[SD1.5] ColorSplash - V-prediction Vibrant Anime Mix









详情
下载文件 (2)
关于此版本
模型描述
WARNING: HERE BE DRAGONS!
This model's CLIP is incompatible with Model Toolkit. Do not use Model Toolkit to check/prune this model, for this is impossible without destroying the model itself. See this article for more information.
Also, this model uses zSNR and V-prediction. Download the .yaml config file and place it in the same folder as your models (for A1111/Forge); or use ModelDiscreteSampling node (for ComfyUI)
What is this model?
ColorSplash (previously named ColorStorm in preview images, now remade to work better) is a Stable Diffusion 1.5 merge created to test whether v-prediction can be merged in without losing too much quality. It's a work-in-progress as I try and make it work.
How to use this model?
Prompting:
This model (in my testing) uses booru tags very well, but can rarely use natural language.
Style is hard to influence with this model. With small prompt counts, the model is clean and crisp, but gets more distorted the more words is added. To counter this issue, Hi.res fix is highly recommended
Like most anime checkpoints, this one also has a female bias, but it can be countered.
This model is mainly tested against ComfyUI's prompt parser and reForge's default parser (with .yaml config file).
Character recognition should work well with really popular characters, but not much else. 9th Tail's character training is degraded, but not lost. ConcoctionMix's use of Hololive and AIOMonsterGirl isn't fully lost either, though it's also degraded a bit. Quick note: Suzuran's multiple tails might bleed through.
This model is also surprisingly good at furry content. Not quite sure why though...
Also, "brown-outs" happens when touching merged knowledge (tints the image brown in most cases), so do be careful about that.
Parameters:
(Anything in bold has been tested and working decently fine)
Sampler + Scheduler: Almost anything works, but with some browning. Best solution would be Euler beta, DPM++ 2M beta, with secondary recommendations being: Euler a, DPM++ 2M SGM Uniform, DPM Adaptive, UniPC simple, DDIM (with ddim_uniform), DPM++ SDE Beta. Karras schedulers are completely unusable. This is probably the only issue with v-prediction models
Steps: 20+
CFG: 4-12 (recommended range: 4-6, 7-12 is usable, but artifacted), RescaleCFG recommended
CLIP Skip: 1-2
Resolution: 3:2 aspect ratio tested, base 768 resolution and below (640, 512) are usable.
Hi.res fix: Highly recommended. Tested at 1.5x latent upscale
Merge recipe:
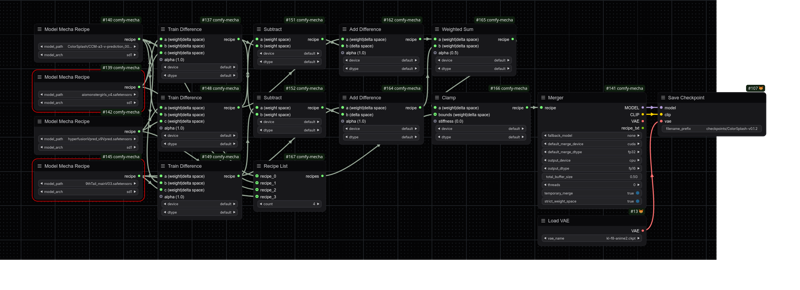
ColorSplash-v0.1
 The image is the entirety of the ColorSplash-v0.1 merging recipe in ComfyUI form. Uses comfy-mecha and ComfyUI-DareMerge [not properly]. Metadata included inside image.
The image is the entirety of the ColorSplash-v0.1 merging recipe in ComfyUI form. Uses comfy-mecha and ComfyUI-DareMerge [not properly]. Metadata included inside image.
It's a simple TIES merge (k=0.9) with:
Model A: 9th Tail - main_v0.3
Model B: ConcoctionMix-a1 [Vodka]
Model C: ConcoctionMix-a2 [Vermouth]
ColorSplash-v0.1.1
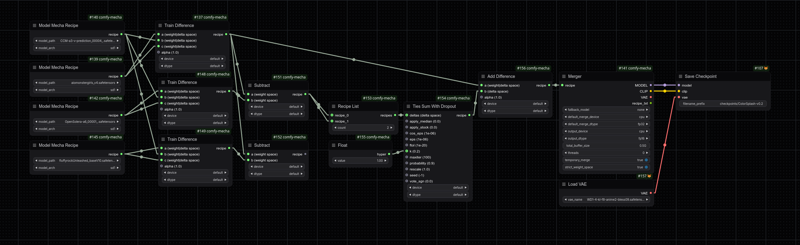 V0.1.1 uses exclusively comfy-mecha, since, I don't need to alter CLIP at all.
V0.1.1 uses exclusively comfy-mecha, since, I don't need to alter CLIP at all.
To those that can't read the image, it's a 2-step merge with 4 models:
Model A: ColorSplash - v0.1 (It was initially meant to be a ConcoctionMix experiment)
Model B: AIOMonsterGirl - v4 (more cohesive knowledge transfer)
Model C: OpenSolera - a6 [Fleur] (same idea)
Model D: FluffyRock Unleashed - v1.0 Base (same idea)
Step 1: Train Difference using A-x-A method, where x is model B, C, or D
Step 2: Perform a TIES Sum with Dropout (with k=1), then add it back into model A
ColorSplash-v0.1.2