Hunyuan YAW 6.7 (Yet another workflow) T2V I2V V2V audio, extend, random-lora, preview pause, upscale, multi-res, interpolate,prompt save/load,teacache,new interface, Fast

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
V6.9 バグ修正、互換性のないノードをさらに削除しました。ComfyUIとカスタムノードの頻繁な更新に対応するのは非常に難しいです。このバージョンがうまくいくことを願っています。
V6.7 I2Vのバグ修正、組み合わせによるビデオ拡張を追加、システムで使用可能な場合にTritonアクセラレーションを追加しました。このバージョンはしばらくの間バグがないことを願っています。ComfyUI、モデル、カスタムノードの変更に対応し続けるのは本当に大変でした。現時点ではI2VにはWanの方が優れていると感じています。このワークフローを実行するには、最新のComfyUIとカスタムノードに更新してください。
** 5090/5080/5070 50xxシリーズNVIDIA GPUの修正については、以下のトラブルシューティングセクションをご覧ください。
V6.6 I2Vがネイティブで実行可能になり、Skyreelsを削除、ランダム化スタックにヘルパーロラを追加。GGUFの低VRAM対応。システムRAMをVRAMとして使用可能。インターフェースを大幅に更新。初心者に最適で、上級者にも柔軟に対応。ComfyUIは頻繁に更新され、ノードのサイズが変わったり、機能が壊れたりして対応するのが大変です。最新のComfyUIとカスタムノードに更新してください。
V6で新機能!大規模な再設計。インターフェースに大幅な変更。ロラヘルパーを含む2つのランダム化ロラスタック、トリガー/プロンプト、ワイルドカード。オーバーナイト生成を強化!プロンプトの保存/読み込み機能追加。顔修復機能。オーディオ生成が改善され、単体のオーディオ生成、T2V、I2VをSkyReels経由でサポート、GGUF対応、システムRAMをVRAMとして使用可能。
** Wan 2.1ベータ版リリース:/model/1306165
詳細は下記の完全な説明をご覧ください。
ワークフローの主な特徴:
オーディオ生成 — MMaudio経由 — 動画に音声をレンダリング。単体プラグインも用意されており、オーディオのみの後処理が可能です。
オプションで一時停止可能な高速プレビュー生成
- 完全レンダリングを行う前に、数秒で動画のプレビューを確認できます
ロラランダマイザー — 12個のロラからなる2つのスタック。ランダム化、組み合わせ、マッチング可能。ワイルドカード、トリガー、プロンプトを含みます。ランダムなキャラクター+ランダムな動き/スタイルを組み合わせ、ワイルドカードを追加することで、理想的なオーバーナイト生成システムが構築できます。
プロンプトの保存/読み込み/履歴
複数の解像度
- セレクターで5つの一般的な解像度を素早く選択。独自のカスタム解像度を5つまで登録可能。
複数のアップスケール方法
標準アップスケール
補間(フレームレートを2倍)
V2V方式
複数のロラオプション
標準ウェイトを使用する従来のロラ
ダブルブロック(複数のロラを組み合わせる際にウェイト調整を気にせず使用可能)
ワイルドカード対応のプロンプティング
Teacacheによる高速化(1.6~2.1倍の速度向上)
すべてのオプションはトグル/スイッチで、手動でノードを接続する必要はありません
設定方法の詳細なノート
顔修復
テキスト2ビデオ、ビデオ2ビデオ、画像2ビデオ
24GB VRAM搭載の3090で完全にテスト済み
このワークフローは初心者でも使いやすく、上級者にも柔軟に対応することを目的としています。
これは私の初のワークフローです。個人的に動画制作のオプションが欲しく、このシンプルな試みを提供します。
追加情報:
AIとComfyUIの初心者です。これは私の最初のワークフローで、「Hunyuan 2step t2v and upscale」ワークフロー — /model/1092466/hunyuan-2step-t2v-and-upscale を大変気に入り、そのベースとして参考にしました。そのため、元のワークフローと同じ環境で動作するはずです。
