Wan2.2 Another workflow that do NSFW. But now - with custom LORA for each step.

详情
下载文件
模型描述
红色字母:取消所有已绕过的正向提示,以绕过错误。
这里已修复。早就该这么做了。
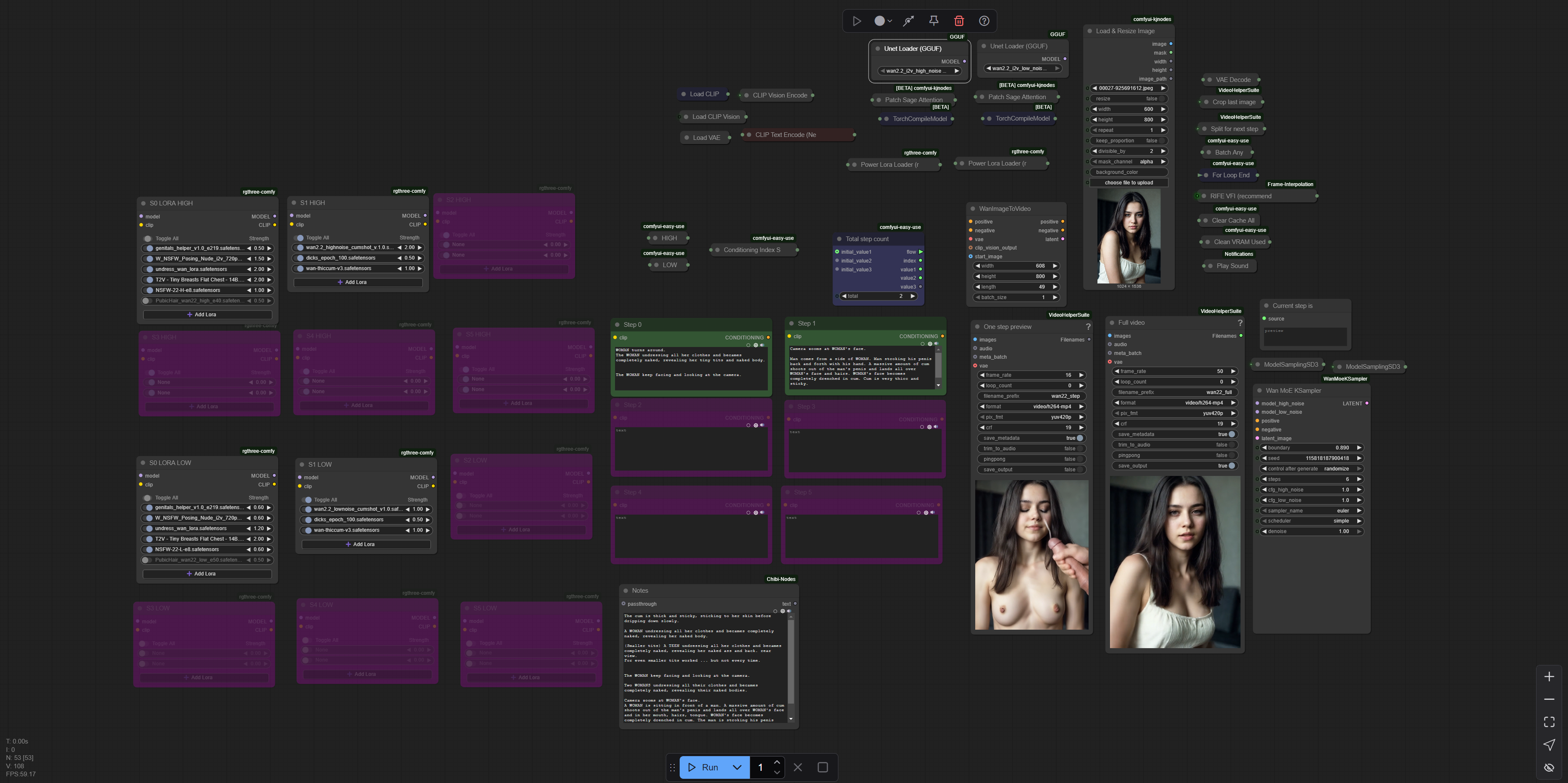
配置:4070TiS 16GB + 64GB DDR5 + i7-14700。所以你可能会问,我为什么发在这里?因为它使用GGUF(你可以选择自己的轻量模型),能生成长视频,并且可以在每一步应用不同的LoRA。就这些。我自己找过类似的东西,但……
注意!采样器是自定义的,放置在ComfyUI-WanMoeKSampler中,必须放入custom_nodes目录(天啊……我真的必须用标准节点做5.1版本吗?.............................................................................................................................................................................................................................. 我原以为你能自己搞定的)。
灵感来源:
/model/1829052?modelVersionId=2070152 —— 我几乎从这里抄了所有内容。
/model/1847579/wan-22-i2v-helper-loras-without-killing-motion-or-lora-action-lightning-22-i2v-pusa-fusionx Kiefstorm:感谢你提供的精准输出,我终于相信这是可能的。
采样器:
和
我为了自己愉悦而修正了它,所以将修正版放进了归档文件,但你可以忽略它,直接使用默认的两个。理论上,高、低分辨率使用不同的ModelSampling会产生不同效果,但据称Boundary的作用更大。我不懂这些,所以我为自己修改了原始的ComfyUI-WanMoeKSampler,以便能安心睡觉(你可以下载原始版本,或像其他人那样只用两个采样器,或者我已在归档中附上截图中的版本,你只需将文件夹“ComfyUI-WanMoeKSampler”复制到custom_nodes即可,原始nodes.py在其中以nodes1.py命名)。剩下的数十亿节点,你自己想办法安装吧。
哦,如果你给它们足够的时间和空间,它们脱衣效果会好很多(我的意思是,把我的测试时长49秒至少延长到97秒)。
注意:在WanImageToVideo节点中选择分辨率,而不是在load&resize中——我只在WanVideoWrapper工作流中看到调整分辨率的好处(WanVideo ImageToVideo Encode节点会把我系统直接抛进太空),我完全不明白为什么它会这样,而同样的WanImageToVideo节点却不会。
感谢这个分叉奇迹:“wan2.2 GGUF Kijai longvideo.json”(也放在归档中,供学习用)。我几乎不记得是从哪儿搞到这个黑暗流程的,但它纯粹在WanVideo节点上运行(而这些节点与普通节点不兼容,就因为某些原因),生成的质量糟糕到甚至导致BSOD,我硬是与之搏斗,才搞明白如何为每一步提示单独提取LoRA。这原本是不可能的,因为开发者不知为何要把WanVideo节点做得和别人不一样。老兄,我们用的是同样的模型,为什么你的节点表现不同?为什么我们连调度器都无法选择(哦对了,你把采样器命名为调度器,而你的“调度器”在wan2.2中的选择简直糟糕透顶)。
