The Garbage-Bin | Chaos Enhancer + Concepts LyCORIS




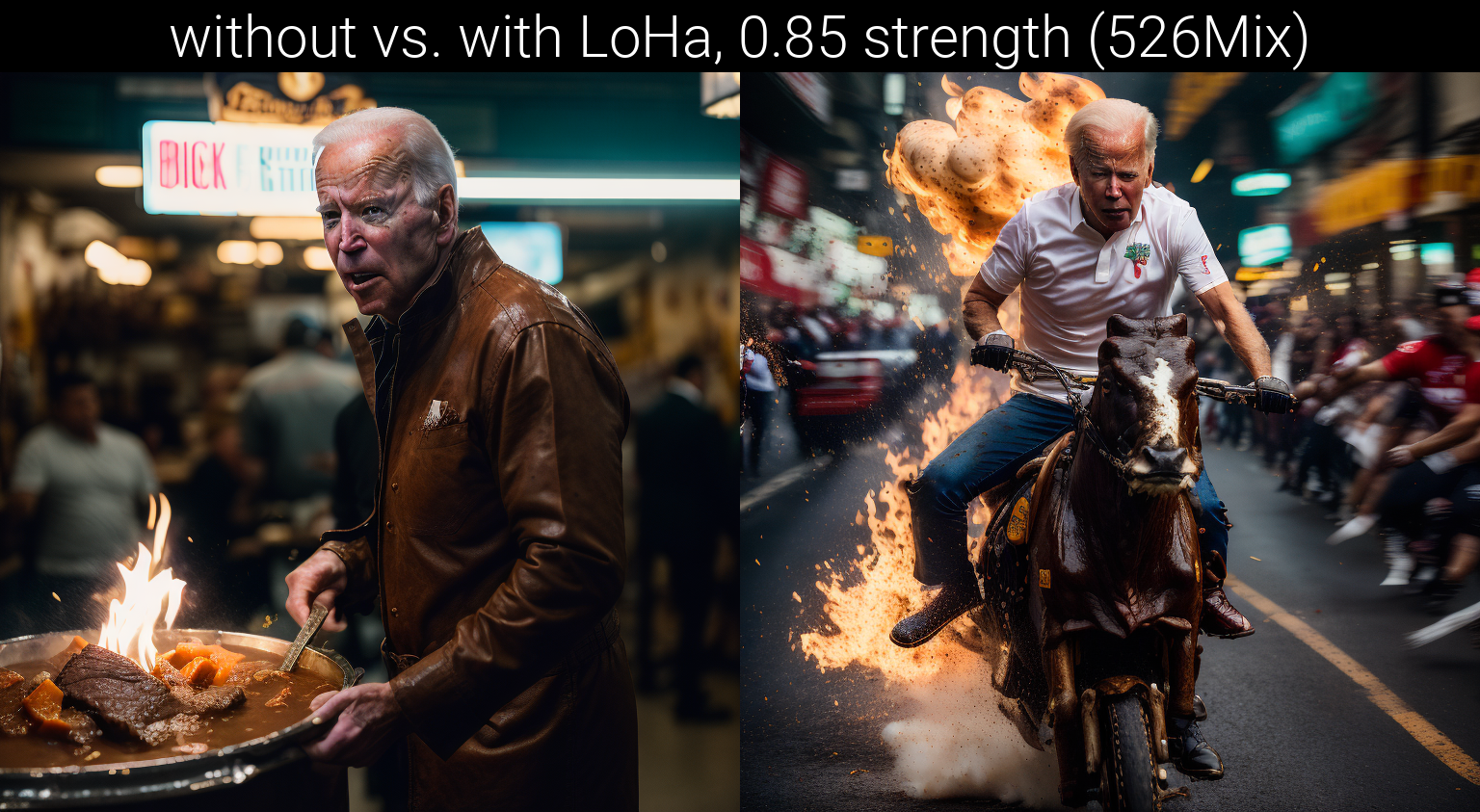

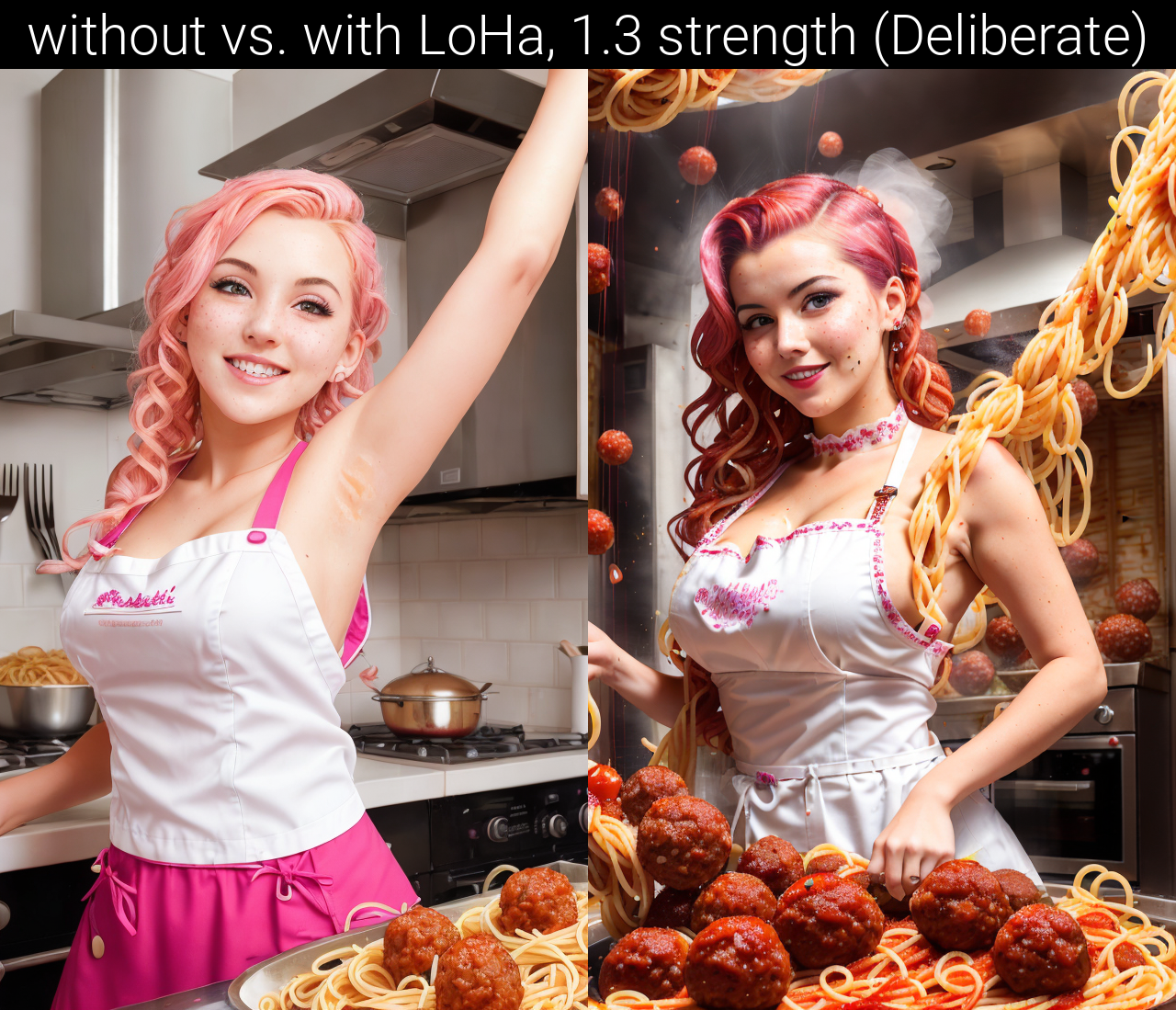









세부 정보
파일 다운로드 (1)
모델 설명
That's a nice waifu you got there. Would be a shame if someone dipped her in Papa John's garlic butter sauce.