** トラブルシューティング用ノードやComfyUIマネージャーは、このドキュメントの最下部に記載されています。
クイックスタートガイド:
デフォルトでは、すべて「Hunyuan 2step t2v and upscale」ワークフローに合わせて最適化されています。
このワークフローの手順:
ステップ0. モデルの設定:「Load Models」セクションで、解像度セレクターから希望の解像度を選択してください。
ステップ1. 低解像度のプレビューモデルをレンダリングし、ロラやモーションプロンプトが正しく動作しているか確認してください。
ステップ2. プレビューを見て、フルレンダリングを続行するか判断し、必要なら一時停止してください。
ステップ3. 低品質レンダリングを入力として使用し、より高品質な中品質レンダリングを生成します。これにより選択した解像度の2倍に拡張されます。
ステップ4. フレームごとのアップスケーラーを使用して、解像度をさらに2倍にします。
ステップ5. フレームレートを24fpsから48fpsに倍増し、より滑らかな動きを実現します。
(オプションステップ)MMaudio生成を有効化 — テキストプロンプトと動画の内容をもとに音声を生成します。シーンの音をテキストプロンプトに詳細に記述すると、より良い生成結果が得られます。この機能はVRAMを多く消費するため、デフォルトでは無効になっています。後から単体のMMaudioプラグインで音声を追加することも可能です。
ここからステップ数、動画長さ、解像度などを調整し、使用可能なVRAMに最適なバランスを見つけてください。
すべてのトグルとスイッチ:
 ステップ1では、必ず1つの方法のみ選択してください。
ステップ1では、必ず1つの方法のみ選択してください。
* これらはデフォルト設定です。
このワークフローでは、一切ノードの再接続が必要ありません。ワークフロー内に詳細な説明とコメントが記載されています。
V2V — ビデオからビデオ:
コントロールパネルで有効化:
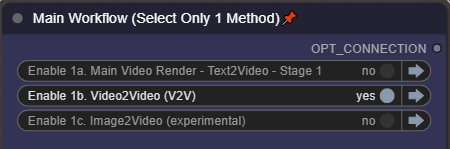
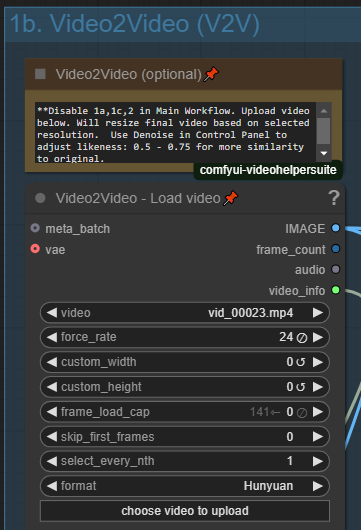 動画を入力またはガイドとして使用できます。コントロールパネルでこのオプションを有効化し、ソース動画をアップロードしてください。出力解像度は選択した解像度を使用します。
動画を入力またはガイドとして使用できます。コントロールパネルでこのオプションを有効化し、ソース動画をアップロードしてください。出力解像度は選択した解像度を使用します。
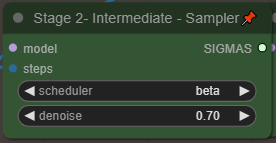 入力動画との類似度を調整するには、メインコントロールパネルの「Denoise」を調整してください。低い値(0.5 - 0.75)に設定すると入力動画に近い結果になり、高い値に設定するとより創造的な結果になります。
入力動画との類似度を調整するには、メインコントロールパネルの「Denoise」を調整してください。低い値(0.5 - 0.75)に設定すると入力動画に近い結果になり、高い値に設定するとより創造的な結果になります。
I2V — 画像からビデオ(ネイティブ)
この方法では、ネイティブHunyuanをI2Vに使用します。
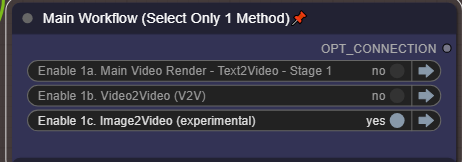
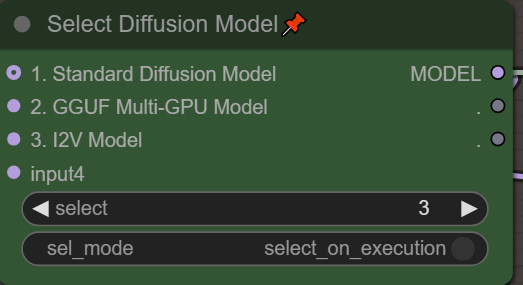
メインコントロールパネルで有効化し、ここでモデルを設定:
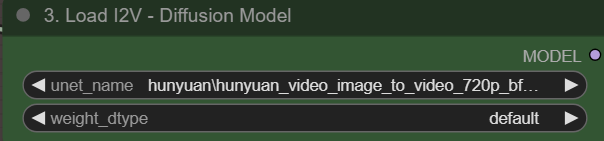 また、I2Vを実行する前にオプション#3を選択してください。
また、I2Vを実行する前にオプション#3を選択してください。
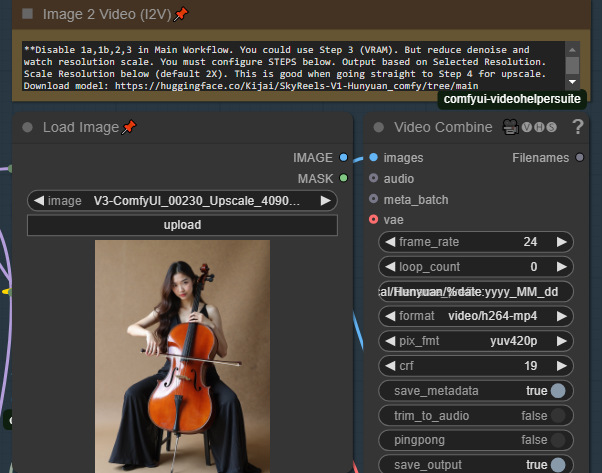 「Load image」でソース画像を読み込みます。画像はこのプラグインが壊れないように適切にスケーリングされます。出力解像度は、解像度セレクターで選択した解像度を使用します。I2Vは解像度に非常に敏感で、適切でないとフラッシングやアーチファクトが発生します。
「Load image」でソース画像を読み込みます。画像はこのプラグインが壊れないように適切にスケーリングされます。出力解像度は、解像度セレクターで選択した解像度を使用します。I2Vは解像度に非常に敏感で、適切でないとフラッシングやアーチファクトが発生します。