我用自己的方式解决了。可能一开始你不太清楚连接关系,但你主要用到的核心节点应该清晰可见——和其他人一样。
兄弟们,我一个月前才刚接触Wan,你们也一定能搞明白。
选择你已有的或想要的量化模型,尝试不同的clip和clip_vision(它们都差不多)。我本无意追求最快的工作流,我想要的是更强的可控性。
现在,你就是自己的导演。
附言:之前半年我都在沉迷Forge和Fooocus生成的图片。两年前我试过你们的Comfy,但觉得太复杂,而且在我的硬件上生成太慢(想象一下,RTX 2070上SD1或SDXL和Flux一样快)。然后几年后,经过Forge、一点点Invoke和Fooocus用于修复,我偶然发现了SwarmUI(感谢StabilityMatrix——只需点两下就能安装),当我安装Swarm时,发现它基本上就是Comfy,我心想:艹。而且它自带现成的工作流,我试了试。后来Wan2.2也出来了。如果你要做视频,我原以为你得拼命努力(或者用CogVideo,但那简直是我见过最烂的东西)。于是我想,每个人都能搞定一切,唯独永远的问题是找不到需要的节点(实际上,你也可以用自己有的节点替换它们)。
选择你想要的LoRA,试试我的或你自己的。至少它能跑起来。至少它可以作为一个不错的起点,只要你理解它是怎么工作的。你也可以自由使用dpmppppmdpdpdpfpdgppgpgpg_2m_sde和sgm_uniform,或者lcm和ddim_uniform(有人在GitHub上说这是他见过最好的东西,但对我和我的分辨率而言,眼睛总是会出故障)。当脸部被衣服遮住或移出画面时,面部一致性无法保证,但我们都明白这个问题(只需提示“女人始终保持面向并注视摄像头”,然后祈祷吧)。最佳效果是:画面从一开始就直视着你。当我看到这个效果时,我差点震惊了。
哦,对了,给那些见证神圣边界的人:720p用0.9,600p用0.89,480p用0.88。别问为什么。也别问为什么HIGH SD3Sampler设为8.5(跟普通值差别不大),而LOV Noise设为4.5。我没法解释,但至少没变得更差——这就够了。但我欢迎对此展开讨论。
我不喜欢用内置方式上采样,因此没有那种廉价塑料感的东西。当然,你可以自行添加。你也可以把分辨率降到480p,也不会更差。但我见过720p的效果,现在我再也无法视而不见。
更新 04:09:我缺乏继续完成我初衷的动力,即至少实现身体一致性(如果有人脱衣服,脱完后比例必须保持一致),所以谨慎地为每个不同内容使用LoRA是种办法,我在这里提供了这些,但要找到真正有效、通用的LoRA非常困难(要么破坏身体一致性,更别提面部,要么每个种子生成结果都一样,比如“口腔插入”LoRA)。
我最终停在了首尾帧,因为这样更可预测。我正在等待真正的Wan2.2 vace(是的,我试过用fakewan或test_wan运行WanVideo工作流,但不知为何对我而言效果极差)。我检查过一些超级复杂的大型工作流(比如火箭飞船,需要重做整个venv,用一堆一次性节点),它们都需要H100,但全都依赖WanVideo节点(这就是为什么需要H100),结果却根本不值得——所以我不太喜欢WanVideo节点(没错,也没有调度器选项)。
我修复了这个工作流版本的几个问题,添加了更好的LoRA,甚至自己编写了节点,但从未发布。因为没有令人感兴趣的例子。我其实不想发布NSFW内容,但我所有测试都是NSFW。想象力和动力都枯竭了。