", "2023", "2024", "2025",REMOVED TAGS -Completely omitted from later trainings"tagme","bad pixiv id","bad source","bad id","bad tag","bad translation","untranslated*","translation*","larger resolution available","source request","*commentary*","video","animated","animated gif","animated webm","protected link","paid reward available","audible music","sound","60+fps","artist request","collaboration request","original","girl on top","boy on top","character request","original","original character"
Use STEPS with aesthetic tags;
10 STEPS
disgusting
generates the base simulacrum NovelAI V3 synthetic pose image set, often bad hands, bad eyes, bad anatomy.
great for super simple outlines and rapid pose testing.
very displeasing
for simplistic anime/cartoons/comics
adds a bit of detail, don't expect much with 10 steps
displeasing
produces some okay stuff, not bad for cartoons and simplistic anime
aesthetic/very aesthetic
don't, it's not enough steps
20 STEPS
disgusting
should produce and match novelai character bodies with the correct colorations and nearly correct anatomy
displeasing/very displeasing
will produce a surprising amount of comics, outlines, cartoons, and so on. Not a bad option
aesthetic
simple cartoon/anime individuals with white backgrounds
very aesthetic
produces low quality realism with bad anatomy, sometimes good stuff
30 STEPS
disgusting
produces fair quality novelai anime silhouettes for the system to fill in with more details when paired with the other aesthetic tags, doesn't work well on lower steps.
aesthetic
cartoon/anime/semi-realistic individuals with backgrounds
very aesthetic
produces okay anatomy but it's hit or miss when it comes to hands, feet, eyes, face, and coloration.
40 STEPS
aesthetic
sticks closer to anime, but still produces semi-realism.
very aesthetic
produces fair quality cartoon/anime/semi-realistic/photorealistic individuals with blurry backgrounds, mostly converts them to semi-realistic.
>= 50 STEPS
disgusting - anime
produces defined NovelAI v3 bodies, hit or miss, very similar to 10 steps.
displeasing
aesthetic
aesthetic, very aesthetic - realistic/photorealistic, realistic background
produces the best images the system can until you up the steps. I haven't tested beyond 50 steps.
Will produce a high gradient of styles, from 3d, anime, blender, sfm, and a large multitude of weaker artist influences.
USE resolutions;
1218x832, 1338x768
landscape, architecture, multiple characters, horizontal comics
832x1338, 832x1216, 768x1024, 832x1024 ...
portrait, tall images, vertical comics
1216x1216, 1024x1024, 832x832, 768x768, 512x512
1:1 ratio
mixed bag
BUILD your character from top of the image, to the bottom of the image, treat the screen like a 3x3 grid.
The Burndown
Key differences between V38 and V4:
Trained with 5000 HAGRID hand pose images for hand strengthening and reinforcement.
about 80,000 samples
Refined with 1000 of the best quality images I could find to differentiate the three core styles.
about 50,000 samples total
Reinforcement training based on the core images and dataset.
about 80,000 samples
Reinforcement coloration and body pose training.
about 50,000 samples
A finetuned and specific CLIP_L smarter at identifying anime, 3d, and human interactions; considerably more capable of identifying many more complex scenes and situations than before.
5,000,000 samples
Thank cheesechaser and wildcard. I have no idea what I taught it.
It was mostly Danbooru, Gelbooru, R34.
The definitive and powerful semi-stable model progression from Simulacrum V32. Trained with nearly 2 million samples overall from it's induction to this point, paired with it's new custom raidboss-grade 5 million sample fed CLIP_L, entirely devoted to the simulacrum core, subject fixation, pose, and relative positioning on the screen.
Each lora was trained at BF16 before merging in an additive and orderly way, concatenated and merged into the core model using COMFYUI including this fully integrated burn merged lora, with carefully selected core blocks of each lora merged together in a hand picked methodology. I made multiple custom nodes and remade the checkpoint save system to specifically integrate FP scaling.
Version 4 inherits more of base flux due to the added flexibility of the CLIP_L, while attaching even more behavior to the core system than ever before. High fidelity differentiation between cartoon, animation, 3d, and realistic.
The CLIP_L has replaced a great deal of the added benefit from FLUX DeDistilled, providing a divergent and comparable standard F1D core to DeDistilled.
Works with every lora I've tried. Enhances the tagging to produce more consistent outcomes than every other version of Consistency or Simulacrum; all at a higher fidelity in all variations, a higher context awareness, a higher training degree, a higher token count, and a higher validation system.
This is the combination of a series of slow cooked, heavily tested, high image count loras combined together into the fourth edition model, dedicated heavily to individual and singular character.
Multiple characters and character interactions are weaker in this version, producing a much more solid individual character within complex scenes, and more consistent base model to enhance upon.
The initial lora trainings on this version show, the training can be a much higher learn rate while retaining stability (UNET LR 0.0009, CLIP_L TE 0.000001), in a much much shorter period of time, with less samples and less repeats (300 samples). This is the EXACT goal of this model in the end, is to produce any character the individual wants with little to no training, treating this UNET and CLP_L as a base model for rapid training.
The preliminary testing is showing, the possibility of not needing the Simulacrum V4 model to generate images from the loras, meaning you may be able to train 30 image LORAS in a matter of 5 minutes or less on a 3080 that work on base flux, just because you trained them using the Simv4 F1D2pro unet and clip_l.