解像度には2つのオプションがあります。ソース解像度を使用したい場合は、「Use Orig IMG Resolution」スライダーを1に設定してください。ただし、これはアスペクト比を維持するだけで、トリミングは行われません。もう一つのオプションは「Base Scale」(デフォルト384)です。ビデオエンジンの制限により、非常に高解像度の画像をネイティブ解像度でレンダリングするとすぐにメモリが不足します。これはBase Scaleに基づいてレンダリングサイズをスケーリングします。最初は384–500で試し、VRAMが処理できるか確認してください。特にソース画像が非常に高解像度の場合。低解像度の画像から始める場合、スライダーをかなり上げることができます。

I2V 方法1:1パスでアップスケール/補間/オーディオ
この方法の主な使用方法は、メインワークフローで1a、1b、3を無効にすることです。画像を入力として受け取り、選択した解像度で動画をレンダリングし、ステップ4/5に送ってアップスケールと補間を行います。コミュニティの協力を得て、最適なサポートI2V解像度を見つける必要があります。いくつか試してみてください。
動画拡張:
I2V対応解像度を選択(誰かがHunyuanの対応解像度リストを持っている場合は、コメント欄で共有してください)。最初のフレームにI2Vを使用するため。
コントロールパネルで1d、2、4、5を有効化(3をスキップ)
この段階では、低~中解像度の入力ソースを使用することが非常に重要です。メモリが不足します。* I2Vと同様のルール
T2Vの2段階レンダリングから中間レンダリングを使用するか、手動で低~中解像度を動画に設定。または元の動画解像度を使用することも可能。中間ソースまたはT2V 2段階法の中間レンダリングを使用する場合、完璧に動作します。この機能はその目的で設計されています。
拡張部分のみをレンダリングするか、完全な統合動画をレンダリングするかを選択。完全な統合動画(元の動画+拡張動画)を出力したい場合は「True」を選択。これにより、完全統合動画が次のアップスケーラーに渡されます。そのため、中間レベルの動画を使用することが重要です。これにより、再度アップスケールと補間が行われます。
ステージ1 — 選択したステップと解像度で1パスのフルレンダリングを実行
一時停止し、アップスケーラーに進むか、キャンセルして再試行するか判断
アップスケーリング — 中間レンダリングを取得し、解像度を2倍に
補間 — フレームレートを2倍に
モデル選択(低VRAMオプション):
24GB VRAMの環境でテストしましたが、多くのユーザーが低VRAMでの使用を要望したため、いくつかの機能を追加して対応を試みます(未検証ですが、役立つことを願っています)。
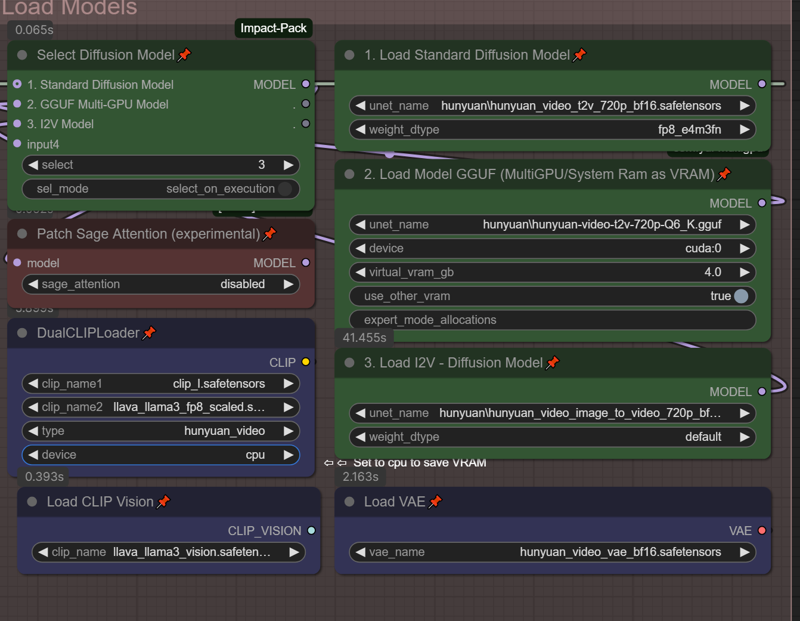 標準のBF16/FP8またはFP8モデルを「1. Load Standard Diffusion Model」に読み込む
標準のBF16/FP8またはFP8モデルを「1. Load Standard Diffusion Model」に読み込む
GGUFモデルを「2. Load Model GGUF (MultiGPU/System Ram as VRAM)」に読み込む
ご存じの通り、GGUFモデルは少し時間がかかりますが、選択したモデルによってVRAMの消費を大幅に削減できます。
グリーンのセレクターボックスで、ワークフローで使用するモデルを選択してください。
VRAM節約のため、DualCLIPローダーの「device」をCPUに設定してください。オプションが表示されない場合は、右クリックして「Show Advanced」を選択すると表示されます。
GGUFモデルを使用する場合、「use_other_vram」を「true」に設定してください。これにより、システムRAMをVRAMとして使用可能になり、OOMエラーを回避できる可能性があります。上記で使用する仮想VRAMの量を設定できます。システムRAMを使用する場合、レンダリング時間は大幅に長くなりますが、少なくとも処理は停止しません。
** また、24GBサイズのGGUFモデルがあることに気づきました。これはBF16モデルと同等の品質でしょうか?品質を犠牲にしたくありませんが、仮想VRAM機能を使いたいです。ご存知の方はコメント欄でお知らせください。
ロラオプション:
