NcProductions Wan2.2 All-In-One I2V-T2V A14B Workflow

詳細
ファイルをダウンロード
モデル説明
NcProductions Wan2.2 オールインワン I2V-T2V-T2I A14B ワークフロー
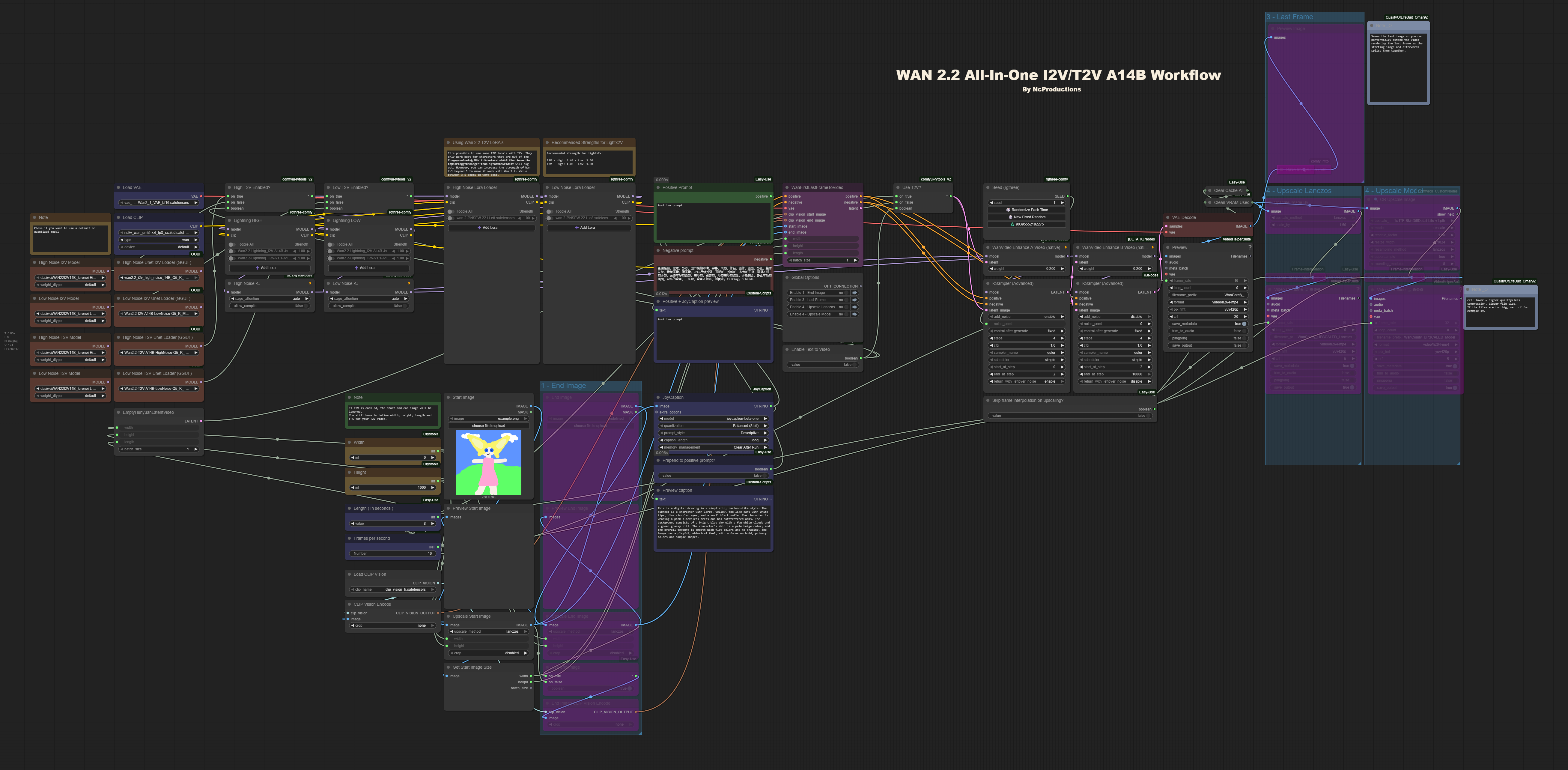
これは、Wan 2.2 を使用して動画を作成するために私が使用しているワークフローです。スイッチを切り替えるだけで T2V と I2V の両方をサポートしており、ワークフローを変更せずに I2V と T2V を切り替える際に便利です。
このワークフローでは、I2V と T2V の量子化モデル(GGUF)を使用しています。
アップスケーリングのフローは、以前 Wan 2.1 で使用していた _Astraali\_accWAN\_GGUF_ のワークフローから借用しました。
更新 V. 1.2
T2I を削除
- T2I には、専用に作られた別のワークフローを使用するのが最適です。
Florence を削除
- Florence は、NSFW 用に優れた I2T である Joycaption Beta One に置き換えられました。
ディフュージョンモデルの読み込みノードを追加
モデルを通常のディフュージョンモデルとして、または量子化モデルとして読み込むを選択できます。ただし、正しいノードが 「High T2V Enabled?」 および 「Low T2V Enabled?」 ノードに接続されていることを確認してください。
私はワークフローで DaSiWa WAN 2.2 I2V 14B Lightspeed を使用しています。
Lightning LoRA がメインの LoRA ノードセレクターから分離されました
更新 V. 1.1
T2I オプションを追加
- 「テキストから画像を有効にする」 スイッチは、「テキストから動画を有効にする」 スイッチの下にあります。このオプションは 「テキストから動画を有効にする」 と同時に有効にする必要があります。これにより、Wan 2.2 が画像を生成します。プレビュー画像を保存するには、画像を右クリックして 「画像を保存」 を選択してください。
T2V の潜在的な問題を修正
- 以前は、T2V がアップロードした画像の幅と高さをそのまま使用していました。この問題は修正され、今後は定義した寸法が正しく適用されるようになりました。
入力の前に Florence の入力を有効にするオプションを追加
- ポジティブプロンプトの上部に新しいスイッチを追加し、カスタムポジティブ入力の前に Florence の入力を有効にできます。これは、I2V でフレーム外の登場を実現するために T2V 文字 LoRA を使用する際に役立ちます。
機能
同じワークフローで I2V / T2V
- 前述の通り、簡単なスイッチで両者を容易に切り替えられます。
スタート画像と最終フレーム
- I2V でのみ利用可能。動画の開始と終了画像を設定できます。
Florence
