RAYFLUX




















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
私のSDXLモデルをチェックしてください:
スタイル化モデル:RAYBURN
リアルisticモデル:RAYMNANTS
絵画的モデル:RAYCTIFIER
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
編集:ユーザー @sheerazrazak90434 および Hugging Face の awskr さんのご協力により、
v3 AIO の Draw Things 向けに変換されたバージョンを Hugging Face でこちら でご確認いただけます。
両者に感謝の気持ちを伝えます!
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
RAYFLUX v3 AIO のご紹介
AIOは、Photoplusが技術的にv2だった私のRAYFLUXシリーズの次世代モデルです。
これはv1の創造性をPhotoplusに取り戻し、T5、Clip、VAEをすべて内蔵した形で提供されます。そのため、Comfyで通常のLoad Checkpointワークフローを使って読み込んで使用できます。
お楽しみいただけることを願っています。
R.
どのように異なっているのか?
AIO は、写真に優れているだけでなく、創造性や一般の非写真的な被写体にも優れたパフォーマンスを発揮するよう設計された新しいモデルです。これはv1とPhotoplusのデータセットをマージし、カスタムLoRAのマージと手動のブロック重み調整を加えたものです。モデルをFP16に再アップロードしましたが、VAE、T5XXL-FP16、およびZerointがすでに内蔵したViT-L-14-BEST-smooth-GmP-TE-only-HF-formatを含むフルベースモデルを維持しながら、サイズを適切な範囲に抑えています。このモデルにはいくつかの癖がありますが、多くの被写体においてPhotoplusよりも優れた応答性を示すため、公開することにしました。
簡単に言うと:AIOはどんな题材にも優れた性能を発揮し、Photoplusがもたらした少し粒状の写真スタイルを維持しつつ、より創造的です。
例
黒いニカブで顔を覆った女性の、背景に濃い赤色を用いた、印象的なハイファッションのクローズアップ肖像。明るくドラマチックに照明され、布地の質感と女性の鋭いまなざしが強調されている

人差し指の上にとまっている若いクレストゲコの、鮮やかで詳細なクローズアップ写真。背景はぼかされた都市の夜景で、ボケ効果が豊か

20歳のスリムな女性のRAW写真。岩だらけの山頂で怒った表情を浮かべ、ピンクと紫の限られた色調

設定
AIO は、個人的に dpm_adaptive と ddim_uniform の組み合わせで最も輝きます。Photoplusやv1で使用したすべての設定は引き続き動作しますが、この特定の組み合わせの方がより創造的な結果を生み出します。
他のRAYFLUXモデルとは異なり、max shiftとbase shiftを調整できます。maxは1.2–1.8、minは0.5–1が適切な範囲です。Flux Guidanceは低い値で動作が最適で、2–3が最も良い範囲です。
参考までに、RAYFLUXv1.0 は Heun/beta を、Photoplus は DPM_adaptive/beta を使用していました。
ステップ数については、AIOは14〜20ステップで非常にうまく動作します。
注意点として、AIOは2MP解像度でも優れたパフォーマンスを発揮します!(下記の例を参照)
私は通常、SDアップスケールを2ステップ、ノイズ除去を0.2–0.3で2回目の処理を行います。求めるスタイルに応じて、アップスケールモデルを切り替えます。たとえば、粒状のポートレートには1x_ITF_SkinDiffDetail_lite(x2でも非常に効果的)、一般的なイラストには4xUltrasharp、ソフトでクリアなデジタルイラストスタイルには4x_Foolhardy_Remacriを使います。SDアップスケールで使用するプロンプトは全体的に非常に重要です。必要に応じて積極的に活用し、アップスケールを望む方向に導いてください(例:粒状にしたい場合は「grainy」と書き加える、よりソフトにしたい場合は「soft」とする、登場人物の詳細を追加するなど)。
以下はComfyでRayflux AIOを始めるための簡単な構成です。ノードが少なく、優れた結果が得られます!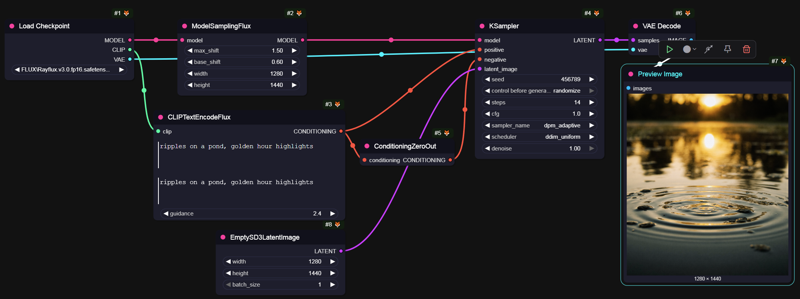
既知の問題/癖
乳首(男性・女性いずれも)。私のデータセットには裸体がほとんど含まれておらず、このバージョンもこの点を改善できていません。ただし、これに関する多くのLoRAが存在するため、大きな問題ではありません。
前のバージョンよりも処理が遅く、VRAMをより多く消費します。チェックポイントは21GBですが(T5、Clip、VAEを含むため、UNETの占有サイズは約16GB)、4090では1枚の2MP画像の生成に50〜60秒かかります。
調整の結果、シード間の変化が大幅に増えており、以前の2モデルと比較して、これは良い点ですが、安定させるために少し手間がかかります。
エンコーダーを内蔵することで、モデルの応答性と使い勝手が大幅に改善されましたが、ベースモデルのブロックで異なる精度(元はFP8をFP16にアップキャストし、その後追加学習)を使っているため、GGUFクアンタイズが難しくなりました。コメント欄のユーザーfoggyghost0もエンコーディング精度に関する問題を報告していますので、この問題の解決にご協力をお願いします。