従来のロラとダブルブロックの両方が使用可能で、デフォルトはダブルブロックです。
ダブルブロックは、複数のロラを組み合わせる際に、ウェイト調整をあまり気にせずに使用できる傾向があります。
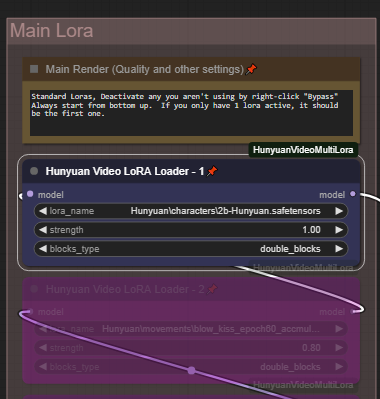 メインロラスタックは標準的な加算型ロラツリーです。最大5つの異なるロラを追加または組み合わせ、使用するロラに応じてall、single_blocks、double_blocksを設定できます。これらのロラをランダムロラと併用可能です。メインロラセクションにスタイルを追加し、ランダムなキャラクターロラとランダムなキャラクターアニメーションを追加してください。
メインロラスタックは標準的な加算型ロラツリーです。最大5つの異なるロラを追加または組み合わせ、使用するロラに応じてall、single_blocks、double_blocksを設定できます。これらのロラをランダムロラと併用可能です。メインロラセクションにスタイルを追加し、ランダムなキャラクターロラとランダムなキャラクターアニメーションを追加してください。
ロラの有効/無効は右クリックして「Bypass」を選択して切り替えます。
解像度オプション:
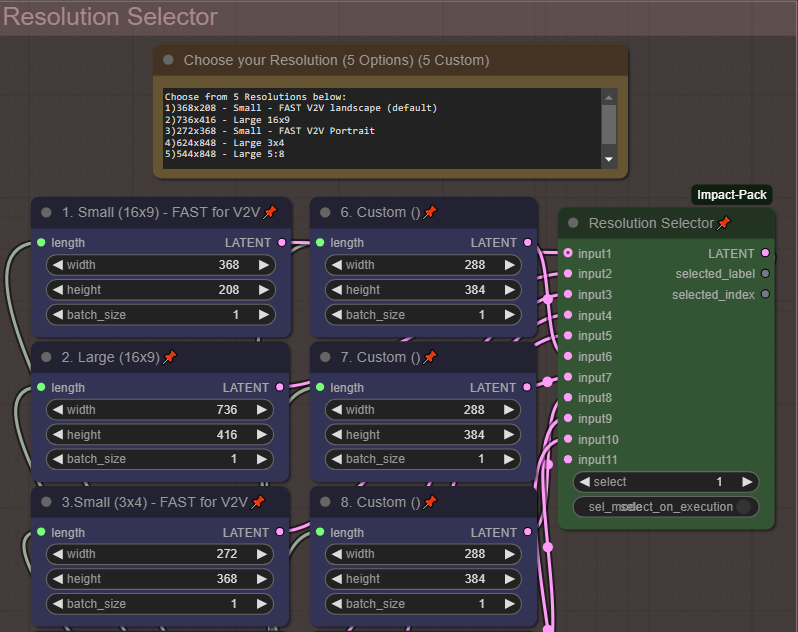 5つの一般的な解像度から選択。さらに5つのカスタム解像度を編集して独自に設定可能。解像度は「Resolution Selector」で変更。デフォルトでは、最も速く小さな解像度が選択されており、ワークフローの次のV2Vパートに適しています。解像度を大きくすると、レンダリング時間が大幅に長くなります。
5つの一般的な解像度から選択。さらに5つのカスタム解像度を編集して独自に設定可能。解像度は「Resolution Selector」で変更。デフォルトでは、最も速く小さな解像度が選択されており、ワークフローの次のV2Vパートに適しています。解像度を大きくすると、レンダリング時間が大幅に長くなります。
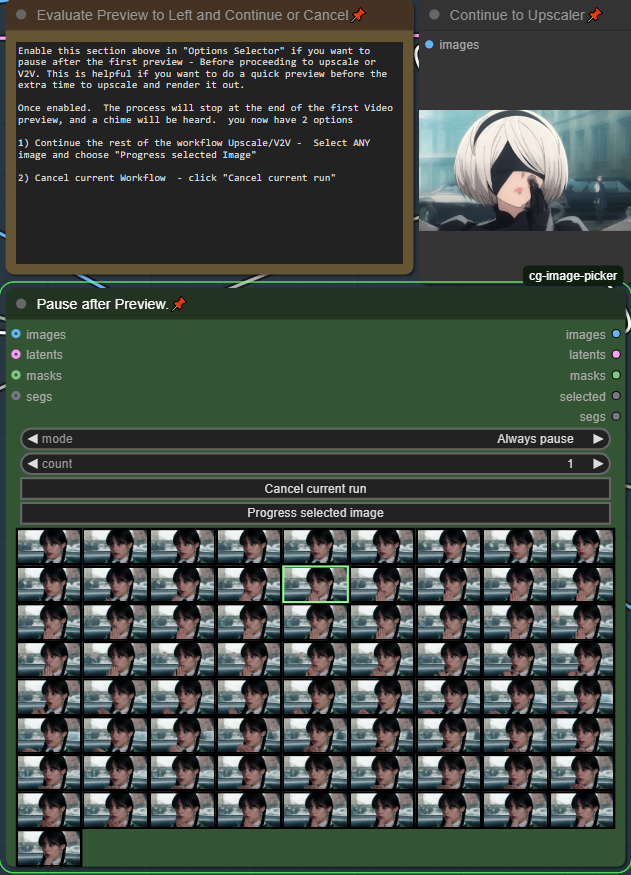
プレビュー後の一時停止(デフォルトで有効)
動画生成には時間がかかり、複数のロラを試したり、プロンプトを最適化したりするのに、レンダリング時間が長いと大変です。この機能を使えば、アップスケール処理の前に動画を素早くプレビューできます。デフォルトでは有効になっています。ワークフローを開始すると、高速プレビューがすぐにレンダリングされ、チャイム音が鳴ります。次に進むには、動画プレビューの横の中間セクションまでスクロールしてください。
気に入ったプレビューをアップスケールするか、キャンセルして再試行できます!
フルレンダリング/ワークフローを継続 — いずれかの画像を選択(どの画像でも構いません)し、「Progress Selected Image」をクリック
キャンセル — 「Cancel current run」をクリックし、別のプレビューをキューに追加
 この機能を無効にするには、「オプションセレクター」でオンオフを切り替えてください。
この機能を無効にするには、「オプションセレクター」でオンオフを切り替えてください。

MMaudio - 動画に音声を自動追加
デフォルトでは、アップスケールされた動画のみに音声を追加します。ただし、レンダリングプロセスのすべての部分に音声を追加するスイッチがあります。より良い生成結果を得るには、プロンプトに音声の詳細を含めてください。
注: MMaudioは追加のVRAMを消費します。MMaudioを使用する際は、動画の長さと画質のバランスを取る必要があります。v5.2以降ではスタンドアロンプラグインが利用可能で、メインワークフローで動画を最終決定した後で音声を追加できます。これにより、VRAMに応じて画質と動画の長さを最大限に引き出し、ポストプロセスの追加ステップとして音声を簡単に追加できます。スタンドアロン方式では、動画に最適な音声を得るために複数回生成できるため、より柔軟性があります。
アップスケール後の補間
このオプションにより、レンダリングされた動画のフレームレートを2倍にできます。デフォルトでは「有効」です。
「オプションセレクター」で無効にできます。必要がない場合は、レンダリング速度が遅くなる可能性があります。

速さが必要だ。速さが!