- I2V でのみ利用可能。AI が画像を説明し、その説明文がカスタムポジティブプロンプトの前または後に連結されます。
最終フレーム
- 生成された動画の最終フレームを画像として保存し、必要に応じて動画を拡張できます。
動画のアップスケーリング
Lanczos
基本的な Lanczos アップスケーリングを実行します。幅と高さは 1.5 倍になります。カスタムモデル
Lanczos の代わりにカスタムアップスケーリングモデルを使用します。希望すれば独自のモデルを選択できます。このワークフローでは 1x-ITF-SkinDiffDetail-Lite-v1.pth を使用しています。幅と高さは 1.5 倍になります。
インストール
インストール前に、最新版の ComfyUI がインストールされていることを確認してください:
ComfyUI: v0.3.51-1-gfe01885a (2025-08-20)、Manager: V3.36(このワークフローをアップロード時点)。
次に、「NcProductions Wan2.2 All-In-One I2V-T2V A14B Workflow.json」 を実行中の ComfyUI インスタンスにドラッグしてください。必要に応じて不足しているノードをインストールし、リフレッシュしてください。すべてが正しく設定されていれば、すべてのカスタムノードが使用可能になります。
GPU に適した I2V および T2V の量子化モデルを使用してください。たとえば、私は RTX 5080 を使用しているため、Q5_K_M をインストールしています。また、対応する量子化 CLIP モデルも使用していることを確認してください。
(例:私の場合、umt5-xxl-encoder-Q5_K_M.gguf)
量子化モデルへのリンク:
I2V - https://huggingface.co/QuantStack/Wan2.2-I2V-A14B-GGUF/tree/main
T2V - https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main
これらのモデルは ComfyUI ディレクトリの models/unet フォルダに配置してください。
量子化 CLIP モデルへのリンク:https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main で、models/clip フォルダに配置してください。
使用方法
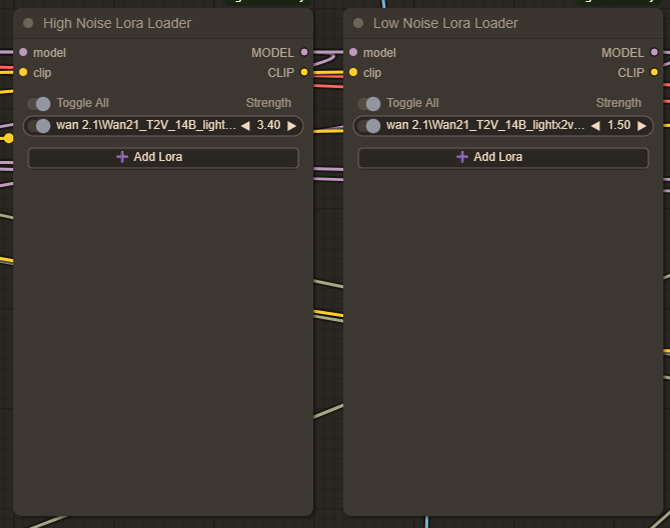
まず、高ノイズと低ノイズの LoRA を用意する必要があります。現在、私は LoRA フォルダに Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors をインストールしています。この LoRA は生成プロセスを高速化し、最初に選択すべきです。
私が使用している lightx2v の推奨強度:
I2V
高:3.40
低:1.50
T2V
