WAN2.1-VACE-14B 1.3B GGUF 6 steps AIO (t2v-i2v-v2v-FLF-controlnet-masking-long duration) simple ComfyUI workflow
세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
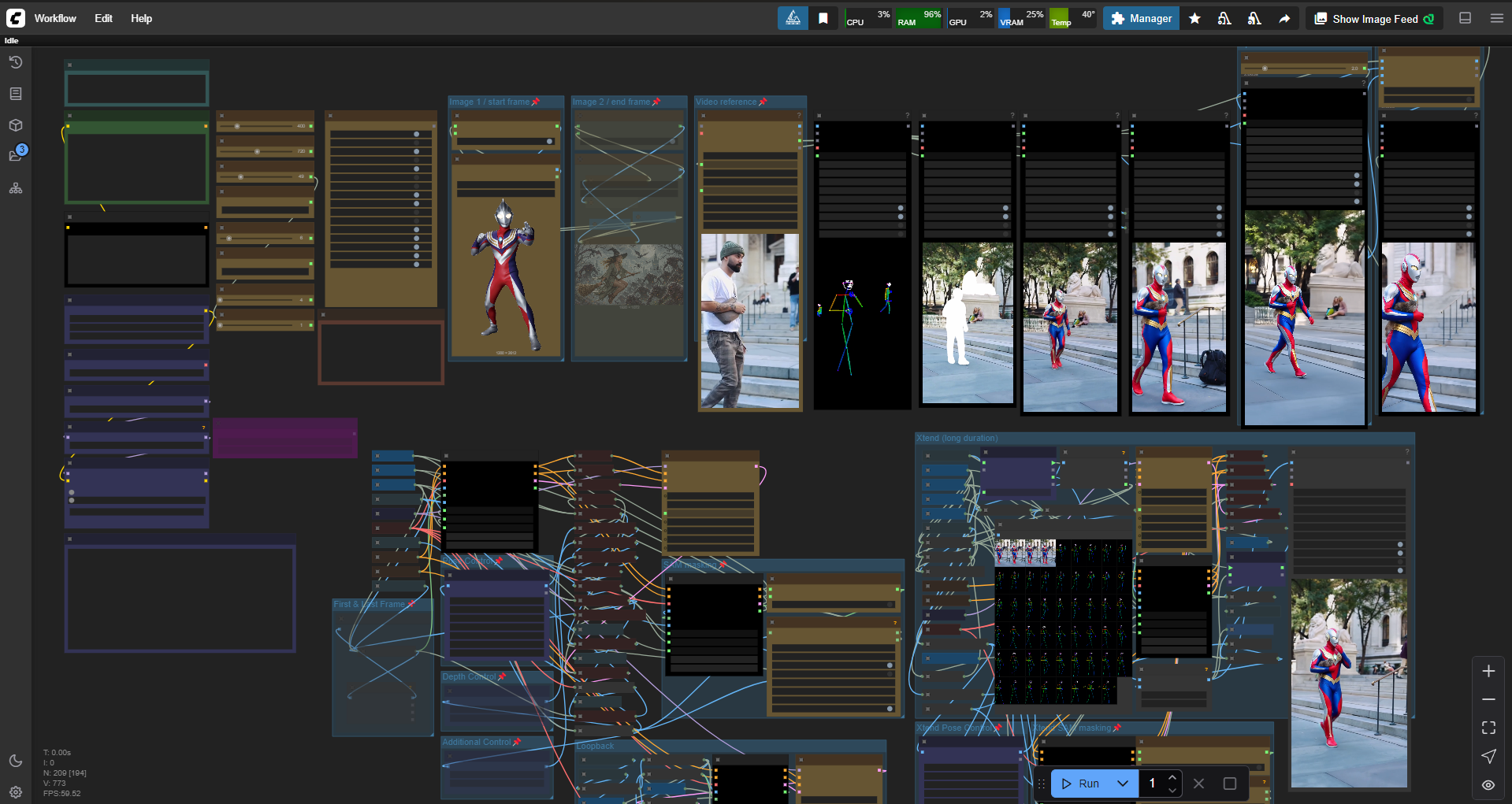
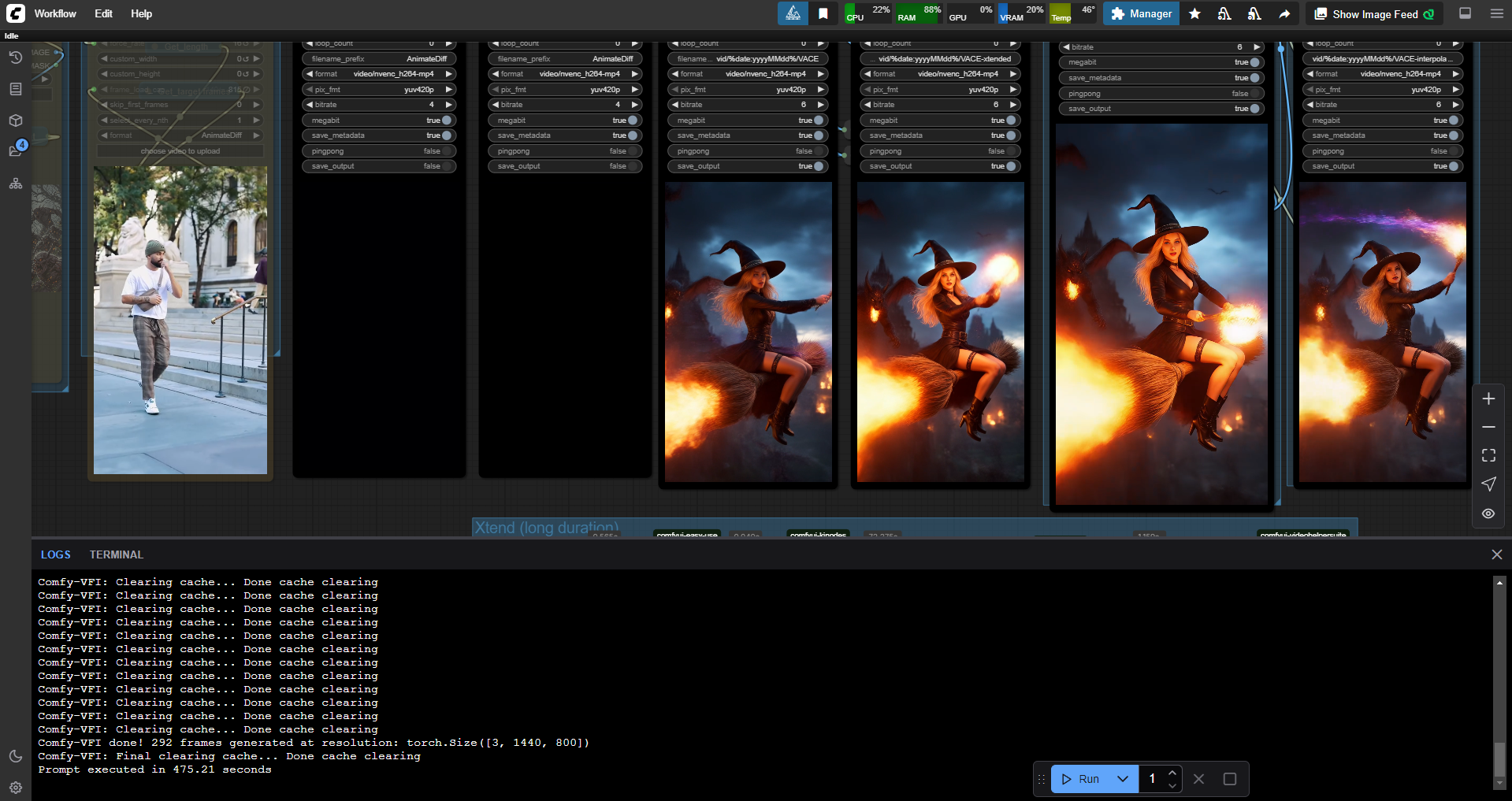
Comfyui workflow for text to video, image to video, video to video, video stylize, video character replacement, clothes swapper, long video generation, low VRAM, 6 steps, all in one simple ULTIMATE workflow.
=====================
v2 Coming soon
add prompt progression/scheduler
add xtend existing video
add 2 image reference
=====================
v1.20250724 Ultimate
add xtend long video generator (with controlnet+masking available)
add loopback feature
better upscale and uprte method
higher resolution for the same VRAM
Framepack killer
=====================
READ ME‼️‼️
Adjust only parameters in YELLOW nodes
prompt the GREEN node in detail
read the MUTER SWITCH GUIDE and MODEL GUIDE
check additional switchs/adjustment in YELLOW nodes
leave the BLACK nodes intact
bypass SAGE ATTENTION node if you don't have it installed
====================
MODEL GUIDE
Use VACE model + CauseVid and/or Self-Forcing lora
14B for quality
1.3B for faster inference
Change GGUF Loader node to Load Diffusion Model node for .safetensor files
===========================================================
14B VACE model GGUF + CauseVid lora (6 steps only)
https://huggingface.co/QuantStack/Wan2.1_14B_VACE-GGUF/tree/main
or
14B FusionX VACE GGUF (CauseVid merged)
https://huggingface.co/QuantStack/Wan2.1_T2V_14B_FusionX_VACE-GGUF
===========================================================
1.3B VACE Self-Forcing model used (6 steps only, no CauseVid needed)
https://huggingface.co/lym00/Wan2.1_T2V_1.3B_SelfForcing_VACE/tree/main
*1.3B VACE GGUF fails to give good result
===========================================================
Use https://openmodeldb.info/models/4x-ClearRealityV1 for upscaling
=====================
SWITCH GUIDE
Text to video = all OFF
Image reference to video = Image1 ON
Image to video = Image1 + FLF ON
First & Last Frame to video = Image1+2+FLF ON
FLF video control = Image1+2+VidRef+FLF+control ON
V2V style change = Image1+VidRef+controlnet ON
V2V subject change = Image1+VidRef+control+SAM ON
V2V background change = same as above+invert mask
Switch ON Xtends switches according your needs (monitor progress in the group)
Loopback ON to make looping video