Qwen-image-edit nf4 workflow (4-8steps, 16GB VRAM compatible)

세부 정보
파일 다운로드 (1)
모델 설명
This workflow uses the latest bnb 4-bit model loading plugin to load the qwen-image quantization model in bnb nf4 format.
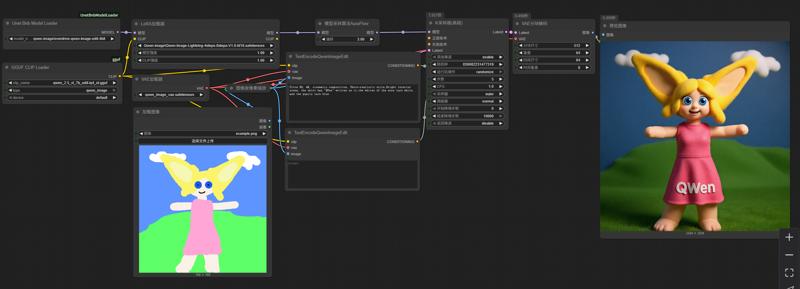
You may install the missing plugin directly in ComfyUI Manager plugin management system or search "Unet Bnb Model Loader" to find and install it. Of course, you can also install it manually.
Model used: https://huggingface.co/ovedrive/qwen-image-edit-4bit
Note that this is a sharded model, but you don't need to manually merge the shards together. Simply place them in a directory, such as qwen-image-edit-4bit, and then place that directory in the unet directory. The plugin will recognize and load the sharded model. In the drop-down menu, the sharded model will be displayed according to the directory it is in.
Use the following LoRa-accelerated generation: PJMixers-Images/lightx2v_Qwen-Image-Lightning-4step-8step-Merge · Hugging Face
Use the following text_encoder (requires the GGUF plugin): https://huggingface.co/calcuis/pig-encoder/resolve/main/qwen_2.5_vl_7b_edit-iq4_nl.gguf?download=true
We strongly recommend using the qwen_2.5_vl_7b_edit series of ggufs from Pig as the text_encoder for qwen-image-edit. This successfully incorporates the mmproj model into the text encoder, ensuring that the general gguf clip loader can load it successfully without encountering tensor mismatch issues. Otherwise, you will need to use the larger fp8 model.
The entire image generation process is about twice as fast as using the GGUF model, and the results are similar to GGUF Q4. Peak memory usage is around 14GB, but can be maintained at around 14GB when repeatedly generating images.
The image generation speed is about 1 it/s, and the recommended number of steps is 5-6. Due to its reliance on the BitsAndBytes library, this workflow does not support graphics cards other than NVIDIA.