*Example image prompts converted from InvokeAI syntax to prevent confusion. May not be entirely exact, FYI. I just use Invoke.
Welcome to the garbage-bin, a LoHa LyCORIS (for which you need an extension on Automatic1111) trained on a dataset of 441 utterly unhinged images to aid in the creation of chaos and sloppy spaghetti nightmares. Can be cranked up to fairly high strengths (1.5 for some models) pretty safely if need be. Trained on 526Mix using mostly 526Mix txt2img gens, so you'll want to keep strength lower on that mix, and up for models of a different lineage.
The LoHa comes in two flavors:
A slightly stronger and more creative version trained to pick up on a touch more stylistic elements and sub-concepts, though may clash with certain models and styles more.
A slightly weaker and less version whose training is better isolated to just the concepts. Safer, though may take more tweaking.
Usage and Concepts
Passive
When used passively, this LoHa can help elevate the chaos and creativity brought out by chaotic prompts.
You still have to have some chaos to start with to benefit, though. If your prompt and model gives you a picture that's a chaos level of 2 out of 100, multiplying the chaos by 2x still leaves you at the bottom of the scale. Are you picking up what I'm putting down? Okay, cool.
Note that the effects will vary drastically from model-to-model, and prompt-to-prompt. I can't guarantee your satisfaction. That's up for you to find.
Some models will just always struggle compared to others, especially if your model is heavily fitted to a particular subject or subject matter. Even ones that are more basic, like MeinaMix or Western Animation might not get the same insanity as a model like MothMix and 526Mix, and instead just get a bit of tuning.
Concepts
This LoHa has a few special trained concepts. At the moment, these are:
Spaghetti. Improves the quantity and quality of spaghetti when given the necessary weight.
Sloppy. Imagine carrying a deep dish lasagna with extra sauce, and you trip and fall. In your falling panic, you punched the lasagna mid-air into the ceiling fan.
Sopping. moist
Nightmare. Needs improvement. Does something. Not sure what.
Yes, those are the trigger words.
Training
This LoHa was trained on a dataset of 441 images using prompts and images directly from the fine scholarly minds of the garbage-bin channel in the InvokeAI Discord server. At least 90% of the dataset was generated using 526Mix-V1.4.5, and the vast majority of those images were photographic style using the <neg-sketch-2> negative embedding to boost realism.
Training posed a challenge. Training on base Stable Diffusion 1.5, or even 1.5 mixes like DreamShaper picked up too much of the detail level and lighting effects, despite my best efforts. In order to isolate the concepts from the detail level and style, training for the concept-only version was done directly off 526Mix. To create the slightly stronger version, 526Mix was diluted with base Stable Diffusion 1.5 by 25%, and the training repeated.
Training was performed via the kohya_ss GUI implementation, using DAdaptAdam on a 0.75 weight decay. The following are the relevant parameters in the training command used to train the LoHas:
accelerate launch --num_cpu_threads_per_process=2 "train_network.py" --enable_bucket --network_alpha="16" --save_model_as=safetensors --network_module=lycoris.kohya --network_args "conv_dim=1" "conv_alpha=1" "use_cp=False" "algo=loha" --network_dropout="0" --text_encoder_lr=1.0 --unet_lr=1.0 --network_dim=32 --lr_scheduler_num_cycles="4" --scale_weight_norms="1" --learning_rate="1.0" --lr_scheduler="cosine" --lr_warmup_steps="260" --train_batch_size="1" --max_train_steps="2604" --save_every_n_epochs="1" --mixed_precision="fp16" --save_precision="fp16" --caption_extension=".txt" --cache_latents --optimizer_type="DAdaptAdam" --optimizer_args weight_decay=0.75 decouple=True betas=0.9,0.99 --max_data_loader_n_workers="0" --keep_tokens="1" --bucket_reso_steps=64 --min_snr_gamma=5 --mem_eff_attn --shuffle_caption --bucket_no_upscale
On my poor little RX 6600, which ran out of VRAM above a batch size above 1, training took approximately 54 minutes.