処理が遅すぎるですか?品質を少し犠牲にして、Teacacheスピードを最大2.1倍まで上げることができます。デフォルトは「Fast(1.6倍)」です。ただし、Teacacheサンプラーノードが2つあることにご注意ください。
T2V - テキストから動画へ - プロンプトとワイルドカード
プロンプトは、緑色の「Enter Prompt」ノードに入力してください。***プロンプトに改行や改行コードが含まれていると、システムがワークフローを処理する方法が変わってしまうため、注意してください。
ワイルドカードは、プロンプトを自動で変更したり、夜間生成でバリエーションを加えるために使用できる機能です。ワイルドカードを作成するには、/custom_nodes/ComfyUI-Easy-Use/wildcardsフォルダ内に .txt ファイルを作成してください。各行に1つのワイルドカードを記述し、改行で区切ってください。単語またはフレーズを使用できますが、「改行」で区切ることを忘れないでください。ダブルスペースは使用しないでください。以下に2つのワイルドカードファイルの例を示します。
color.txt
red
blue
green
locations.txt
a beautiful green forest, the sunlight shines through the trees, diffusing the lighting creating minor godrays, you can hear the sound of tree's rustle in the background
a nightime cityscape, it is raining out, you can hear the sound of rain pitter patter off of the nearby roofs
a clearing in the forest, there is a small but beautiful waterfall at the edge of a rockycliff, there is a small pond and green trees, the sound of the waterfall can be heard in the distance, birds are chirping in the background
プロンプトでこれらのワイルドカードを使用するには、「select to add wildcard」をクリックし、プロンプトの適切な位置に追加してください。

ellapurn3ll is wearing a __color__ jacket ,she is in __locations__.
このカスタムノードの詳細は以下をご覧ください:https://github.com/ltdrdata/ComfyUI-extension-tutorials/blob/Main/ComfyUI-Impact-Pack/tutorial/ImpactWildcard.md
ランダムLoRAとトリガー
ワイルドカードとランダムLoRAを組み合わせて、夜間生成の質を向上させましょう。
最大12個のランダムLoRAを選択して組み合わせることができます。デフォルトでは最初の5つのみ有効です。適切な設定で「最大数」を変更して、設定したLoRAの数を指定してください。LoRAは常に上から下へ数えられるため、3つのLoRAのみランダム化したい場合は「最大」を3に設定し、上位3つのLoRAの情報を入力してください。
非常に重要: トリガーワードを自動挿入するには、プロンプトフィールドに次のテキストを含める必要があります:
(LORA-TRIGGER) または (LORA-TRIGGER2)
これにより、ランダムLoRAを使用して生成する際に自動的に値が挿入されます。大文字・小文字は区別されるため、注意してください。
フルプロンプト、単一のトリガー、またはトリガーフレーズを記述でき、これらは自動的に挿入されます。
ここにワイルドカードを追加するには、{} で囲み、| で区切ってください。例:She is wearing a {red|green|blue} hat。またはフルプロンプトも可能:{she is standing in time square blowing a kiss|she is sitting in a park blowing a kiss}
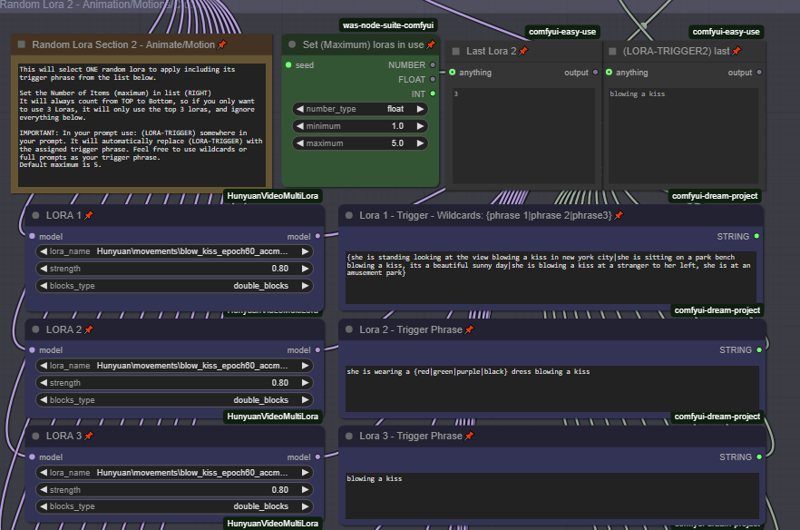 Helper LoRAは、ランダムLoRAスタック2でのみ利用可能です。
Helper LoRAは、ランダムLoRAスタック2でのみ利用可能です。
Helper LoRAが追加されました。一部のLoRAは、モーションLoRAやスタイルLoRAを追加することでより良い結果が得られます。Helper LoRAを有効にすると、2番目のランダムスタックでのみ有効になり、ランダム化プロセスでそのLoRAが選択された場合にのみ適用されます。たとえば、LoRA 1にモーションまたはスタイルLoRAを追加すると効果的であれば、LoRA 1 Helperを有効にし、ランダム化でLoRA 1が選ばれた場合、両方のLoRA(メインとヘルパー)が適用されます。
 これは主に上級者向けの機能ですが、一部のユーザーにとって役立つ可能性があります。
これは主に上級者向けの機能ですが、一部のユーザーにとって役立つ可能性があります。
「Prompt Saver」でお気に入りのプロンプトを読み込み・保存
 ワークフローを実行すると、Prompt Saverに最新のプロンプトが自動で登録されます。後で使用するために保存できます。プロンプトを読み込んで使用するには、以前保存したプロンプトを選択し、「Load Saved」をクリックしてください。ただし、読み込んだプロンプトを使用するには、「Use Input」を「Use Prompt」に切り替えることが重要です。通常のプロンプト使用に戻る際は、忘れずに「Use Input」に切り替えてください。
ワークフローを実行すると、Prompt Saverに最新のプロンプトが自動で登録されます。後で使用するために保存できます。プロンプトを読み込んで使用するには、以前保存したプロンプトを選択し、「Load Saved」をクリックしてください。ただし、読み込んだプロンプトを使用するには、「Use Input」を「Use Prompt」に切り替えることが重要です。通常のプロンプト使用に戻る際は、忘れずに「Use Input」に切り替えてください。

デフォルトは「Use Input」です。 この設定では、プロンプトは通常の入力ワイルドカードフィールドから生成され、Prompt Saverにはプロンプトデータが表示されるだけです。
すべてを統制するシード:
1つのシードがすべてのLoRAランダム化、ワイルドカード、および生成を管理します。ランダムLoRAとワイルドカードを使用しても、お気に入りのシードをそのままコピーして再利用できます。
 * ヒント:リサイクルボタンをクリックすると、直前のシードを再利用できます。最近生成した動画を微調整したいですか?2段階目でOOMエラーが出た場合は、前のシードを使用して調整し、再試行してください!