高:1.00
低:1.00
このワークフローでは、I2V と T2V ともに同じ高・低ノイズ LoRA ノードを使用します。
アップデート:
Wan 2.2 用の Lightning LoRA が登場しました。I2V および T2V 用の対応する LoRA をダウンロードして使用できます - /model/1585622/self-forcing-causvid-accvid-lora-massive-speed-up-for-wan21-made-by-kijai?modelVersionId=2090344
グローバルオプション
次に グローバルオプション です。これらはオン/オフのスイッチで、ワークフローで有効にする機能を選択できます。利用可能なオプションは、I2V または T2V の使用状況によって異なります。各オプションの詳細は、以下の説明で説明しています。
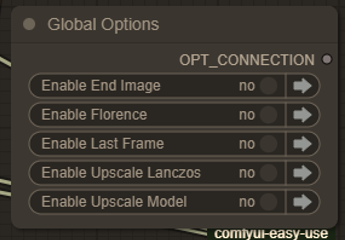
I2V - T2V の切り替え
T2V を有効にするには、このノード(グローバルオプションの下)をオンにします。T2V が有効になると、スタート画像、エンド画像、Florence のオプションは無視され、バイパスされます。
T2I の有効化
T2I を有効にするときは、T2V も同時に有効にしてください。そうでないと、アップロードした画像のコピーが得られるだけです。
T2I では、T2I が有効でない場合(長さや FPS を 1 または 0 に設定しても)には不可能な、高解像度画像(例:2560x1440px)の生成が可能です。
この機能は、T2V を使用する前に素早くドラフトを作成する際にも役立ち、フル動画を生成する前にプロンプトを迅速にテストできます。
動画コンポジション設定
T2V: 動画の 幅 と 高さ を定義します。
I2V: 幅 または 高さ を
0のままにできます。これにより、アップロードした画像がアスペクト比を維持したままスケーリングされます。長さと FPS: ほぼ説明不要ですが、必要に応じて再定義できます。アップスケール(Lanczos) または アップスケール(モデル) が有効な場合、FPS は初期設定値の 2 倍になります。たとえば、
16 × 2 = 32 FPSになります。

スタート画像とエンド画像
I2V のみ: I2V ワークフロー用に スタート画像 をアップロードします。
グローバルオプションから エンド画像 オプションを有効にすることで、I2V ワークフローで エンド画像 を使用できます。

シード
このワークフローでは RGTHREE シードジェネレータ を使用しています。このカスタムノードにすでに慣れている場合は、このセクションをスキップしてください。
慣れていない場合は、このノードは各生成ごとの シード番号 を管理します:
シード値
-1は、生成を実行するたびにシードをランダムに変更します。現在のシード値 は下部のフィールドに表示されます。
同じシードを使用するには、下部のフィールドをクリックして 固定シード値 を設定してください。