HiDream Full GGUF-Q5_K_M UNCENSORED🔞




















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
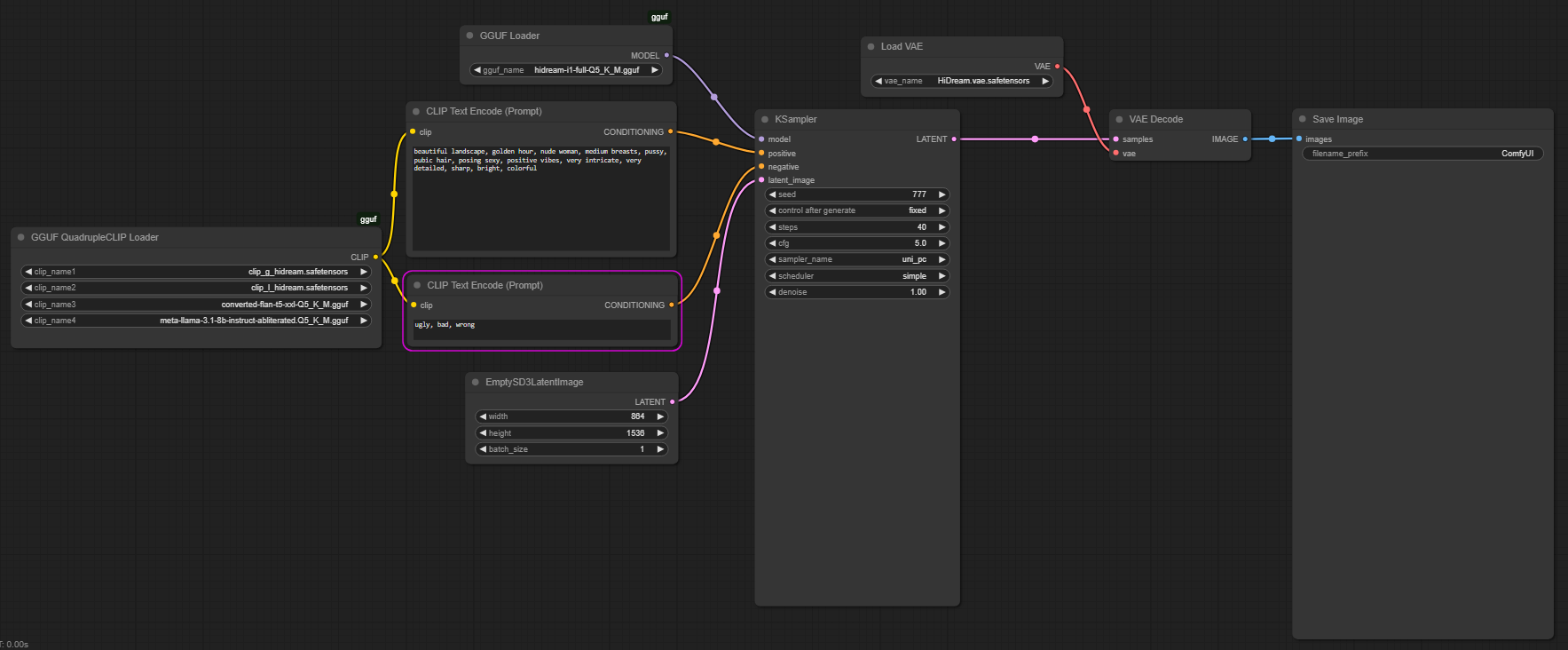
これは、HiDreamフルモデルの最適化(品質/速度|VRAMの観点から)された量子化バージョンであり、完全に「ロボトミー化」=検閲解除されたテキストエンコーダー(Meta Llama 3.1)を搭載しています
このファイルセットには、HiDreamを**格段に優れた、そして検閲解除された**ものにするための2つの主要な要素が含まれています:
便利なトリック:t5-v1_1-xxl-encoder-Q5_K_M.gguf の代わりに、converted-flan-t5-xxl-Q5_K_M.gguf を使用して、テキストからベクトルへの変換/エンコードを改善しています。
主な秘訣:meta-llama-3.1-8b-instruct-abliterated.Q5_K_M.gguf — Meta-Llama-3.1-8B-Instruct-Q5_K_M.gguf の代わりに使用 → LLMの「アブリテレーション/検閲解除」プロセスについて詳しくは以下を参照:https://huggingface.co/blog/mlabonne/abliteration(彼のHuggingFaceリポジトリから他の検閲解除済みLLMも入手できます...)
したがって、単に次のようにしてください:
アーカイブファイルを展開してください!
hidream-i1-full-Q5_K_M.gguf ファイルを ComfyUI\models\unet フォルダに配置してください。
converted-flan-t5-xxl-Q5_K_M.gguf、meta-llama-3.1-8b-instruct-abliterated.Q5_K_M.gguf、clip_g_hidream.safetensors、clip_l_hidream.safetensors を ComfyUI\models\text_encoders フォルダに配置してください。
HiDream.vae.safetensors を ComfyUI\models\vae フォルダに配置してください。
検証用に、私の検閲解除済みHiDream-Full Workflow.jsonを開始ワークフローとして使用してください。
VRAMの問題が発生した場合は、私のVRAM最適化batファイル:run_nvidia_gpu_fp8vae.bat を使用してComfyUIを起動してください(ComfyUIフォルダ内に直接配置してください)。
この方法で、12GBのVRAMでも高品質なHiDream-Full画像生成が可能です(検証済み!)
Update1: テキストエンコーダー部分に、他の検閲解除済みMeta Llama 3.1バージョンを使用することもできます。たとえば、この画像:https://civitai.com/images/71818416 では、DarkIdol-Llama-3.1-8B-Instruct-1.2-Uncensored-GGUF を使用しています。
Update2: こちらのCLIP-Gをお試しください → /model/1564749?modelVersionId=1773479