* ヒント:リサイクルボタンをクリックすると、直前のシードを再利用できます。最近生成した動画を微調整したいですか?2段階目でOOMエラーが出た場合は、前のシードを使用して調整し、再試行してください!
スタンドアロンMM-Audio:
画質と動画の長さを最大限に引き出すために、メインワークフローでMM-audioを無効にし、ポストプロセス段階で音声を追加することをおすすめします。このプラグインは、後から音声を追加するためにスタンドアロンとして実行することを目的としています。
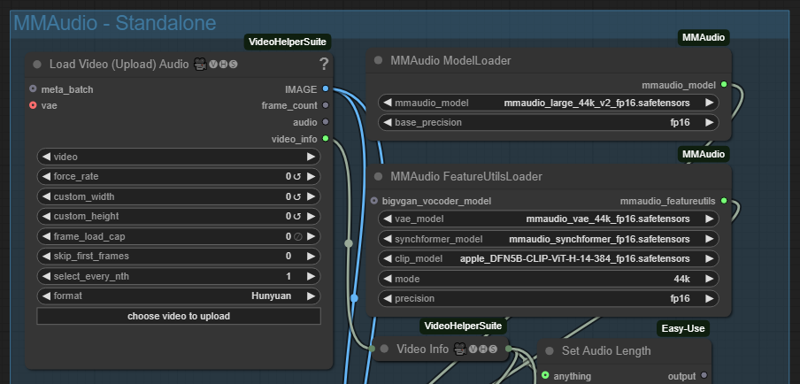 MMAudio - Standaloneを有効にし、ワークフローの他のすべての部分を無効にしてください。
MMAudio - Standaloneを有効にし、ワークフローの他のすべての部分を無効にしてください。
音声を追加したい動画をアップロードするだけです。すべての計算は自動で行われます。空白または空のプロンプトを使用することを推奨しますが、以前保存したプロンプトを読み込みたい場合は、Prompt Saverも用意されています。
(オプション)音声やシーンの音に関する記述に焦点を当てて、プロンプトを強化できます。
音声が完璧になるまで、何度でも生成してください!
スタンドアロンアップスケーラーと補間:
既存の動画ファイルをアップスケールまたは補間したいだけですか?それらをアップロードし、アップスケーラーと補間以外のワークフローのすべての部分を無効にしてください。
アップロードボックスは適切な場所で有効にする必要があります。
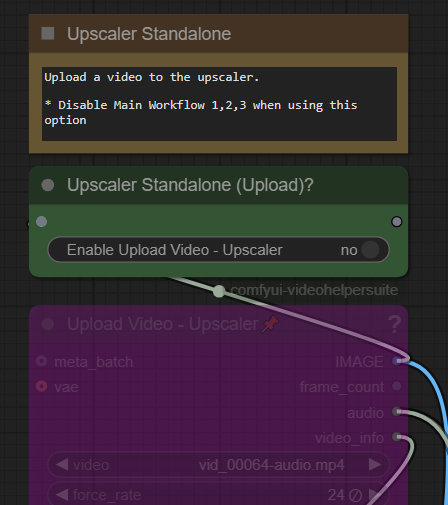 この機能を使用するには「Yes」に切り替えてください。通常のワークフローを使用する際は、忘れずに無効にしてください。デフォルトでは両方とも無効になっています。
この機能を使用するには「Yes」に切り替えてください。通常のワークフローを使用する際は、忘れずに無効にしてください。デフォルトでは両方とも無効になっています。
ワークフローの使い方のヒント
Fast、V2V方法、LoRA(デフォルト)— これは元のワークフローに従います。
ファスト低解像度動画でクイックプレビュー:使用
(解像度1 - 368x208):横長動画の場合
(解像度3 - 320x416):縦長動画の場合
完全レンダリングを行うか決めるために一時停止
完全レンダリングには音声、アップスケーリング、補間が含まれます
T2Vを直接アップスケーリングする方法
中程度または高解像度でレンダリングし、その後アップスケーラーと音声を追加
解像度2、4、5のオプションを使用して高解像度化 — レンダリング速度は遅くなります。私は個人的にほとんどの生成に解像度4を使用しています
アップスケーリングと音声追加が行われます
設定
「Options」メニューから「Intermediate V2V」を無効にしてください
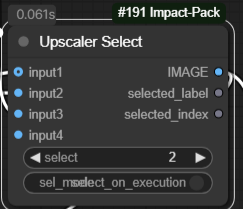
 アップスケーラーの入力2を選択
アップスケーラーの入力2を選択
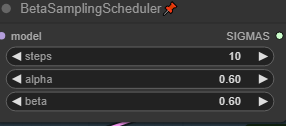
 メインウィンドウのBetaSamplingSchedulerで「steps」を25以上に増やしてください
メインウィンドウのBetaSamplingSchedulerで「steps」を25以上に増やしてください
生成の品質を向上させる
ステップ数を増やす:
デフォルトのV2V方法の場合。コントロールパネル(Settles)でステップ数を24から35以上(最大50)に増やしてください。1ステップごとに時間がかかり、メモリも消費されるため、解像度とステップ数のバランスを見つけてください。
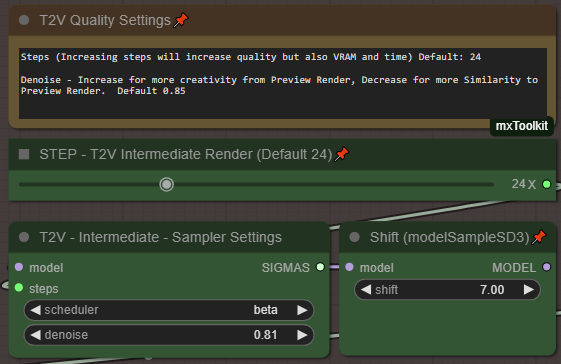
メインレンダリングプレビューまたは中間をバイパスする場合、ステップ数を12から大幅に増やしてください。例:30/35
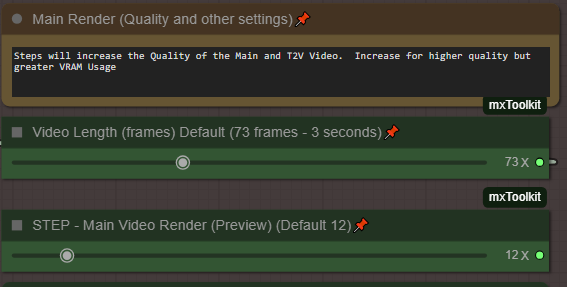
最高品質を得るには、ステップ数を35以上に設定し、Teacacheノード(メイン/中間)の両方を「Fast 1.6」ではなく「Original 1X」に下げてください!
より高い解像度を試す:
解像度をLargeの高い解像度(例:解像度2または4)に変更し、キューに追加します。基本的に、同じ動画をより高解像度で得られます。デフォルトでは、Large解像度はSmallの2倍の解像度であるため、この方法を使用する際に一貫性を保つのに役立ちます。常に同じアスペクト比を使用してください(例:1→2、3→4)。
完璧な動画のための動画長さと品質のバランス
以下は、3090 24GB VRAMでテストした、動画長さと品質のバランスをとるために使用した設定例です。
最長動画長さ(16x9):
解像度1を使用、動画長さを201フレームに設定、Basic SchedulerでI2V中間ステップを「23」または「24」に設定、Schedulerを「beta」に設定。MM-audioを無効にし、アップスケーラーと補間を使用してください。
より長い動画については、メインビデオレンダリングのステップを15に設定することを推奨します。
プロトゥップ: 201フレームはHunyuan動画の最大サイズであり、この長さで完璧なループを生成する傾向があります。
高品質(16x9)(3x4):
解像度1または3を使用、動画長さを97フレームに設定、MainVideo Render BetaSamplingSchedulerのステップを「15」に設定、Basic SchedulerでI2V中間ステップを「35」に設定、Schedulerを「beta」に設定。MM-audioを無効にし、アップスケーラーと補間を使用してください。
音声付きバランス(16x9、3x4):
解像度1または3を使用、動画長さを73または97フレームに設定、Basic SchedulerでI2V中間ステップを「28」に設定、Schedulerを「beta」に設定。MM-audioを有効にし、アップスケーラーと補間を使用してください。
問題解決:
5090/5080/5070 50xxシリーズNVIDIA GPUの対応策
50xxシリーズのNVIDIA GPUはまだ開発中です。以下は、Python 3.12.Xがバンドルされた標準的なComfyUIポータブル版を使用するためのヒントです。
NVIDIA 50xxシリーズにGPUをアップデートしたばかりで、何も動かない!?
以下は、3090 24GB VRAMでテストした、動画長さと品質のバランスをとるために使用した設定例です。
標準的なComfyUIポータブル版をダウンロードするか、既存のフォルダを使用してください。
Cuda 12.8をインストール
(Torch 2.7 devをインストール)
python_embeddedフォルダに移動
python.exe -s -m pip install --force-reinstall torch==2.7.0.dev20250307+cu128 torchvision==0.22.0.dev20250308+cu128 torchaudio==2.6.0.dev20250308+cu128 --index-url https://download.pytorch.org/whl/nightly/cu128 --extra-index-url https://download.pytorch.org/whl/nightly/cu128
(Triton 3.3 プレビュー版)
python.exe -m pip install -U --pre triton-windows
python.exe -m pip install sageattention==1.0.6
(Sage Attention)
SET CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8
cd sageattention
..\python.exe setup.py install
上記が動作しない場合は、以下の記事を参照し、
setup.pyをこちらのコードで置き換えてください。https://github.com/thu-ml/SageAttention/issues/107
これで、通常通り実行できるはずです。以前正常に動作していたノードの一部が、なぜか動作しなくなる場合があります。理由は不明ですが、まもなくワークフローを更新し、5090、5080、5070シリーズのGPU向けの修正を追加します。
** なお、私はこの分野の専門家ではありません。トラブルシューティングのサポートはできません。これは、私のシステムで動作させるために実行した手順です。
モデルの読み込みまたは不足の問題:
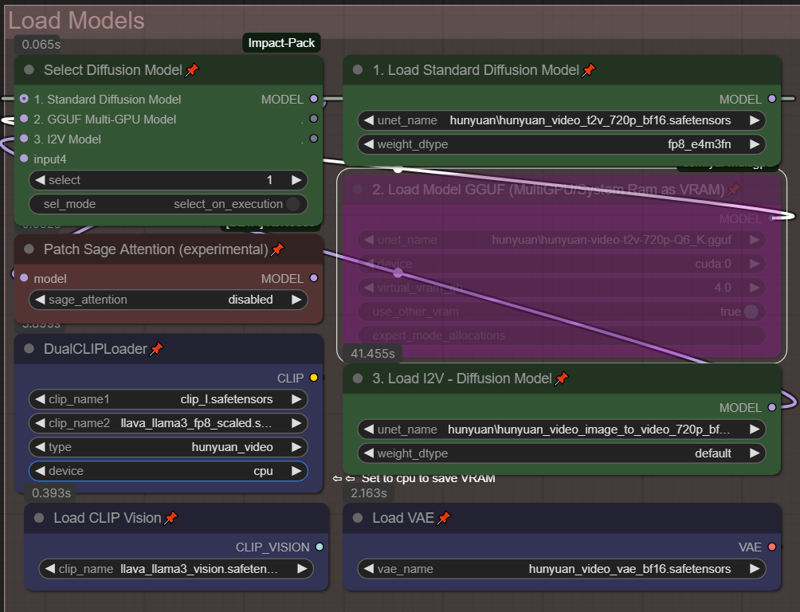
ワークフローでは、緑色と紫色のモデルをそれぞれ1つずつダウンロードして設定・割り当てていることを前提としています。T2V、V2Vの場合は、低VRAM用に#1または#2のGGUFを選択してください。I2Vの場合は#3を選択してください。これらのすべてのモデルが正しく定義されていることを確認してください。たとえば、GGUFを使用しない場合は、2番目のボックスを右クリックして「バイパス」を選択することで、ワークフローが欠落したモデルについて警告しないようにできます。
ノードが不足している場合:
MMaudio - 音声ノードが読み込まれない場合は、ComfyUI Managerを開き、以下のURLを使用して「Git URLからインストール」を行ってください:https://github.com/kijai/ComfyUI-MMAudio
その後、再起動してください。
セキュリティエラーが発生した場合は、以下に移動してください:ComfyUI/user/default/ComfyUI-Manager に移動し、config.ini をメモ帳で開いて「security_level = normal」という行を探します。これを「security_level = weak」と変更してください。その後、インストールを試みてください。インストールが完了したら、設定を再度「normal」に戻すことができます。MMaudioに関するその他の情報は、GitHubページでご確認ください。
UnetLoaderGGUFDisTorchMultiGPU が不足している場合:ComfyUI Manager で「ComfyUI-MultiGPU」を検索してください。
また、ComfyUIに「ComfyUI-GGUF」がインストールされていることも必須です。これら2つの拡張機能が、ComfyUI Manager で正しく検索され、ロードされていることを確認してください。
上記で動作しない場合、ComfyUI Manager で「Git URLからインストール」を試みてください:https://github.com/pollockjj/ComfyUI-MultiGPU
セキュリティエラーが発生した場合は、ComfyUI/user/default/ComfyUI-Manager に移動し、config.ini をメモ帳で開いて「security_level = normal」を「security_level = weak」に変更してから、ComfyUI Manager から再度インストールを試みてください。
最終手段として、MultiGPUを完全に無効にしたい場合(推奨しません):「モデル読み込み」セクションに移動し、緑色のセレクタースイッチ「Diffusion Model」が「1」に設定されていることを確認してください。その後、「2. Load Model GGUF(multiGPU/System Ram as VRAM)」というノードを単純に削除してください。これですべてが正常に動作しますが、GGUFとそのVRAM最適化のオプションが使用できなくなります。
 このノードを削除してください。
このノードを削除してください。
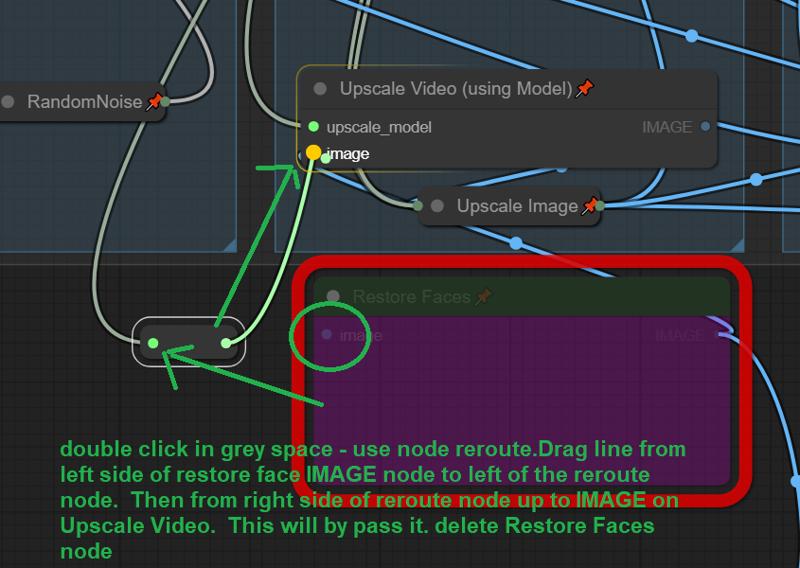
ReActor または フェイス強化ノードが不足している場合:
Re-Actorノードで問題が発生した場合は、簡単に削除できます。理論的には、デフォルトでバイパスされているため、ワークフローはこのノードなしでも動作します。
レッドの「Restore Faces」ボックスに移動し、グレーの領域のどこかをダブルクリックして、検索ボックスに「reroute」と入力し、ノードを追加してください。
「Restore Faces」の左側の入力ラインを、新しく追加したノードの左側に接続してください。
「reroute」ノードの右側から、「Upscale Video」のImage入力に新たな接続を追加してください。その後、「Restore Faces」ノードを完全に削除できます。
以上です。すべてのオリジナル作者に感謝します。
お楽しみいただければ幸いです。このようなオープンで共有のコミュニティに参加できて素晴らしいです。
ぜひ、このワークフローで作成した作品や設定を共有してください。